前天我遇见了小兔,昨天遇见了小鹿,今天则遇见了你。
深度卷积神经网络(AlexNet)
ImageNet数据集
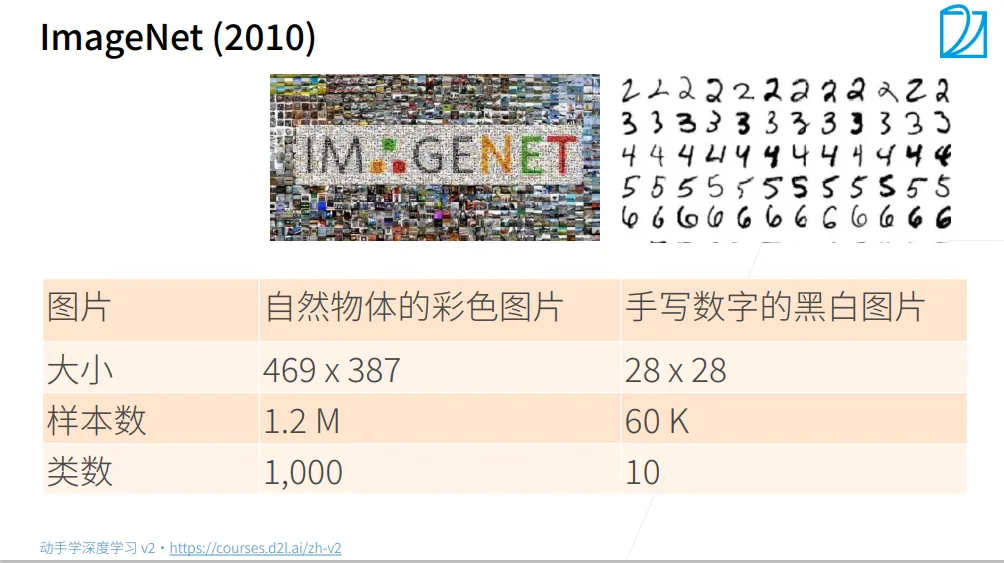
在深入学习神经网络的过程中,ImageNet会被反复提及,它的核心贡献在于:
- 引爆了深度学习热潮:2012年在基于ImageNet数据集举办的ILSVRC(大规模视觉识别挑战赛)中,AlexNet架构利用GPU算例成功训练了深层CNN,以压倒性的优势夺冠,直接证明了深度学习在复杂视觉任务中的统治力。
- 迁移学习:因为ImageNet数据量庞大、特征涵盖极广,后来衍生的经典模型(如VGG、ResNet等)通常都会现在ImageNet上进行预训练(Pre-training),提取出通用的视觉特征表示。之后只需要进行简单的微调,就可以将这些模型广泛应用于目标检测、图像分割或其他小数据集的分类任务中。
计算机视觉方法论的改变
人工特征提取 + SVM
阶段一:人工特征提取
- 在传统方法中,算法不能直接看懂 原始像素矩阵,因为像素包含的信息太杂乱(容易收到光照、阴影、视觉变化影响)。因此需要计算机视觉专家通过数学和图像处理知识,手动设计算法来提取图像中最有用的信息,将其变成一组特征向量。
阶段二:传统机器学习分类器
- 特征提取完毕后,原始图片就被浓缩成了一串数字(特征向量)。接下来这串数字会被送到分类器中进行判断。支持向量机(SVM)是当时最受欢迎、数学理论最完备的分类器之一。
缺点:特征工程及其耗时、极度依赖领域专家的经验,而且人工设计的特征往往泛化能力差,很难应对真实世界中极其复杂的图像变化。
深度学习方法
AlexNet证明了:我们可以直接把原始图像扔进一个深层的卷积神经网络CNN中。
网络底层的卷积核会自动学习提取边缘、纹理等底层特征,高层会组合出猫耳朵、猫眼睛等高层语义特征。整个特征提取的过程交给了机器通过海量数据去自动学习。
最后接一个Softmax回归输出各类别的概率。这种端到端的数据驱动方式,彻底降维打击了传统的人工特征工程。
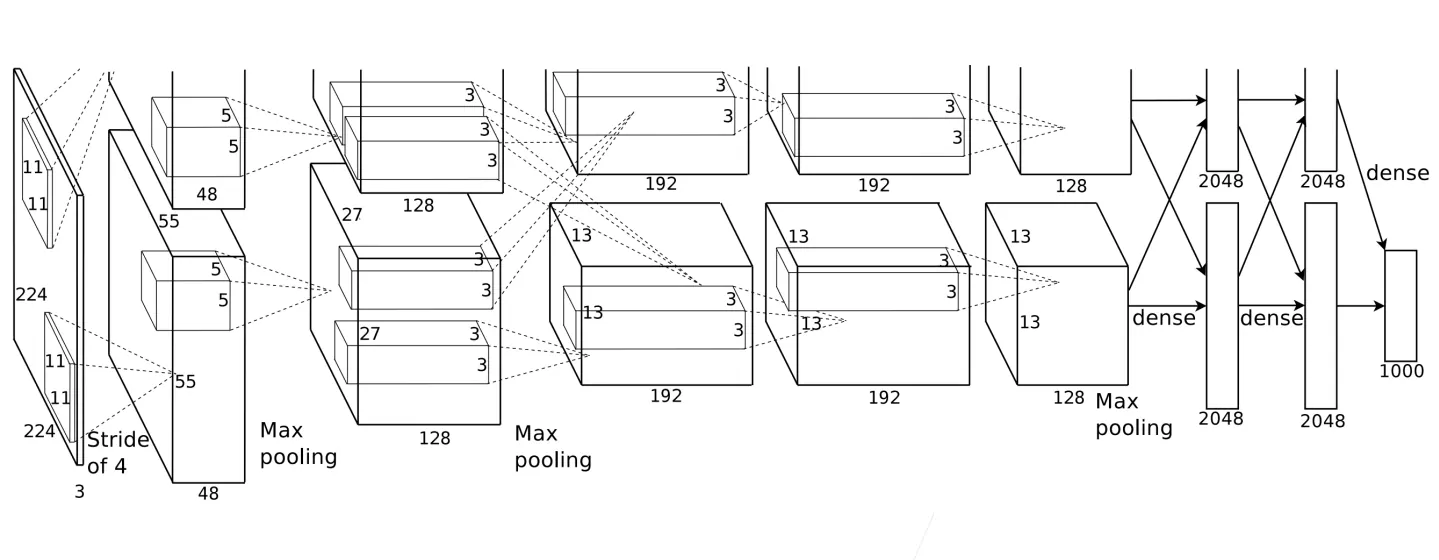
AlexNet架构
模型设计
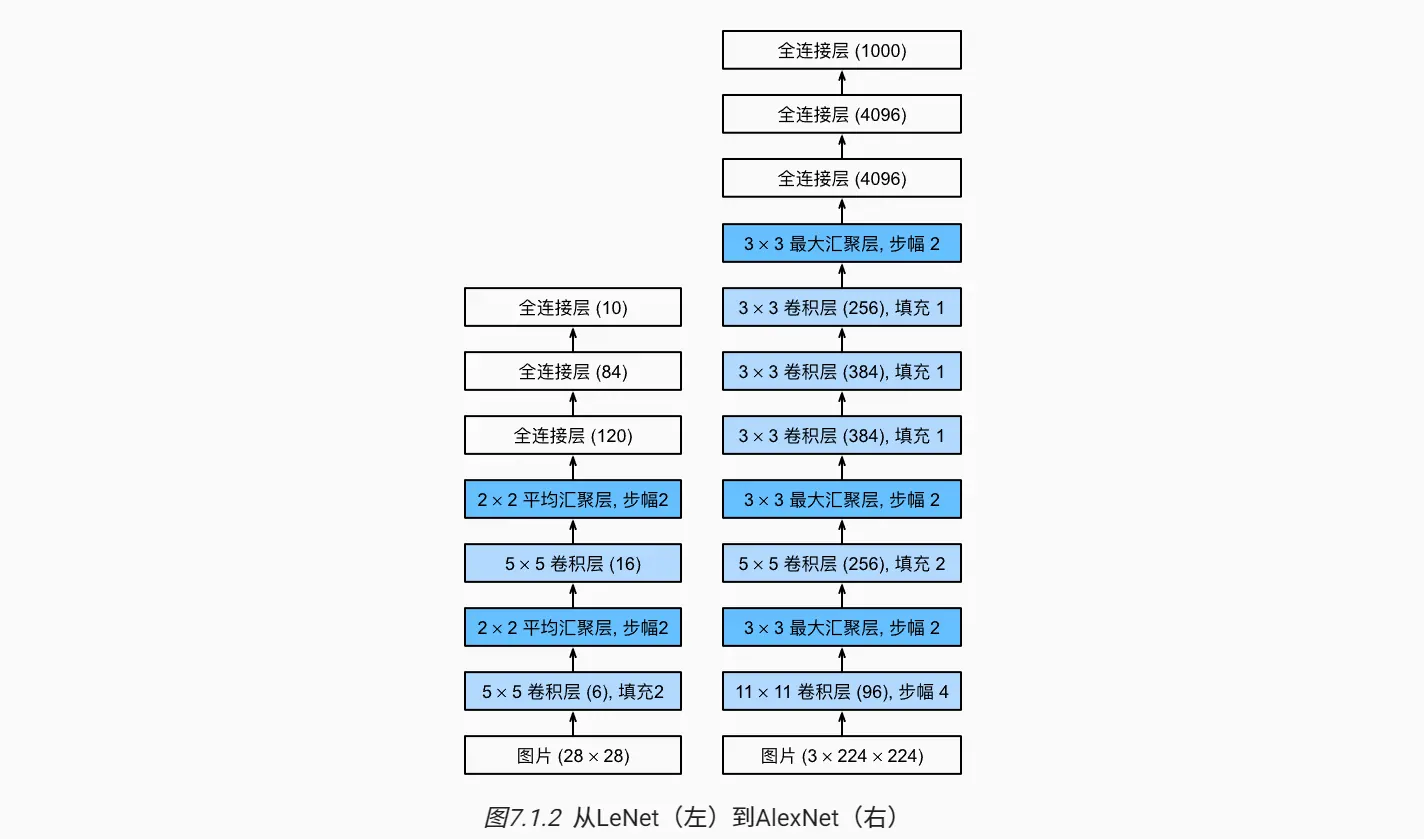
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
- AlexNet比相对较小的LeNet5要深的多。AlexNet由八层组成:5个卷积层、2个全连接层隐藏层和1个全连接输出层。
- AlexNet使用ReLU而不是sigmoid作为其激活函数。
在AlexNet的第一层,卷积窗口的形状是11 x 11。由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。第二层中的卷积窗口形状倍缩减为5 x 5,然后是 3 x 3。此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为3 x 3、步幅为2的最大汇聚层。而且,AlexNet的卷积通道数目是LeNet的10倍。
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。另一方面,当使用不同的参数初始化方法时,ReLU激活函数使得训练模型更加容易。当sigmoid激活函数的输出非常接近等于0时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。相反,ReLU激活函数在正向区间的梯度总是1。因此如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使得模型无法得到有效的训练。
代码实现
借助框架,我们可以很简单的定义AlexNet:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))