在过去几年里,深度学习给世界带来惊喜,推动了计算机视觉、自然语言处理、自动语音识别、强化学习和统计建模等领域的快速发展。
感知机
给定输入x,权重w,和偏移b,感知机输出:
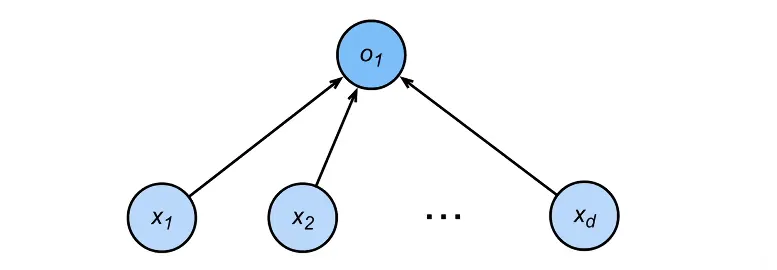
这是一个二分类的问题:输出1/-1
- 回归问题:输出一个实数;而二分类问题输出一个类别
- Softmax回归:多分类问题,输出概率
感知机的训练算法
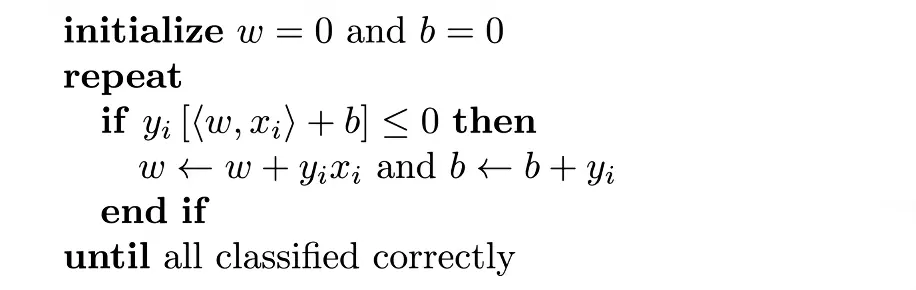
初始化:将权重向量和偏置都初始化为0。
循环:算法会不断循环遍历训练数据,直到所有的样本都被正确的分类。
判断错误分类:
- 这里的是真实的标签(为+1或-1)
- 是模型对样本的预测输出值
- 含义:如果和预测值的符号相反(乘积为负),或者预测值为0,说明分类错误。
更新规则:
- 含义:当发现一个错误样本时,利用该样本的信息来调整权重。
- 如果是正样本()被误判为负,就加上(让向的方向靠近)
- 如果是负样本()被误判为正,就减去(让远离)
更新规则的数学逻辑:
感知机的预测完全取决于内积 的正负(为了简化,我们先忽略偏置 )。
当 (正样本)被误判:此时目前的 。我们希望这个值 变大 (最好变成正数)。如果我们更新 ,那么新的内积为:
因为 永远是正数,所以更新后的内积 一定会增加 。这让该样本在下次预测时更趋向于被判定为正。
当 (负样本)被误判:此时目前的 。我们希望这个值变小(最好变成负数)。如果我们更新 ,新的内积为:
内积一定会减小,从而让该样本更趋向于被判定为负。
优化视角解释
以上的感知机训练算法,等价于使用批量大小为1的梯度下降,并使用如下的损失函数:
理解这个公式:
- 如果分类正确:,那么 ,经过 后损失为 0 。此时梯度为 0,参数 不更新 。
- 如果分类错误: ,那么 ,损失为正。
更新规则:当分类错误时,损失函数对 求导(梯度)是 。
代入 SGD 更新公式(假设学习率为 1):
感知机收敛定理
- 数据半径 :假设所有的输入数据 都分布在一个半径为 的圆(或高维球体)内。即数据的大小(范数)是有界的。
- 余量 (Margin) :这代表了正负两类样本之间“最宽”的那条缝隙。
感知机的步数上限:
感知机的问题
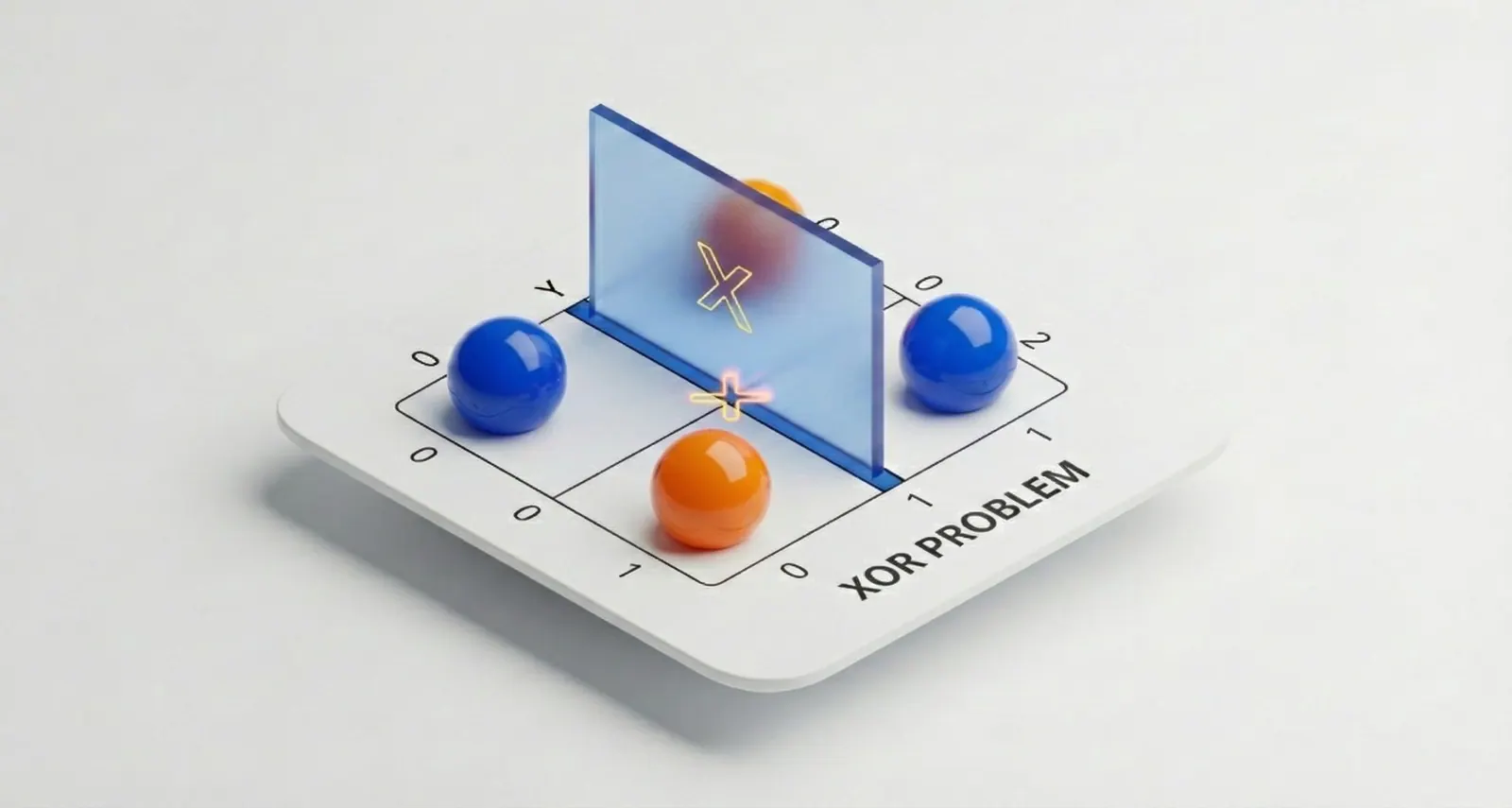
感知机不能拟合XOR函数,它只能产生线性分割面。导致了第一次AI的寒冬。
XOR问题:无法使用一条直线,将两种颜色的球完全分开。
多层感知机
上面我们提到单层感知机模型无法解决非线性问题,而引入隐藏层可以解决这一问题。
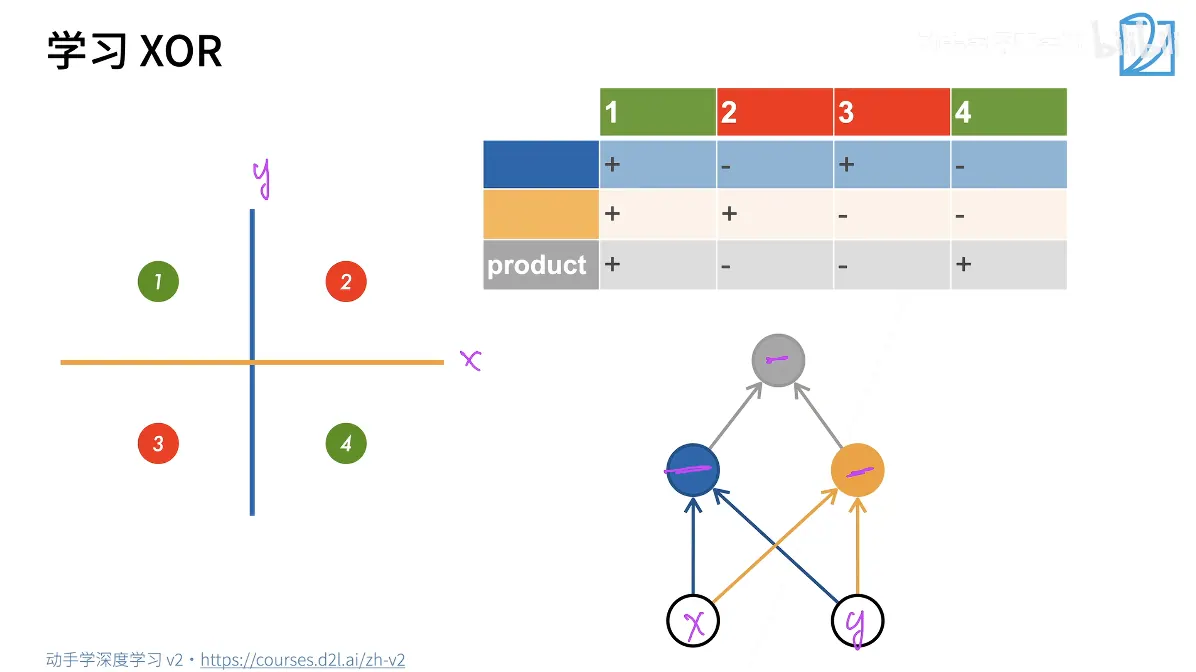
在这个问题中,隐藏层相当于两条辅助线,这就好比我们在做特征工程,我们将原始复杂的分类任务拆解成了两个简单的子任务:
- 蓝色特征:
- 网络学会的第一条规则是区分左右(即x轴的符号)
- 左边为 + ,右边为 - ,这对应图中的蓝色竖线
- 黄色特征:
- 网络学会的第二条规则是区分上下(即y轴的符号)
- 上边为 + , 下边为 - ,这对应了图中的黄色横线。
现在,我们有了两个新的特征(蓝色和黄色)。神经网络的输出层(Output Layer)所做的工作,就是将这两个特征进行 非线性组合 (在这里可以理解为乘法或异或逻辑):
对应到神经网络架构,这就是一个最简单的多层感知机(MLP):
- 输入层(x, y):也就是原始数据的坐标。
- 隐藏层:这里有两个神经元:
- 一个负责学习蓝色规则
- 一个负责学习黄色规则
- 输出层:接收隐藏层信号,完整最终的逻辑判断
单隐藏层
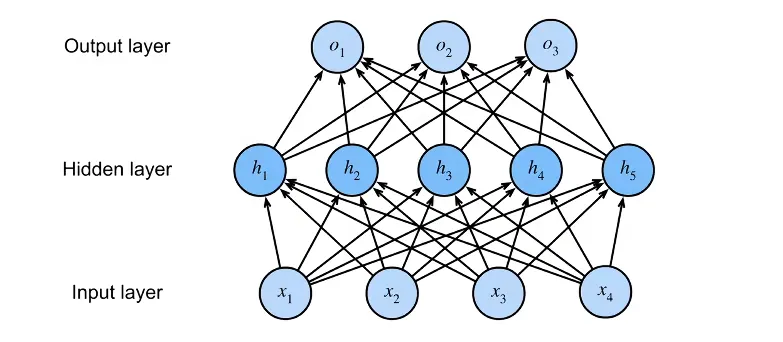
- 隐藏层的大小是一个超参数。
输入输出的大小都是由数据和类别决定的。
单分类
核心组件
单分类指输出为一个标量的情况。
输入层:
- :代表输入是一个n维向量。
隐藏层:
- :这是第一层的权重矩阵。它将n维输入映射到m维空间。
- :偏置项,对应隐藏层的m个神经元。
输出层:
- :单输出的情况,是一个一维向量。
数学表达式
- 隐藏层计算:
- 这里先进行线性变换
- (激活函数):按元素做运算的函数。后续细讲。
- 输出层计算:
- 这是将隐藏层提取到的特征h进行加权求和,得到最终的预测值。
激活函数 Activation function
激活函数通过计算加权和并加上偏置来确定神经元是否应该被激活,它们将输入信号转换为输出的可微运算。大多数激活函数都是非线性的。 由于激活函数是深度学习的基础。
为什么需要激活函数
简单来说,如果没有激活函数,再深的网络也只是一层。
假设我们有一个两层的神经网络,但没有激活函数。
- 第一层输出:
- 第二层输出:
我们将第一层代入第二层:
如果我们令 且 ,那么公式就变成了:
结论: 无论你堆叠多少层,只要是线性的,它们最终都可以合并成一个单一的线性层。这意味着你的“深度”网络在表达能力上和最简单的感知机没有任何区别,无法处理复杂的任务。
激活函数的作用:它像一个”开关”或”过滤器”,决定了神经元的哪些信息应该传递到下一层。它引入了非线性,让网络能够拟合出复杂的边界。
- 万能近似定理:只要神经网络拥有至少一个包含足够多神经元的隐藏层,并配合非线性激活函数,它就可以以任意精度拟合闭区间内的连续函数。
常见的激活函数
ReLU函数
修正线性单元(Rectified linear unit, ReLU),这是最受欢迎的激活函数。
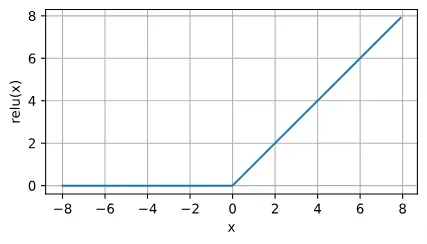
ReLU导数的图像:
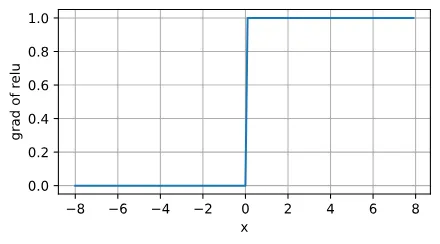
注意:当输入值精确等于0时,ReLU函数不可导。在此时,我们默认使用左侧的导数。我们可以忽略这种情况,因为输入可能永远都不会是0。 这里引用一句古老的谚语,“如果微妙的边界条件很重要,我们很可能是在研究数学而非工程”, 这个观点正好适用于这里。
优点:
- 实现简单。
- 无需计算指数,计算速度快。
- 求导表现好
sigmoid函数
sigmoid函数将输入变换为区间(0, 1)上的输出。
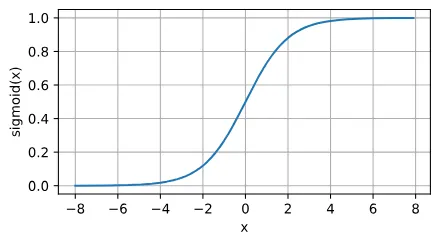
sigmoid函数的导数:
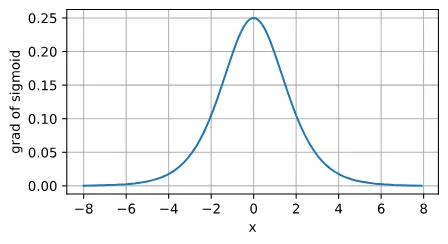
针对梯度下降的学习时,sigmoid是一个自然的选择,因为他是一个平滑的、可微的阈值单元近似。然而,sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代。
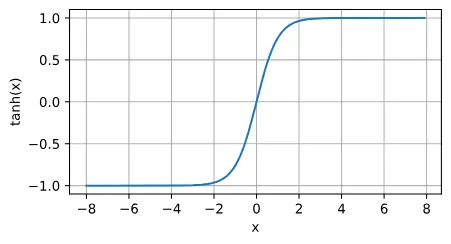
tanh函数
与sigmoid函数类似, tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。 tanh函数的公式如下:
tanh函数的导数:
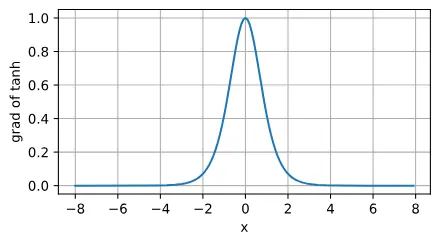
tanh函数和sigmoid函数计算都比较复杂,在深度学习中算力是宝贵的资源,所以一般情况下都选择使用ReLU函数。
多类分类
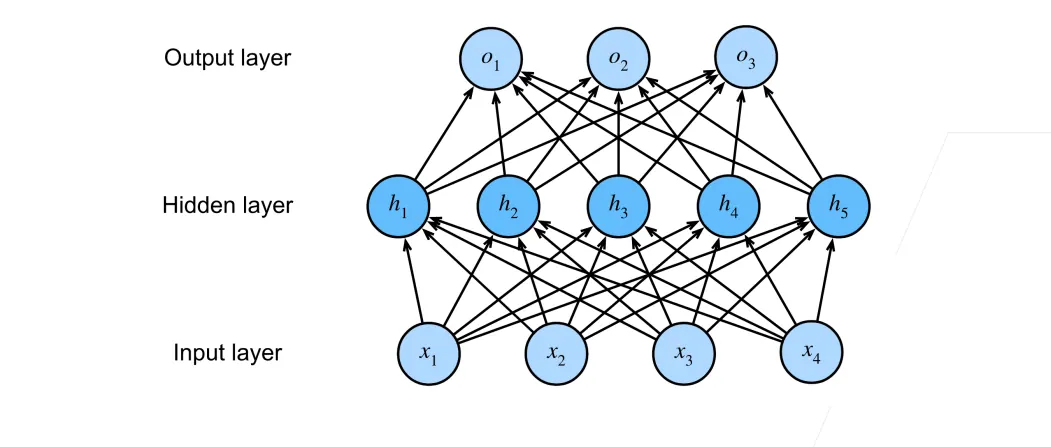
输入层:
隐藏层:
输出层:
这里不再是一个向量,而是一个矩阵。它把m维的隐藏特征映射到k个类别的评分上。
计算公式:
- 隐藏层激活:
- 输出层线性变换:
- 最终输出:
多类分类与softmax回归没有本质区别,只是增加了隐藏层。
多隐藏层
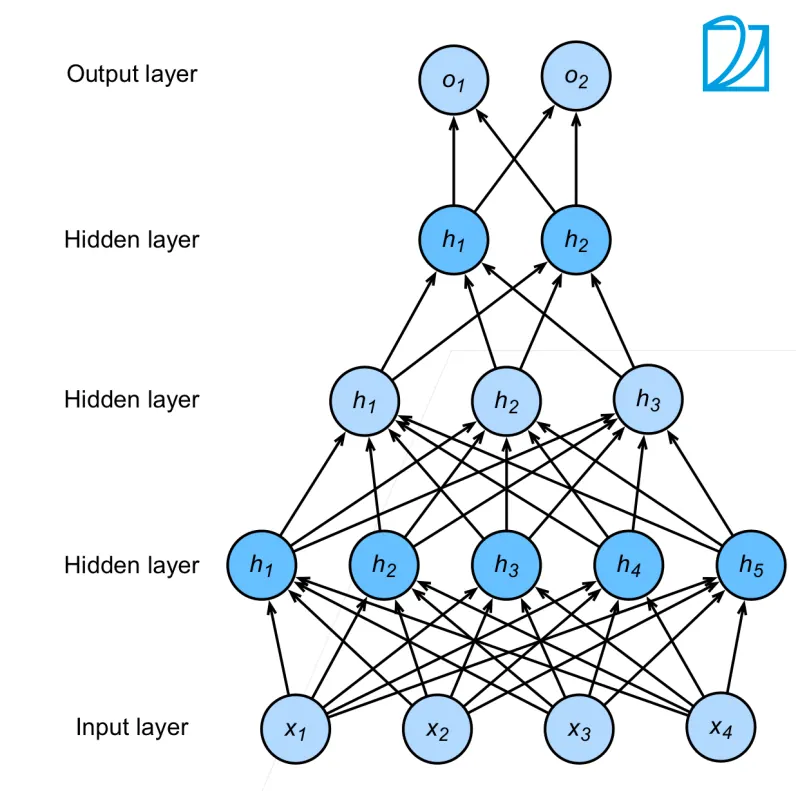
计算公式:
针对多层感知机,我们需要设计其中的超参数:
- 隐藏层数
- 每层隐藏层的大小
多层感知机的从零开始实现
我们使用softmax中相同的数据集进行训练——Fashion-MNIST。
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 直接使用d2l保中现成的导入函数
# 让我们现在可以先把注意力放在模型训练上初始化模型参数
我们将要实现一个单隐藏层的多层感知机,它包含256个隐藏单元。
隐藏层的数量和宽度都是超参数。通常我们选择2的幂次作为层的宽度,因为内存硬件中分配和寻址方式,这么做可以在计算上更高效。
我们用几个张量来表示我们的参数。
每一层都要记录一个权重矩阵和偏置向量。
# 定义网络架构的维度:输入特征784、输出类别10、隐藏层单元 256
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# 初始化第一层的权重矩阵 W1
# 形状为(784, 256)
# 使用均值为0、标准差为1的随机正态分布,并乘以0.01。等价于(0, 0.01)的正太分布
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
# 初始化第一层的偏置项b1
# 形状为隐藏层维度,初始值全部设为0
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
# 初始化第二层(输出层)的权重矩阵W2
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
# 初始化第三层的偏置项b2
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
# 将所有需要反向传播更新的参数封装进一个列表
params = [W1, b1, W2, b2]激活函数
def relu(X):
# 创建一个与输入张量X形状(shape)和类型完全相同、但元素全部为0的新张量
# 这一步是为了后续进行逐元素的对比
a = torch.zeros_like(X)
# 比较X和a中的每一个对应位置的数值,返回其中较大的那个
# 数学表达式:ReLU(x) = max(0, x)
return torch.max(X, a)模型
因为我们忽略了空间结构,所以我们使用 reshape将每个二维图像转化为一个长度为 num_inputs的向量。只需要几行代码就可以实现模型:
def net(X):
# 将输入X展平为二维向量
X = X.reshape((-1, num_inputs))
# 计算隐藏层输出:
# 1. X @ W1: 输入与第一层权重进行矩阵乘法
# 2. + b1: 加上第一层的偏置项
# 3. relu(...): 对计算结果应用ReLU激活函数,引入非线性
H = relu(X @ W1 + b1) # 这里“@”代表矩阵乘法
# 计算输出层的预测值:
return (H @ W2 + b2)损失函数
这里的损失函数与softmax中的完全一样,我们直接使用高级API来简化:
loss = nn.CrossEntropyLoss(reduction='none')训练
多层感知机的训练过程与softmax回归的训练过程完全相同:
def updater(batch_size):
return d2l.sgd(params, lr, batch_size)
num_epochs, lr = 10, 0.1
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)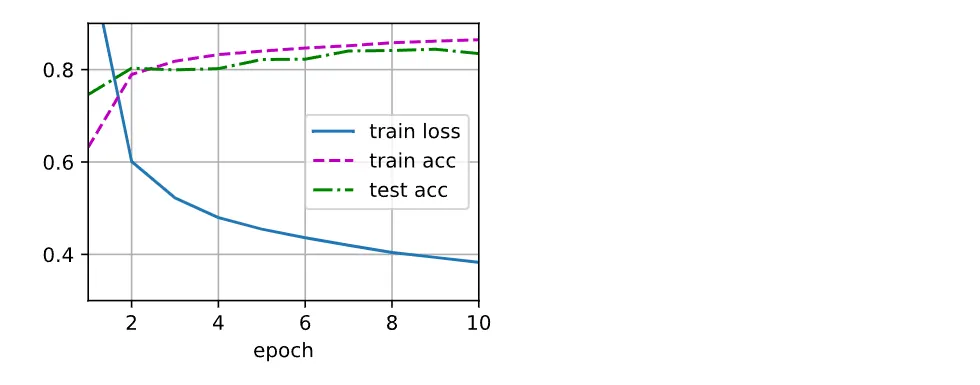
多层感知机的简洁实现
首先导入包:
import torch
from torch import nn
from d2l import torch as d2l模型
与softmax回归的简洁实现相比,唯一的区别是我们添加了两个全连接层(之前我们只添加了一个全连接层)。
# 使用Sequential 容器按顺序堆叠各个层
net = nn.Sequential(
# 将输入的四维图像张量,展平为二维张量
nn.Flatten(),
# 定义第一个全连接层: 输入784维,输出256维
nn.Linear(784, 256),
# 添加ReLU激活函数,为模型引入非线性,必须放在两个全连接层之间
nn.ReLU(),
# 定义第二个全连接层(输出层)
nn.Linear(256, 10))
# 定义一个初始化权重的函数
def init_weights(m):
# 检查当前层m是否为全连接层(nn.Linear)
if type(m) == nn.Linear:
# 使用正太分布(0, 0.01)初始化该层的权重矩阵
nn.init.normal_(m.weight, std=0.01)
# 将init_weights 函数递归地应用到net的每一个子模型(即Sequential里的每一层)上
# 对于不是nn.Linear 的层,if判断不成立,直接跳过
net.apply(init_weights);训练过程的实现与我们实现softmax回归时完全相同, 这种模块化设计使我们能够将与模型架构有关的内容独立出来。
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)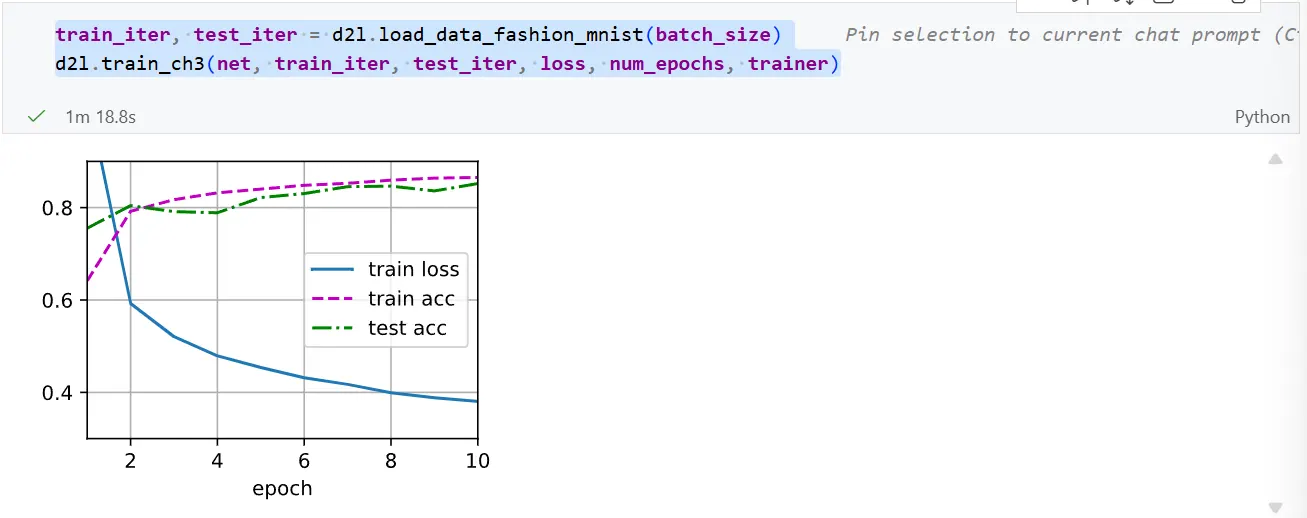
模型选择
训练误差和泛化误差
- 训练误差:模型在训练数据上的误差
- 泛化误差:模型在新数据上的误差
- 例子:根据模考成绩来预测未来考试分数
- 在过去的考试中表现很好(训练误差)不代表未来考试一定会好
- 学生A 通过背书在模考中拿到很好的成绩
- 学生B 知道答案后面的原因
验证数据集和测试数据集
-
验证数据集:一个用来评估模型好坏的数据集
- 本质作用:帮助模型做选择 。它虽然不直接参与梯度下降(即不直接更新权重),但它间接参与了训练过程。
- 如何影响:我们根据验证集上的表现来调整超参数(比如学习率、层数、Dropout比例)或者决定何时停止训练(Early Stopping)。
- 潜台词:模型其实是“看”过验证集的,我们的训练策略针对它进行了优化。
-
测试数据集:只用一次的数据集。
- 本质作用 : 无偏估计真实能力 。它是用来模拟模型上线后在真实世界中会遇到的未知数据。
- 如何影响 : 完全不影响 。它绝不能参与任何参数更新或模型选择的决策。
- 潜台词 :模型在看到测试集之前,必须已经完全定型(冻结参数)。
如果把训练模型比作学生备考:
- 训练集 :是 课后作业 。学生(模型)通过做题来学习知识点,做错了就改(更新参数)。
- 验证集 :是 模拟考试 。
- 考完后,老师会根据成绩告诉你:“你这次复习策略不对,要调整一下重点”(调整超参数)。
- 你可以考很多次模拟考,不断调整学习方法,直到模拟考成绩满意为止。
- 测试集 :是 真正的高考(或未来的考试) 。
- PPT里提到的“只用一次”就是这个意思。
- 你不能考了一半觉得分低,就要求老师把试卷拿回去让你重新复习再考一遍。它的结果就是你的最终能力体现。
K-则交叉验证
在没有足够多的数据时使用。
算法:
- 将训练数据分割成K块
- For i = 1, …, K
- 使用第i块作为验证数据集,其余的作为训练数据集
- 报告K个验证集误差的平均
常用:K = 5或10
过拟合和欠拟合

模型的容量
定义:模型拟合各种函数的能力
- 低容量的模型难以拟合训练数据
- 高容量的模型可以记住所有的训练数据
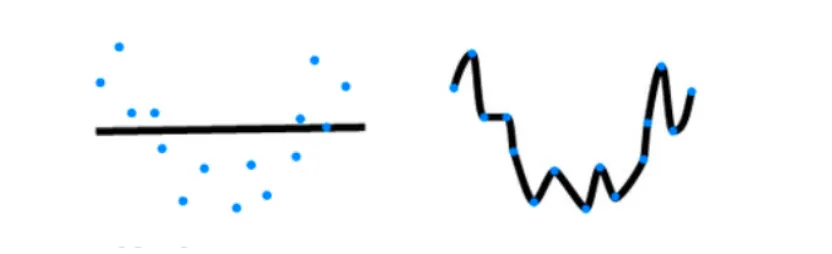
模型容量的影响
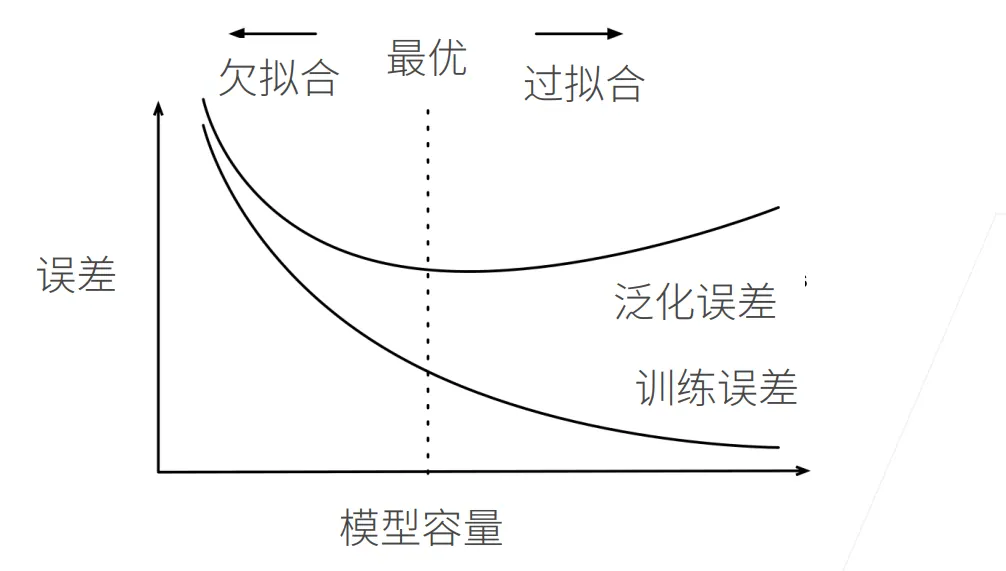
- 如果模型容量很低:欠拟合
- 训练误差高
- 泛化误差高
- 训练误差和泛化误差只有一点差距
- 如果模型容量过大:过拟合
- 训练误差很低
- 泛化误差很高
- 训练误差明显低于泛化误差
过拟合并不一定是一件坏事,当我们的泛化误差在最小值时,或许已经出现一定程度上的过拟合,最终我们往往更关心泛化误差,而不是训练误差和泛化误差之间的差距。
估计模型容量
给定一个模型种类,影响模型大小的有两个主要因素:
- 参数的个数:模型里的参数(权重和偏置)越多,它能记住和拟合的数据模式就越复杂,模型容量就越大。
- 参数值的选择范围:即使两个网络结构的参数个数一模一样,如果其中一个网络的参数只能在 之间取值,而另一个可以在任意实数范围内取值,后者的模型容量就会更大。
VC维
VC维是衡量一个机器学习模型容量(或复杂度)的数学指标。它在理论上定义了一个模型到底有多大的”表达能力”。
定义:对于一个分类模型,VC维等于一个最大的数据集的大小,不管如何给定标号,都存在一个模型来对它进行完美的分类。
一个模型能够完美的记住一个数据集,这个数据集最大有多大。
二维输入的感知机,VC维 = 3
- 一个线性模型最多可以完美分类3个点,而不是4个。

支持N维输入的感知机的VC维是N+1
一些多层感知机的VC维
VC维的用处
提供一个模型好的理论依据,它可以衡量训练误差和泛化误差之间的间隔
但深度学习中很少使用:
- 衡量不是很准确
- 计算深度学习模型的VC维很困难
数据复杂度
影响数据复杂度的因素:
- 样本个数
- 每个样本的元素个数
- 时间、空间结构
- 多样性
权重衰退
权重衰退是最常见的一种用于处理过拟合的方法。
使用均方范数作为硬性限制
我们可以如何控制我们模型的容量呢?
- 减小模型的大小,即减少模型的参数
- 缩小每个参数值的范围
权重衰退就是通过控制每个参数值的大小,来限制模型的容量,进而达到防止过拟合的效果。
我们在最小化损失函数的同时,加入了一个限制:,使得权重向量的L2范数平方不能超过某个阈值θ。
- 通常不会限制偏移b
- 小的θ意味着更强的正则项
使用均方范数作为柔性限制
对于每个θ,都可以找到使得之前的目标函数等价于下面:
此柔性限制公式可由硬性限制公式通过拉格朗日乘子变换而来,二者本质无异。
超参数控制了正则项的重要程度:
- :无限制作用
- :
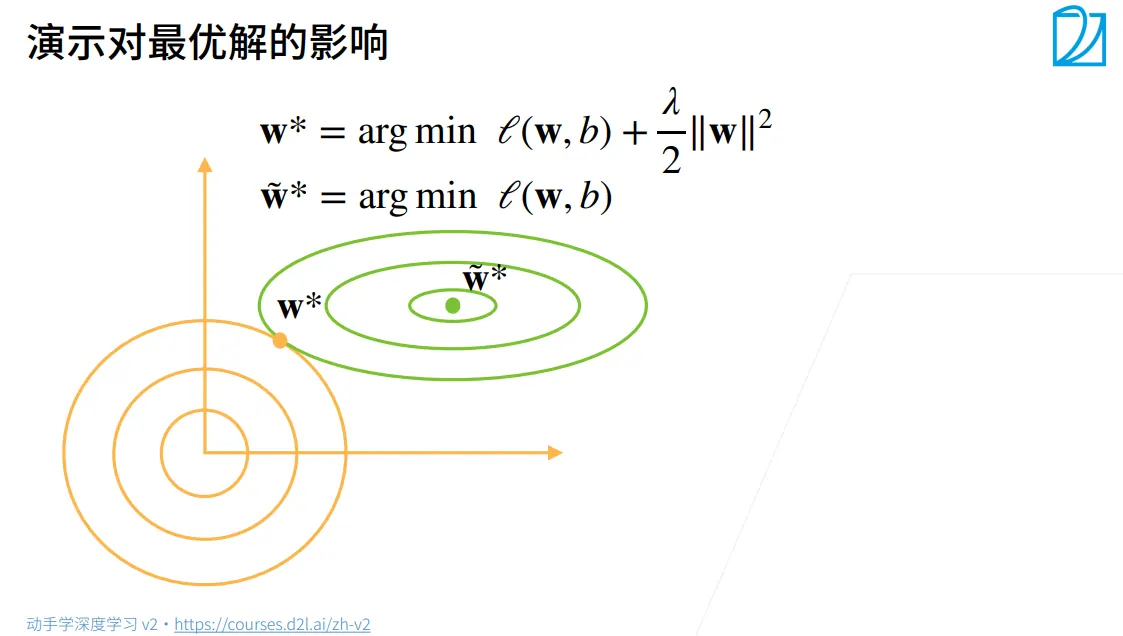
绿色的椭圆:损失函数的等高线
- 中心点是模型在不加约束时最想去的地方
- 离中心越远,损失值越大。椭圆表示在这些点上,损失函数的值是相等的。
黄色的圆圈:正则项的等高线
- 中心在原点(0 , 0)
- 圆圈代表权重的模长。离原点越近,越小,正则项的惩罚就越轻。
加上正则项后,优化过程变成了一场 拉锯战 :
- 损失函数想把 拉向 (为了拟合数据)。
- 正则项想把 拉向原点(为了保持模型简单,防止过拟合)。
最终的最优解 停留在两个力平衡的地方:也就是图中 绿色椭圆与黄色圆圈相切的点 。
这就是为什么L2正则化被称为”权重衰减”:它迫使权重在拟合数据的同时,尽可能地减小自己的数值。
参数更新法则
- 首先对于带有L2惩罚项的新目标函数求导:
- 代入梯度下降更新公式
得到:
- 拆开括号,重新组合:
为什么叫权重衰退?
前的系数为。
- 是学习率, 是正则化超参数,它们都是大于 0 的小数字。
- 通常 (比如 ,乘起来就是 )。
- 那么 就是一个 略小于 1 的数 (比如 )。
这意味着,在每次更新参数、朝着降低误差的方向迈步之前,算法都会先强行把当前的权重 乘以 ,让它“缩水”一点点。 这也就是这里要表达的核心概念:L2 正则化在普通的随机梯度下降(SGD)中,直观的表现就是每次更新都让权重衰减(变小)一点,从而限制了模型的复杂度,防止过拟合。
代码实现
手动实现权重衰退
实现这一惩罚最方便的方法是对所有项求平方后并将它们求和。
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2这里没有加入
训练函数:
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
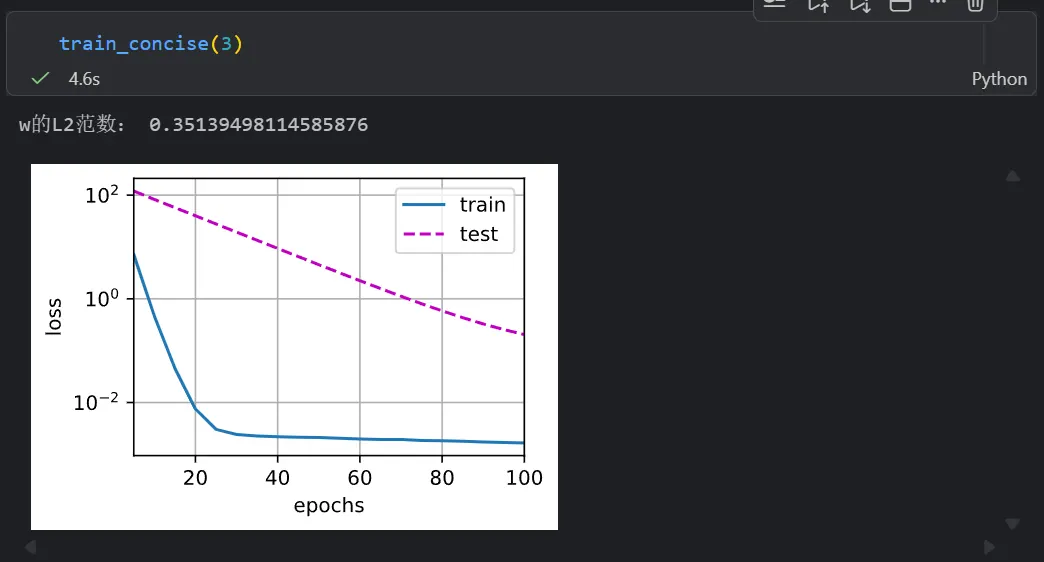
print('w的L2范数是:', torch.norm(w).item())简洁介实现权重衰退
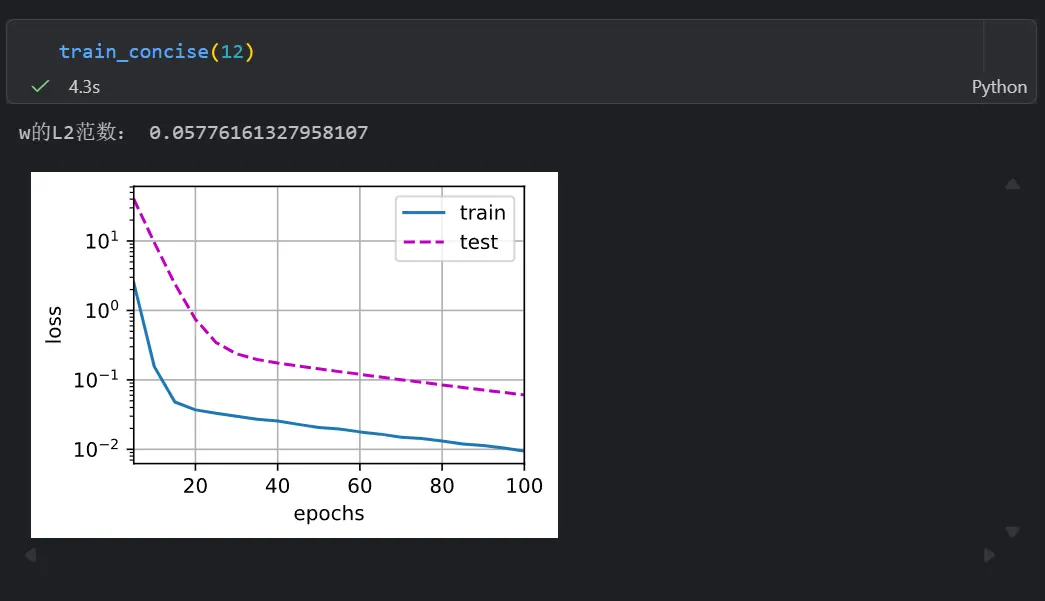
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
# 框架提供一个weight_decay的选项
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
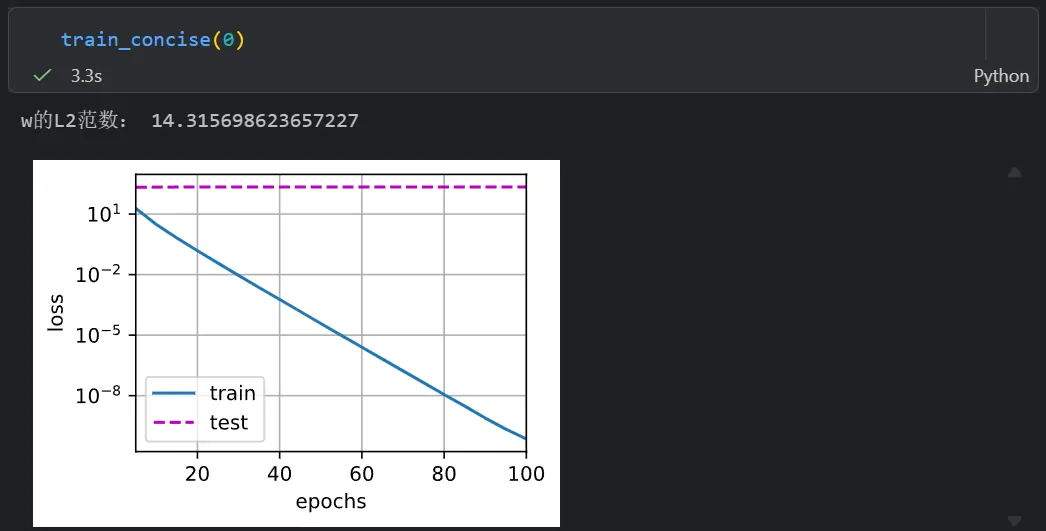
print('w的L2范数:', net[0].weight.norm().item())权重衰退的效果
无L2权重衰退:
暂退法/丢弃法(Dropout)
- 一个好的模型需要对输入数据的扰动鲁棒
如果在输入数据里加一点点随机噪音(比如图片多了几个雪花点,或者某几个像素颜色变了),一个真正学到了核心特征的好模型,依然能给出正确的预测,而不是直接预测错误。
- 使用有噪音的数据等价于Tikhonov正则
Tikhonov正则是L2 正则化(权重衰退) 的另一种数学叫法。
- 丢弃法:在层之间加入噪音
既然在“输入数据”上加噪音能防止过拟合(等价于正则化),那对于深层的神经网络,我们为什么不在它的内部结构里也加噪音呢?
丢弃法并不修改原始输入图片,而是在神经网络的前向传播过程中, 在相邻的隐藏层之间注入噪音 。具体做法就是:按照一定的概率 ,随机把当前层一部分神经元的输出强制归零(也就是把它们“丢弃”掉)。
无偏差的加入噪音
对 加入噪音得到 ,我们希望:
丢弃法对每个元素进行如下扰动:
使用丢弃法
通常将丢弃法作用在隐藏全连接层的输出上:
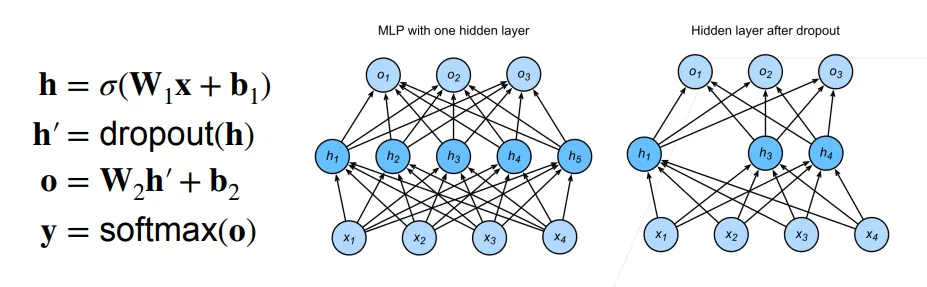
dropout和L2等正则项只在训练时使用,在推理时,不使用正则项。
手动实现丢弃法
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
# 每次随机的生成mask,使得每次失效的神经元都不一样
return mask * X / (1.0 - dropout)对于计算机底层来说,做乘法比选择一些结果赋值为0,要更快。
定义模型:
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
# 输出层不添加dropout
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)简介实现丢弃法
很简单,直接添加两个dropout层:
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))数值稳定性
考虑如下有d层的神经网络:
计算损失关于的梯度:
向量关于向量的导数是一个矩阵。一共需要进行d - t 次的矩阵乘法
数值稳定性的常见两个问题
梯度爆炸:参数更新过大,破环了模型的收敛性
梯度消失:参数更新过小,在每次更新时几乎不会移动,导致模型没法学习
例子:MLP
我们使用数学公式证明:为什么深度神经网络这么容易发生”梯度消失”或”梯度爆炸”。
第一层:正向传播
- 是上一层传过来的数据
- 是当前层的权重矩阵。两者相乘就是最基础的线性变换。
- 是激活函数(比如ReLU或Sigmoid)。把刚才线性变换的结果套进激活函数里,就得到了当前层最终的输出(也就是)
第二层:局部求导
这其实就是高中学过的复合函数求导(链式法则)的矩阵版本,对外层求导,再乘以内层求导:
- 对外层激活函数求导: 变成了 (导数函数)
- 为什么出现了一个
diag对焦矩阵:因为激活函数是独立作用在每一个神经元上的,1 号神经元的变化不会影响 2 号神经元。所以求导出来的矩阵(雅可比矩阵)只有对角线上有值,其他地方全是 0。
- 为什么出现了一个
- 对内层线性变换求导:对求导,结果就是权重矩阵的转置
第三层:连乘灾难
要把每一层的“对角矩阵”和“权重转置矩阵”,像贪吃蛇一样全乘起来。
- 梯度消失: 如果你用了 Sigmoid 激活函数,它的导数最大只有 。如果网络很深,几十个 甚至更小的数乘在一起,结果瞬间就变成了 。梯度传不回去,前面的网络层就“死”了,参数永远得不到更新。
- 梯度爆炸: 如果你一开始随机初始化的权重矩阵 里面的值比较大(比如都大于 ),几十个大于 的矩阵连乘,结果会呈指数级爆炸,变成天文数字,模型直接报错(NaN)。
梯度爆炸
使用ReLU作为激活函数
如果我们使用ReLU作为激活函数,它的导数非常极端:
- 如果输入 ,导数 。
- 如果输入 ,导数 。
中的一些元素会来自于
如果d - t很大,值将会很大。
梯度爆炸的问题
值超出值域:
- 对于16位浮点数尤为严重
对学习率敏感:
- 如果学习率太大->大参数值->更大的梯度
- 如果学习率太小->训练无进 展
- 我们需要在训练过程中不断调整学习率
梯度消失
使用sigmoid作为激活函数
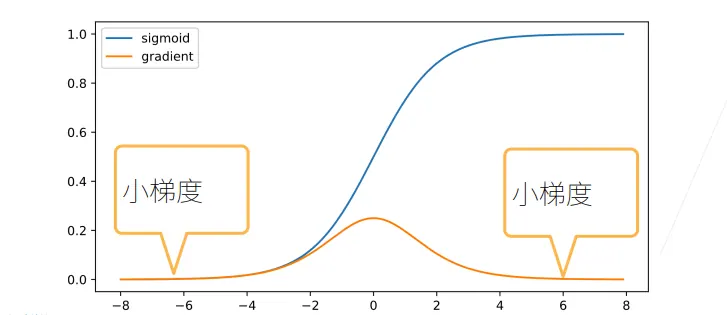
当输入很大或很小时,梯度会很小,基本上接近0了
的元素时d-t个小数值的乘机。
梯度消失的问题
梯度值变为0
- 对16位浮点数尤为严重
训练没有进展
- 不管如何选择学习率
对于底部层尤为严重
- 仅仅顶部层训练的较好
- 无法让神经网络更深
模型初始化和激活函数
核心问题:让训练更加稳定。
让每一层的方差是一个常数
将每层的输出和梯度都看作是随机变量,让它们的均值和方差都保持一致。
正向传播:保证输出层层稳定
- :这表示我们希望第 层输出 的 均值(数学期望)为 0 。这意味着正数和负数的输出大致平衡,不会导致整个网络的数据全往一个方向偏移。
- :这表示我们希望输出的 方差(Variance)维持在一个常数 。方差代表数据的离散程度(波动范围)。如果方差变大,说明激活值越来越极端(正向爆炸);如果方差变小,说明所有神经元的输出都趋同于 0(正向消失)。
反向传播:保证梯度层层稳定
- :梯度的均值为0,保证参数更新时不会整体向一个方向狂奔
- :梯度的方差为常数b
- 梯度爆炸:方差层层递增
- 梯度消失:方差层层递减
权重初始化
我们可以通过权重初始化来实现上述训练和推导效果。
例子:MLP
正向传播
证明一
证明:在最简化的条件下,如果权重初始化得当,当前层输出均值一定为0。
前置假设:
- 权重独立同分布:假设我们初始化的每一个权重参数,都是从同一个随机抽奖箱里摸出来的,大家互不影响。我们特意设定这个抽奖箱的均值,方差。
- 独立性:上一层传过来的数据,和当前层刚刚随机生成的权重是完全独立、互不相干的。
假设没有激活函数:
注意这里的假设没有激活函数,划重点,以后要考的。
独立的乘积 = 期望的乘积
因为我们一开始就规定了 权重的期望 ,所以无论 是多少,乘出来都是 0。无数个 0 加起来,结果依然是 0 。
只要我们把初始权重的均值设为0,那么不管网络有多深,每一层输出的数据均值都会稳定地保持在0
证明二
证明:计算当前层输出的方差,并推导出如何让信号方差在正向传播时保持平稳。
方差的定义:
- 起点公式:方差的基础公式
- 在证明一中我们证明了输出的期望,所以后面那一项直接变为0。
完全平方公式展开:
括号里被拆成了两部分:
- 平方项 :自己乘自己(即 的情况)。
- 交叉项 :互相乘(即 的情况)。
交叉项的消去:
- 为什么交叉项没了因为我们假设了权重之间是独立的,且 均值为 0 。当 时,。所以一长串交叉项全军覆没。
- 拆分期望 :因为权重 和输入 也是独立的,所以平方项的期望可以拆成两个期望相乘:
反向传播
这里不再展示反向传播的推导过程,仅展示反向传播需要满足的条件:
Xavier初始化
为了训练一个完美的深度神经网络,完美通过严密的数学推导,得出了初始权重方差必须满足:
- 为了正向信号不崩溃 ,方差必须满足:(等于输入维度的倒数)
- 为了反向梯度不崩溃 ,方差必须满足:(等于输出维度的倒数)
但是这两个条件很难同时满足,除非模型每一层输入等于输出()。
xavier初始化使得:
正太分布:
均匀分布:
假设激活函数
前面我们的推导都建立在:没有激活函数这一前提下;接下来我们需要考虑有激活函数后的情况。
假设线性激活函数
假设
加入激活函数求期望:
为了保证完美网络均值为0的优良传统,必须强行让。这意味着激活函数必须穿过原点。
既然,激活函数被化简为:
新方差等于老方差乘以 。为了让方差在经过激活函数后 绝对不改变 ,必须强行让 。因为斜率一般取正数,所以 。
反向传播推导:得到一样的结论
最终得到完美的激活函数为:(也就是完全没有任何变化的恒等映射)
这似乎是一个悖论:为了让深度学习网路保持稳定,我们最好不要使用激活函数。
学术界最终的妥协:早期深度学习特别喜欢用 作为激活函数。因为 在 附近的 泰勒展开(局部近似)刚好就是 !
由于我们初始化的权重非常小,一开始网络的计算结果 都集中在 0 附近。在训练刚开始的最危险阶段, 完美扮演了 的角色,保住了信号的均值和方差,让 Xavier 初始化得以完美发挥作用,成功避免了初期的梯度爆炸或消失。
检查常用激活函数
使用泰勒展开常用激活函数:
上面三种常见激活函数中,只有sigmoid完全不符合要求。它不仅改变了均值,还把方差缩小到了原来的 (因为 )。这就解释了为什么早年用 Sigmoid 训练深层网络时,梯度消失得一塌糊涂。
但是我们可以稍微调整sigmoid:
调整后: