每日一言
I do intend to pay you for your services. — Sohma Shigure from Fruits Basket
二叉排序树BST(二叉查找/搜索树)
定义
二叉排序树如果非空,则一定满足以下性质:
- 若左子树非空,则左子树上所有结点的值均小于根结点的值
- 若右子树非空,则右子树上所有结点的值均大于根结点的值
- 其左右子树也都是一颗二叉排序树
性质
- 中序遍历一颗二叉排序树,将得到一个以关键字递增排列的有序序列。
- 二叉排序树是动态查找树,在查找时将未找到的值的记录插入到查找树中,查找树是动态生成的。
操作
查找
通过返回值返回(该方法未找到时返回null):
Bitree SearchBST ( BiTree T, KeyType key )
//在二叉排序树T中查找关键字值为 key 的结点,
//找到返回该结点的地址,否则返回空。
{
if( (!T) || key == T->data)) //如果T为NULL则返回NULL,表示未找到
return T;
else if (key < T->date) //小于时查找左子树
return (SearchBST(T->lchild, key));
else //大于时查找右子树
return (SearchBST(T->rchild, key));
} //SearchBST P228-9.5(a)
通过参数返回(该方法未找到数据时返回应该插入位置的父节点):
bool SearchBST(BiTree T, KeyType key, BiTree f, BiTree &p)
//f指向当前结点的双亲,初始调用值为NULL。
//查找成功,p指向该结点,并返回TRUE;
//查找失败,p指向查找路径上的最后一个结点(方便进行插入),并返回FALSE
{
if(!T) //T为空结点,未找到,令p 等于 T的父节点
{
p=f;
return false;
}
else if (key == T->data) //找到,令p等于T
{
p=T;
return true;
}
else if (key < T->data)
return SearchBST(T->lchild, key, T, p);
else
return SearchBST(T->rchild, key, T, p);
}//SearchBST P228-9.5(b)
插入
bool InsertBST (BiTree &T,ElemType e)
{
if(!SearchBST(T, e.key, NULL, P)) //未找到时通过p返回父节点
{
s=(BiTree)malloc(sizeof(BiTNode));
s->data=e;
s->lchild=s->rchild=NULL;
if(!T)
T=s; //空二叉排序树
else if LT(e.key, p->data.key)
p->lchild = s; //小则插到p的左孩子
else
p->rchild = s; //大则插到p的右孩子
return TRUE;
}
else
return FALSE
} //InsertBST P228-9.6
查找并插入
Status SearchBST(BiTree &T, KeyType key, BiTree &p)
{
if(T) return SertchInsertBST(T, NULL, key, p);
//空树,将第一个结点插入
T=(BiTree)malloc(sizeof(BiTNode));
if(!T) return OVERSTACK;
T->data=key; T->lchild=T->rchild=NULL; p = T;
return OK;
}Status SearchInsertBST(BiTree T, BiTree f, KeyType key, BiTree &p)
//f指向当前结点的双亲,初始调用值为NULL。
//查找key成功,p指向该结点;查找key失败,插入key,p指向新结点,返回OK
{
if(!T) {
if(!(p = (BiTree)malloc(sizeof(BiTNode)))) return OVERSTACK;
p->data=key; p->lchild=s->rchild=NULL;
if (key < f->data.key) // 这里为什么不担心f为NULL?第一次调用时T不为NULL
f->lchild = p; //小则成为f的左孩子
else
f->rchild = p; //大则成为f的右孩子
return OK;
}
else if (key == T->data){
p=T; return OK;
}
else if (key < T->data)
return SearchInsertBST(T->lchild, T, key, p);
else
return SearchInsertBST(T->rchild, T, key, p);
}
删除
删除的情况有四种:
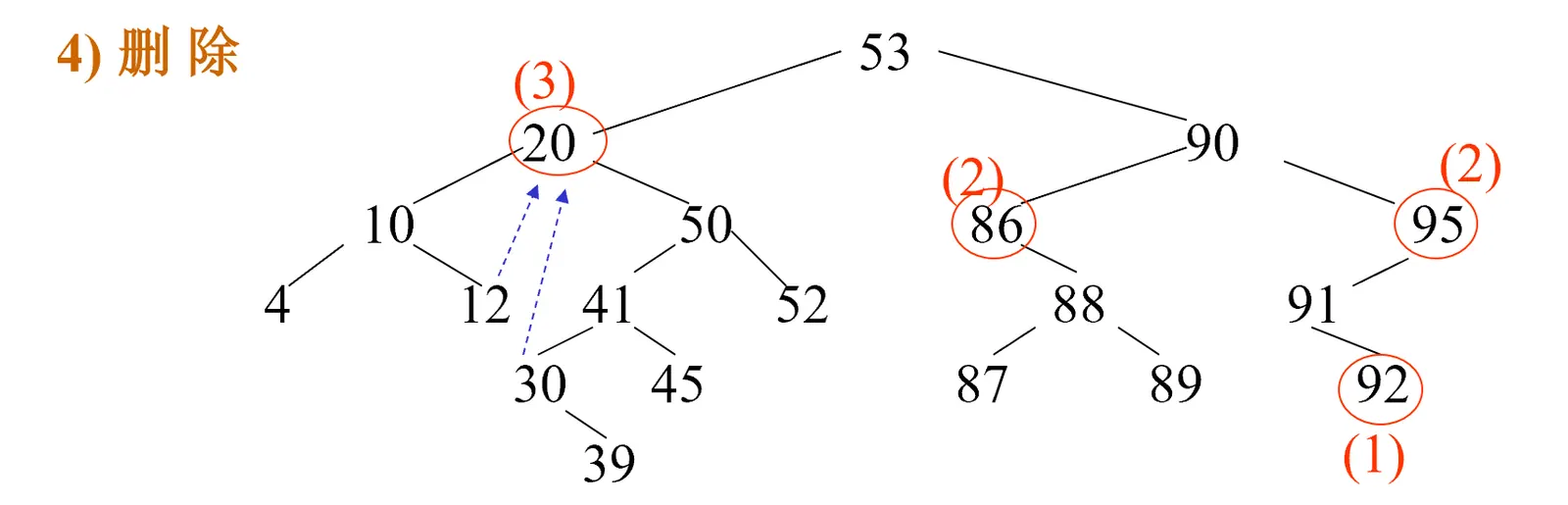
- p是叶子结点:修改其双亲指针即可
- p只有左孩子:用p的左子树代替以p为根的子树
- p只有右孩子:用p的右子树代替以p为根的子树
- p有两个孩子:
- 找到p的中序后继(或前趋)结点q;
- q的数据复制给p;
- 递归处理q的删除问题。
平衡二叉树
对于平衡二叉树如果非空,则一定是满足如下性质的排序二叉树 :
- 它的左右子树的高度之差的绝对值不超过1;
- 其左右子树本身又各是一颗平衡二叉树;
对于一颗平衡二叉树,其平均查找长度与 同数量级。
结点存储结构
typedef struct BSTNode {
ElemType data;
int bf; // 平衡因子
struct BSTNode *lchild,
*rchild;
}BSTNode, * BSTree;
结点的平衡因子(balance factor),定义为结点左子树的高度减去右子树的高度,同时规定空结点的平衡因子为0。根据平衡二叉树的性质我们可以得到,对于任一一棵平衡二叉树的任意结点都满足 -1<bf<1
平衡二叉树操作
查找
平衡二叉树也是排序二叉树,所以查找与排序二叉树相同
Bitree SearchBST ( BiTree T, KeyType key )
//在二叉排序树T中查找关键字值为 key 的结点,
//找到返回该结点的地址,否则返回空。
{
if( (!T) || key == T->data))
return T;
else if (key <= T->date)
return (SearchBST(T->lchild, key));
else
return (SearchBST(T->rchild, key));
} //SearchBST P228-9.5(a)
插入
在平衡二叉排序树中,我们的插入依然遵循二叉排序树的方法,只不过在插入时,我们还需要时刻注意平衡调整。
平衡调整
平衡调整前后不能改变二叉树的中序遍历顺序,基础的平衡调整分为左旋(RR平衡旋转) 和 右旋(LL平衡旋转)。
旋转操作既能保持“二叉搜索树”的性质,也能使树重新变为“平衡二叉树” 。 我们将平衡因子绝对值 |bf| > 1 的结点叫做 “失衡结点”。
右旋
右旋也称为单右旋转或LL平衡旋转。对于结点a 的右旋操作是:将 A 的左孩子B向右上旋转,代替 A 成为根节点,将 A结点向右下旋转成为 B的右子树的根结点,B的原来的右子树变为 A的左子树。
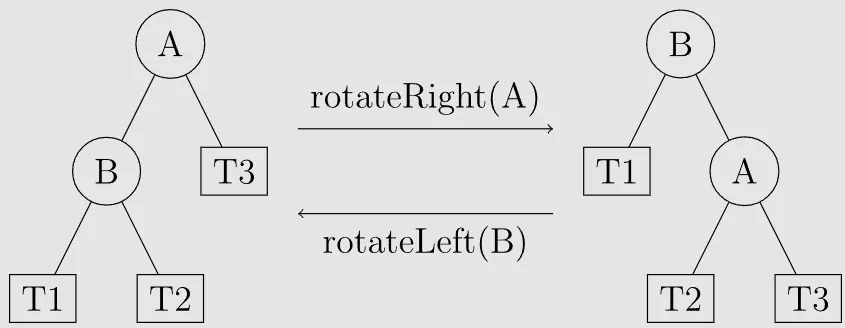
左旋
左旋也称为左单旋转或RR平衡旋转,对于结点b的左旋操作是:将B的右孩子向左上旋转,代替B称为根结点,将B结点向左下旋转称为A的左子树的根结点,A原来的左节点变为B的右子树。
四种平衡破坏情况
在下面的图中,T结点为失衡结点,L/R结点为其深度较高的一侧结点,T1,T2,T3,等结点表示不影响失衡的结点,可能是空结点,也可能非空,但是一定都是叶子结点。
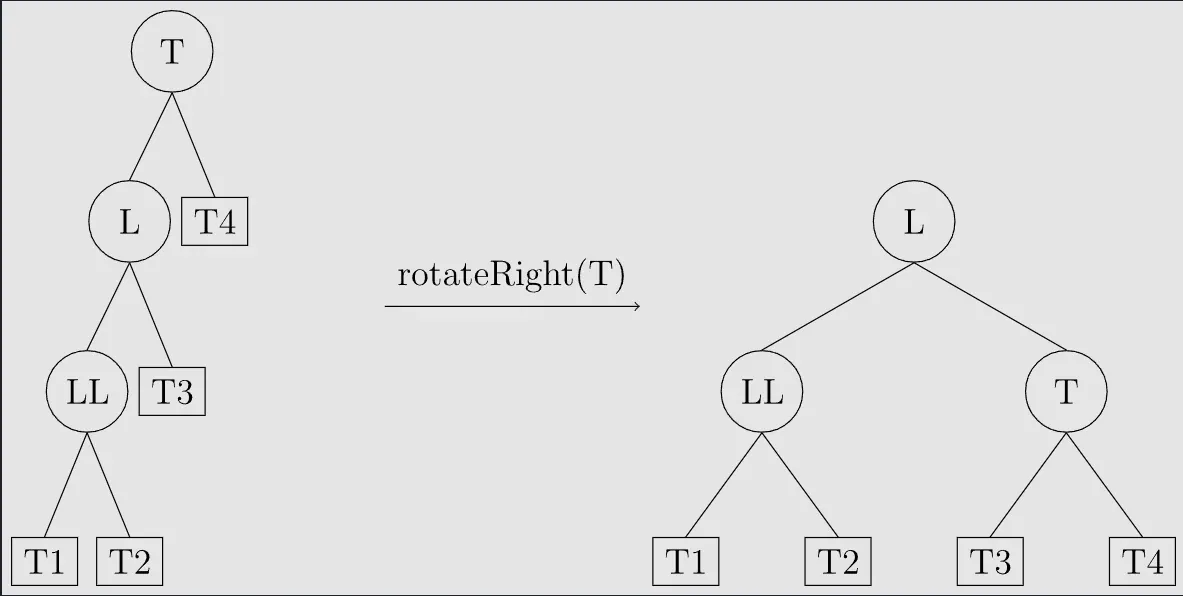
LL型
T结点的左孩子的左子树过长导致平衡性破坏
调整方式: 右旋结点T
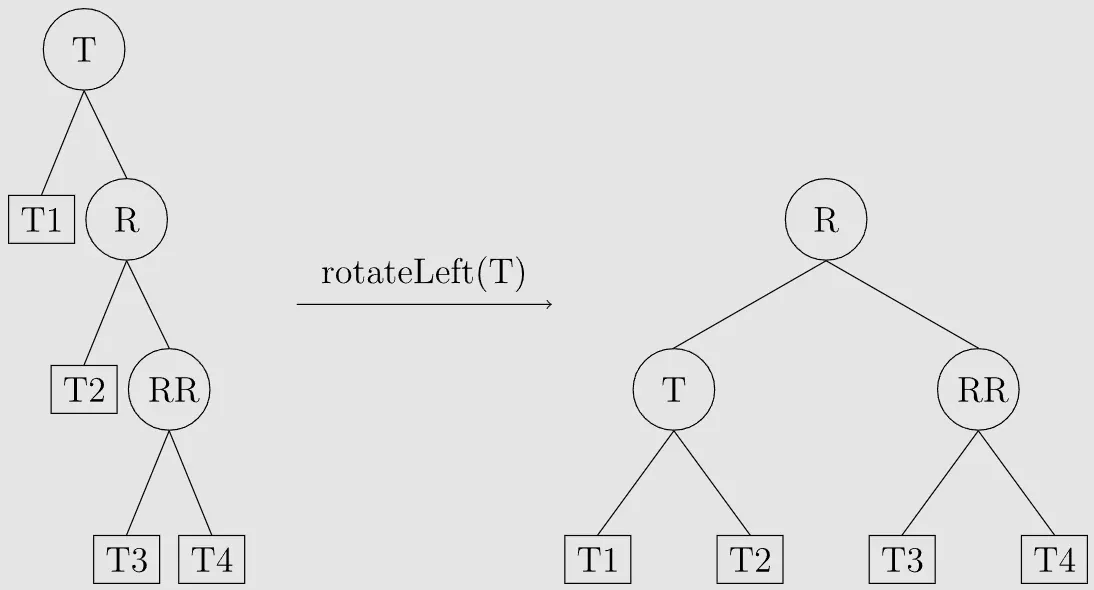
RR型
T结点的右孩子的右子树过长导致平衡性破坏
调整方式:左旋T结点
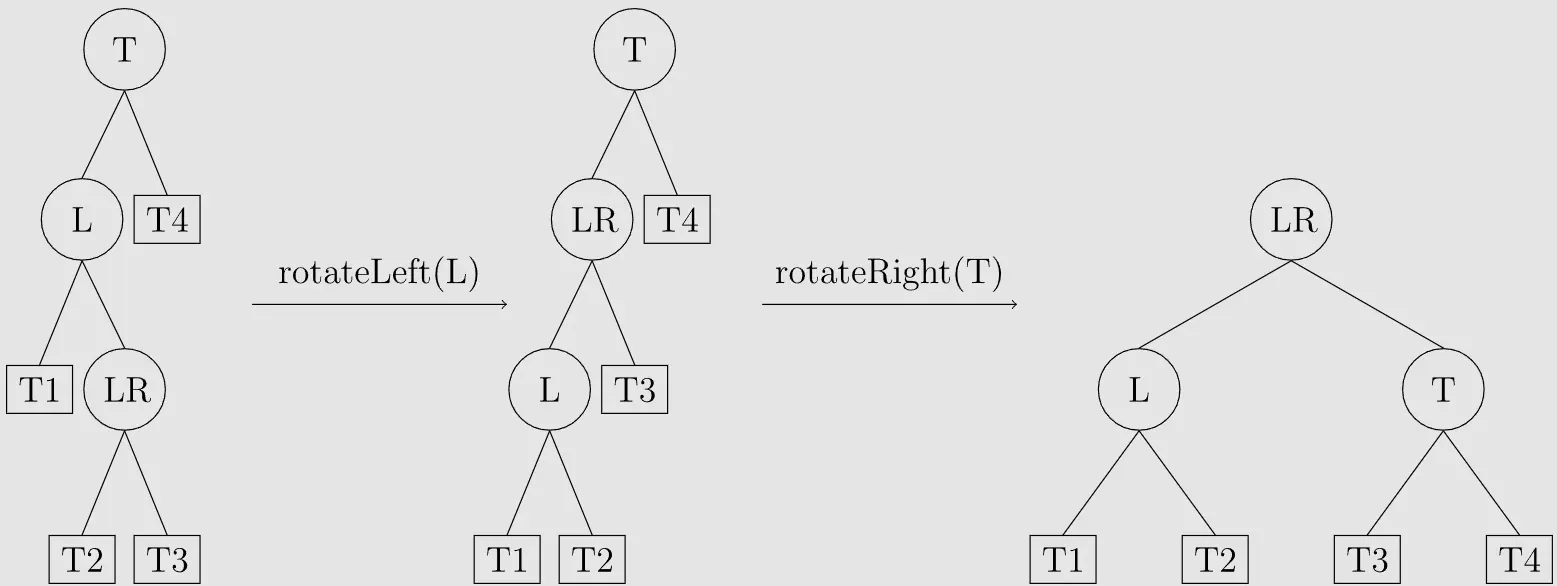
LR型
T结点的左子树的右子树过长导致平衡性破坏。
调整方式:先左旋L结点,成为LL型,再右旋T结点
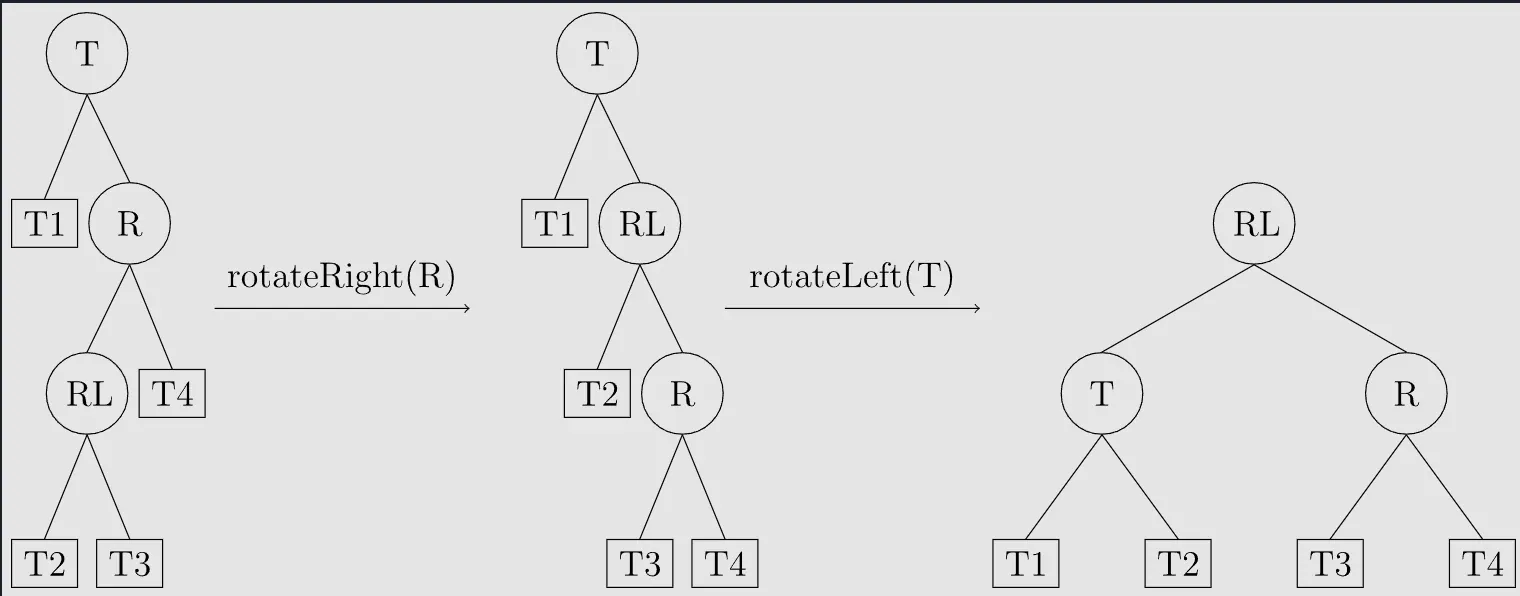
RL型
T结点的右子树的左子树过长导致平衡性破坏
调整方式:先右旋R结点,成为RR型,再左旋T结点
如何选择正确的旋转方式
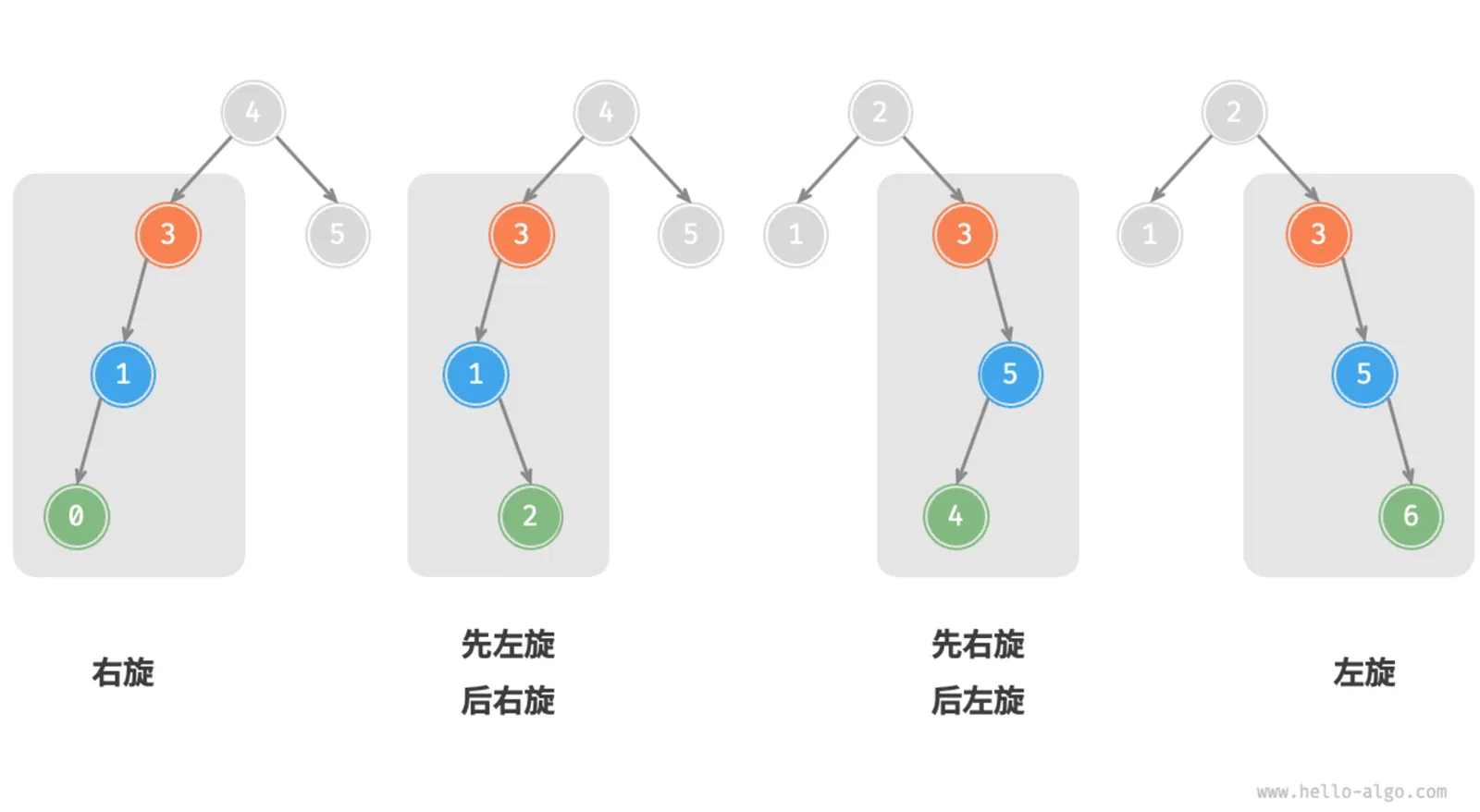
根据图中的四种失衡情况,我们通常通过判断失衡结点的平衡因子以及深度较高一侧子结点的平衡因子的正负号,来确定失衡结点属于那种情况。
| 失衡节点的平衡因子(T) | 子节点的平衡因子(L/R) | 应采用的旋转方法 |
|---|---|---|
| T->bf > 1 | L->bf > 0 | LL(右旋) |
| T->bf > 1 | L->bf < 0 | LR(先左旋再右旋) |
| T->bf < -1 | R->bf > 0 | RL(先右旋再左旋) |
| T->bf < -1 | R->bf < 0 | RR(左旋) |
红黑树(Red Black Tree)
- 红黑树(Red Black Tree) 是一种自平衡二叉查找树;
- 红黑树是一种特化的AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
- 它可以在O(log n)时间内做查找,插入和删除。
- 红黑树是一种平衡二叉查找树的变体,它的左右子树高差有可能大于 1,所以红黑树不是严格意义上的平衡二叉树(AVL),但 对之进行平衡的代价较低, 其平均统计性要强于 AVL
红黑树的性质
- 红黑树是每个节点都带有颜色属性的二叉查找树,颜色或红色或黑色
- 根节点是黑色
- 所有叶子都是黑色(叶子是NULL节点,External Node)
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
- 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。
结点插入算法
- 插入过程首先是根据一般二叉查找树的插入步骤,把新节点 z插入到 某个叶节点的位置上(新结点的两个子节点成为新的叶节点,着黑色)
- 然后将新节点z着为红色
- 若z的父结点为黑色,此时即为红黑树
- 若z的父结点为红色,对有关节点重点着色(Color flip)和旋转(Rotation)来恢复红黑树的性质
B-树 (B-tree,B即balanced)
B树是一种平衡的多路查找树。可应用与文件系统。
定义:B-树是一种平衡的多路查找树。
一颗m阶的B-树,或为空树,或为满足下列特征的m叉树。
- 树中每个结点最多有m棵子树
- 若根结点不是叶子结点,则最少有两棵子树
- 除根之外的所有非叶子结点最少有 [m / 2] 棵子树(向上取整)
- 所有非叶子结点包含(n,,,,,…………,,)信息数据;n为结点中关键字的个数, 为指向子树的指针, 为关键字。
- 所有叶子结点在同一层上,且不带信息。
叶子结点通常还称为:失败结点(failure),简称F。内容为空值,仅用于分析B-树的性能。
示例:
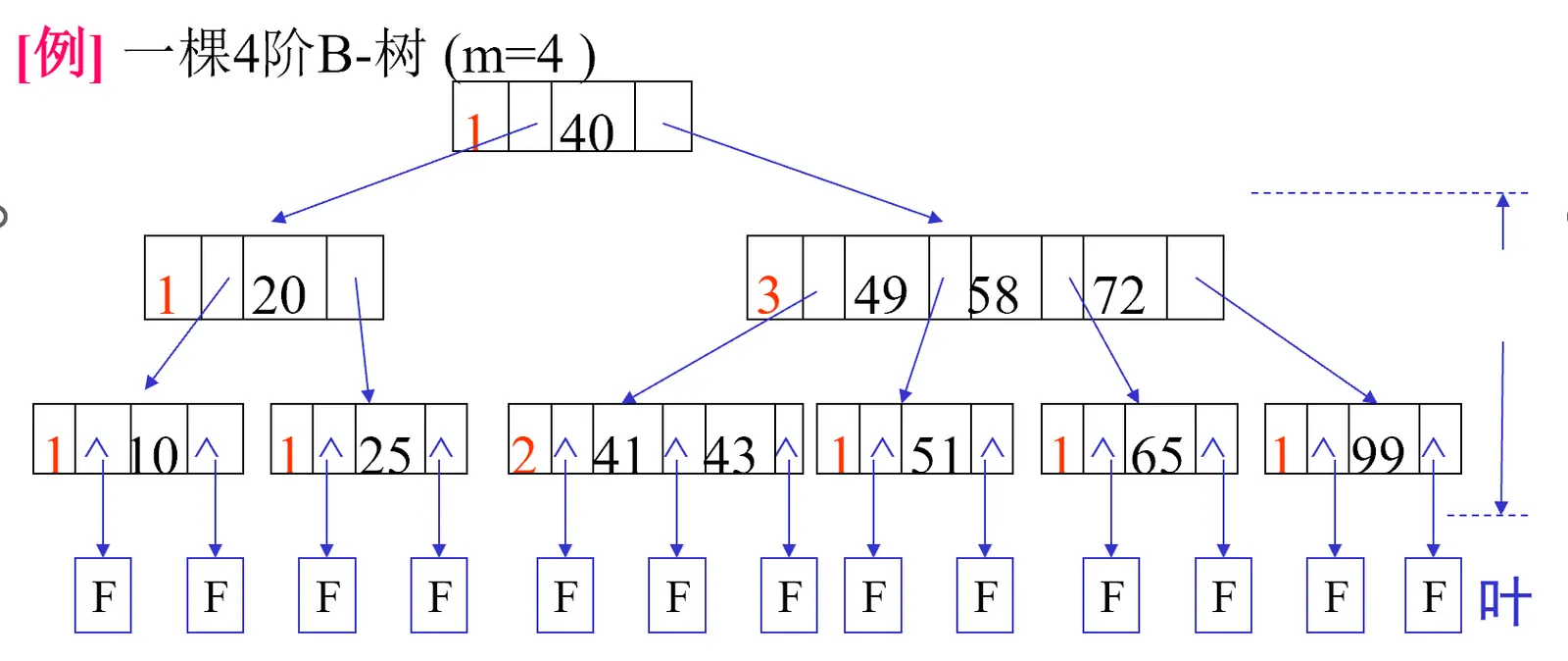
n 个 关键字,将一系列关键字划分为n+1段,每段在一个子树中。也就是说有n棵子树的结点中有n-1个key值
存储定义
结点定义:
#define m 3 //B-树的阶
typedef struct BTNode {
int keynum; //关键字个数
struct BTNode *parent; //双亲指针
KeyType key[m+1]; //0号未用,关键字数组
struct BTNode *ptr[m+1]; //0号未用,子树指针数组
Record *recptr[m+1]; //0号未用,磁盘记录地址数组
} BTNode, *BTree;
查找结果描述:
typedef struct {
BTNode *pt;
int i; //1..m,成功时第i个关键字等于key;
//失败时,关键字在第i和第i+1的关键字之间。
int tag;//1成功,0失败
}Result;
查找
Result SearchBTree(BTree T, KeyType K)
{
p = T; q = NULL; found = false; i=0;//q指向p的双亲
while (p && ! found)
{
i = Search(p, K); //在p->key[1..keynum]中找i,
// 使得key[i]<=K<key[i+1]
if( i>0 && p->key[i]==K )
found = TRUE;
else
{
q = p;
p = p->ptr[i];
}
}
if (found)
return (p,i,1);
else
return (q,i,0);
}//SearchBTree
算法描述:
- 从根结点开始寻找,从头遍历p->key 数组。
- 若找到:
- 返回当前 i ,并且tag = 1,
- 返回(p,i,1)
- 未找到:
- 如果 i <= n 即 p->ptr[i] != nullptr ,再以p->ptr[i] 为根遍历。
- 如果 i > n 即 p->ptr[i] == nullptr,返回当前结点。
插入
算法思想:
- 首先使用查找函数在B-tree 中查找K
- 查找成功:则返回
- 查找失败:则返回一个位于最低层的非叶结点
- n += 1
- 若没有溢出(n<0)则写入当前位置
- 若溢出:以key[m/2(向上补全)]为划分点,将当前结点划分为两个结点
- 第一个结点q的范围为: ~
- 第二个结点的范围为: ~
- 然后写入这两个结点 ,
- 然后在该结点的父节点中插入(, ),以该父节点为当前结点q ,再进行步骤2。
删除
算法思想:
- 在B-树种查找K,若未找到,则返回
- 若找到,则返回(q,i,1):
- 若q结点不是最下层结点
- 查找p->ptr[i] 所指子树中最小的key值x,用x替换key[i],将问题转化为删除子叶结点
- 在子叶结点中删除x
- 如果结点中关键字个数大于[m/2]-1,则直接删除
- 如果结点中关键字个数等于[m/2]-1
-
兄弟结点关键字个数大于[m/2]-1,则向兄弟借
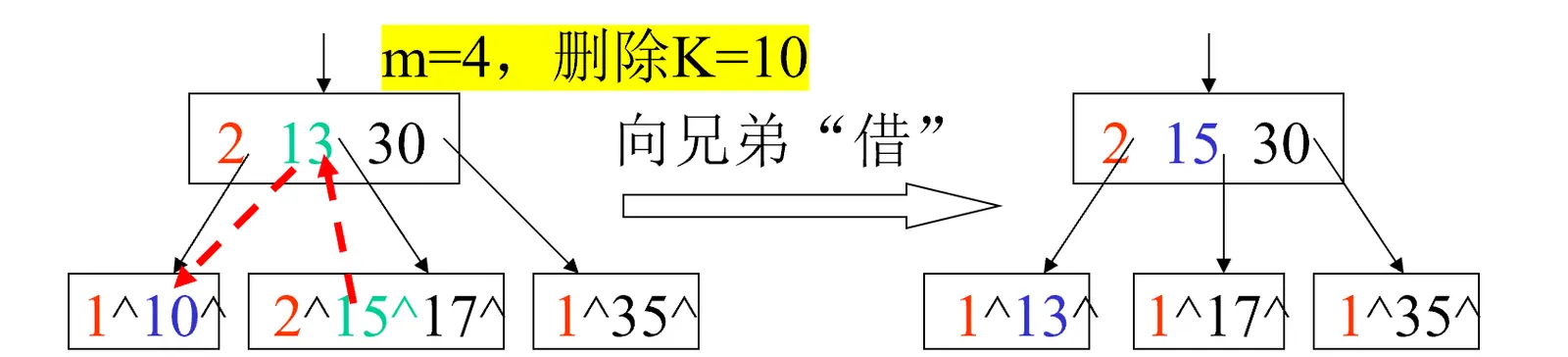
-
兄弟关键字个数也等于[m/2]-1,则从父节点拉下来一个然后合并两个子结点:
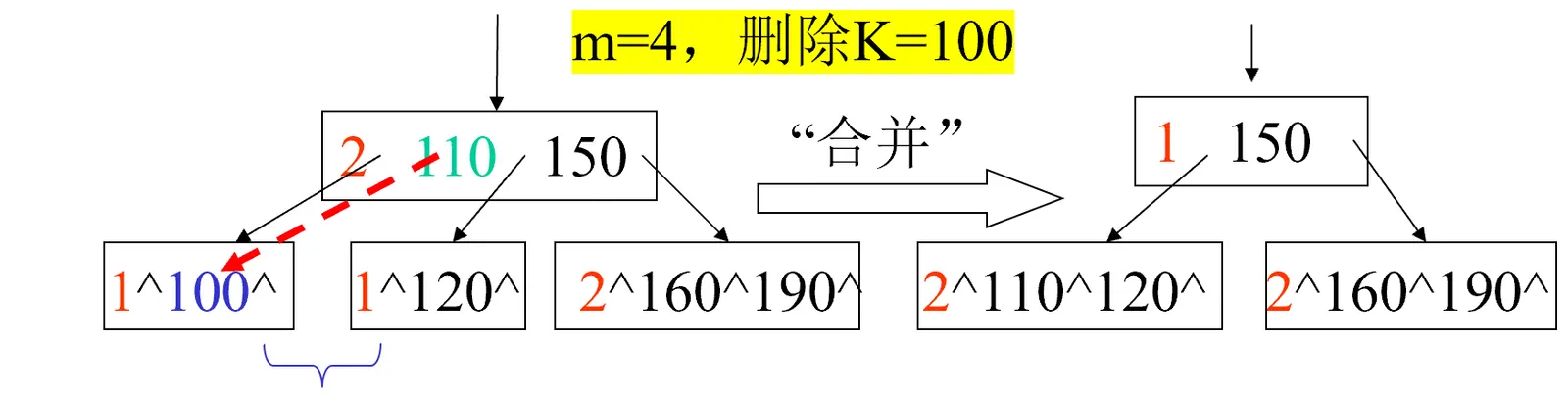
-
再向上递归处理父节点
-
- 若q结点不是最下层结点
可能过程有点复杂难懂,我们看个示例:
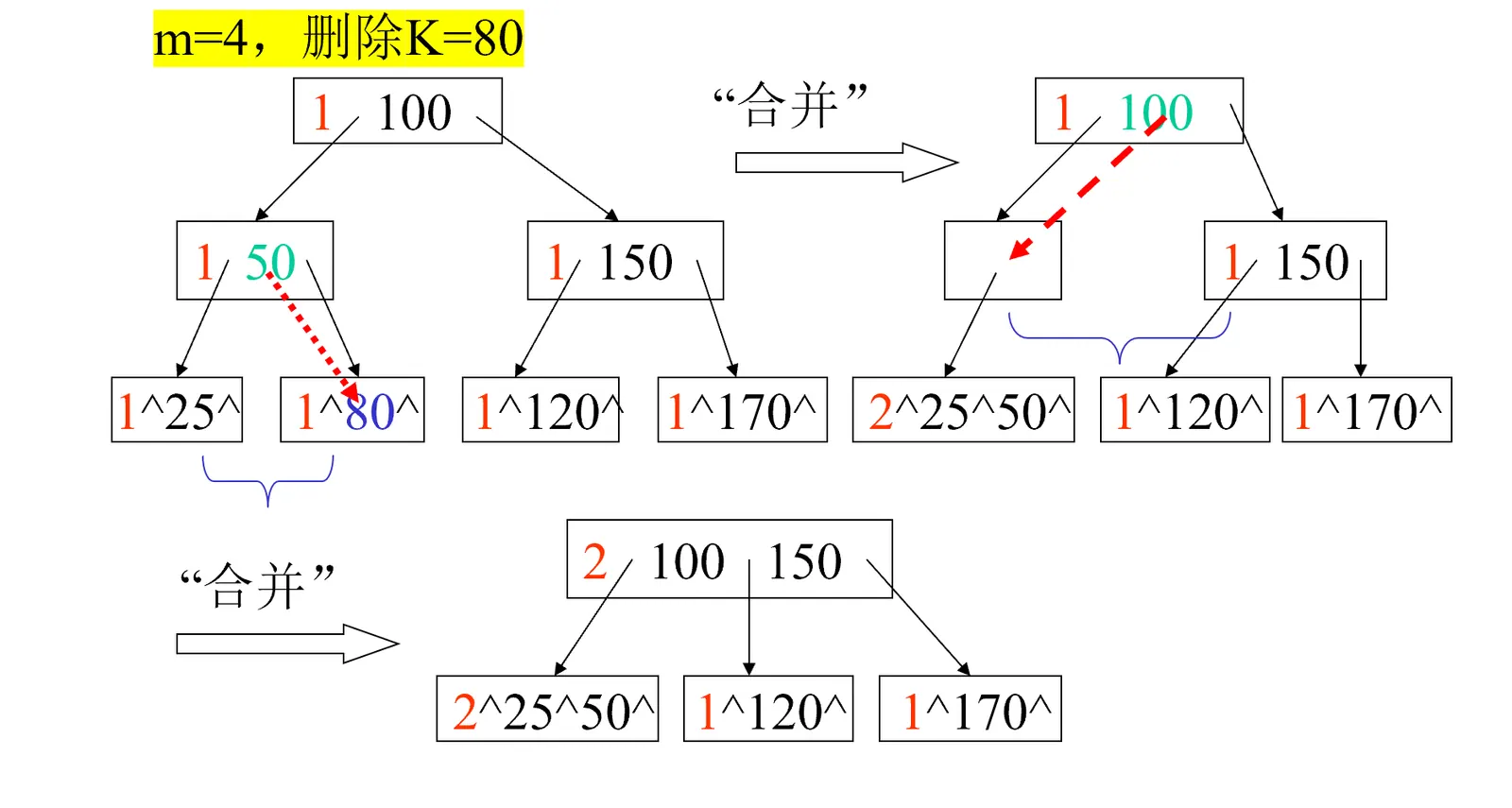
B- 数的插入和删除建议结合该部分的作业一起食用,才能更好的理解。可见数据结构查找与哈希表作业。
B-树的高度及性能分析
仅在内存中使用的B-树必须取较小的m,通常取 m = 3
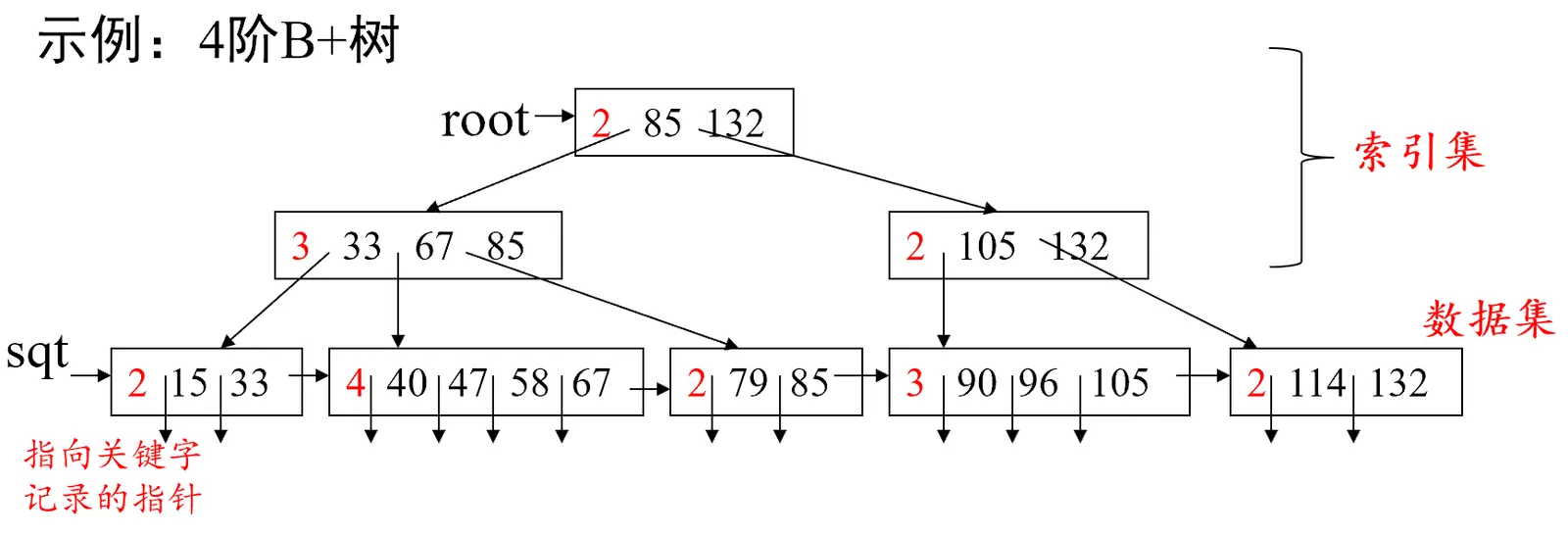
B+ 树
B+树是一种B-树的变形树。
m阶B+ 树与B-数的不同之处
- 有n个子树的结点中有n个关键字(B-树有n-1个)
- 非叶结点可以看成是索引部分(索引集)
- :第i个子节点的指针
- :第i个字结点的最大(或最小关键字)
- 所有叶子结点中包含了全部关键字的信息及指向这些关键字记录的指针,且叶子结点以关键字大小自小至大顺序链接(与B-树相比,子节点不包含父节点中的key值信息)
结构:
索引集:非叶结点共同组成
数据集:所有叶结点组成
示例:
键树(数字查找树/字符树)
将关键字分解为字符的多叉树,多叉树中的每个结点只代表关键字中的一个字符,叶结点用于表示字符串的结束符(如‘$’),并含有指向该关键字记录的指针。从根到叶子的路径上所有的结点对应的字符连接起来就代表一个关键字。
约定:
- 键树是有序树
- 结束符小于任何字符
例子:
对于一个关键字集合{beg,bell,big,log,long,nil}
它的键树为:
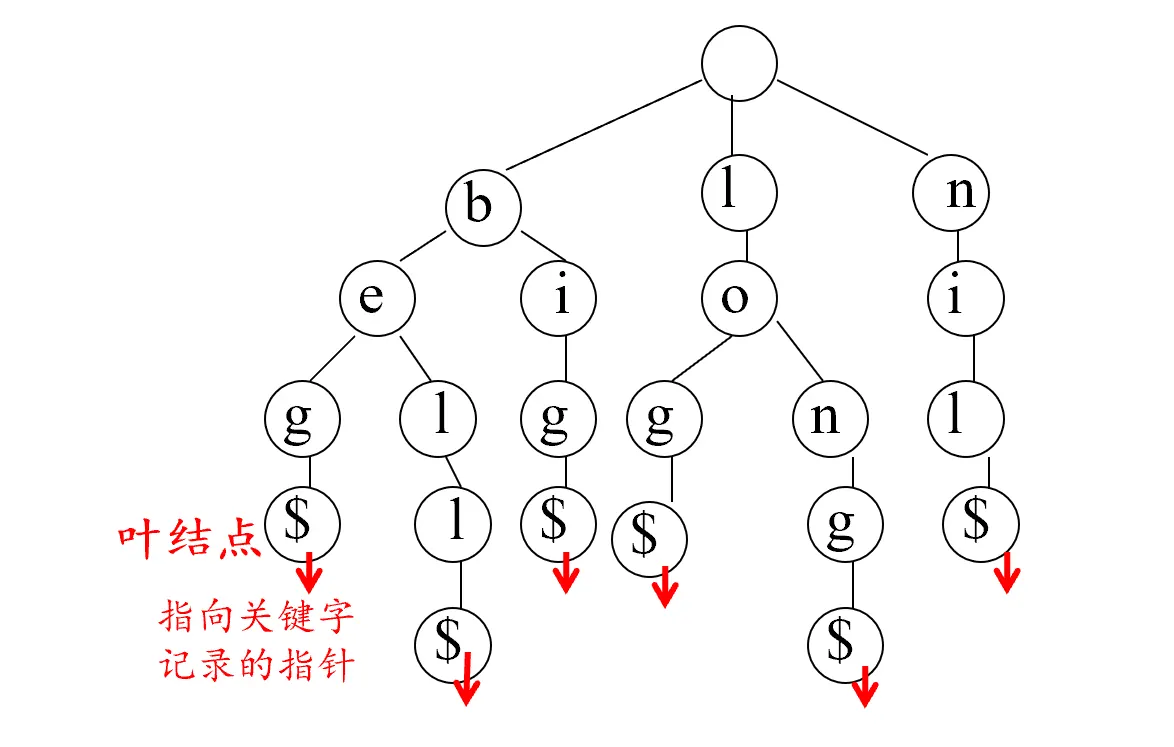
Trie树(retrieval 树)
若从键树中某个结点开始到叶子结点的路径上的每个结点中都只有一个孩子,则将该路径上的所有结点压缩成一个“叶子结点”,且叶子结点中存储有指向记录的指针。