信任是昂贵的,别指望在廉价的人身上找到它。—— 沃伦·巴菲特
从全连接层到卷积
分类猫和狗的图片
使用一个还不错的相机采样图片(12M像素),则RGB图片有36M元素。
使用100大小的单隐藏层MLP,模型有3.6B元素。实际上这个数字远大于世界上所有的猫和狗的总数。(900M狗,600M猫)
100 * 36M = 3.6B

如果要存储3.6B的参数,大约需要14GB的内存。想要训练这个模型将不可实现,因为需要有大量的GPU、分布式优化训练的经验和超乎常人的耐心。
图片识别的两个原则:
- 平移不变性:不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
- 局部性:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。

重新考察全连接层
不改变全连接层的本质,只改变我们观察它的视角。
核心目标:保留图像的 2D 空间结构,将全连接层的公式重写为基于“相对位置(偏移量)”的形式。
在之前我们处理Fashion-MNIST数据集时,我们将一张2D图片(28 X 28)拉平成一个1D的长向量。这样做的代价是彻底破坏了图像的空间结构。
但是现在我们不能拉平:
- 让输入X保持2D矩阵形状
X[k][l] - 让隐藏层输出H也保持2D矩阵形状
H[i][j]
现在我们的目标是,要怎么计算出图片中某个特定位置(i, j)的像素值。
绝对位置视角
在全连接层中,为了计算输出图上的哪怕一个点,我也必须把输出图上的所有点都看一遍。
用伪代码来写,表达如下:
# 假设我们要计算输出图上坐标为 (i, j) 的这个点 H[i][j]
sum = 0
# 遍历输入图上的每一个绝对坐标 (k, l)
for k in range(image_height):
for l in range(image_width):
# 拿到输入图上 (k, l) 位置的像素值 X[k][l]
# 乘以对应的权重 W
sum += W[i][j][k][l] * X[k][l]
H[i][j] = sum这里的
W[i][j][k][l]就是 4D 张量。
相对距离视角
其实什么都没有变,只是换了一种说话方式:
与其说“去拿绝对坐标 (k, l) 的像素”,不如说“以我现在的位置 (i, j) 为中心,去拿偏移了 (a, b) 距离的像素”。
- 在横轴上:原本的
k变成了i + a(当前位置向右偏 a) - 在纵轴上:原本的
l变成了j + b(当前位置向下偏 b)
伪代码如下:
# 依然是计算输出图上坐标为 (i, j) 的这个点 H[i][j]
sum = 0
# 这次我们不遍历绝对坐标了,我们遍历“偏移量” (a, b)
# 假设偏移量可以是从图的最左边到最右边,最上边到最下边
for a in range(-image_height, image_height):
for b in range(-image_width, image_width):
# 我们站在 (i, j) 的位置,拿到偏移 (a, b) 后的像素值 X[i+a][j+b]
# 乘以对应的权重 V
sum += V[i][j][a][b] * X[i+a][j+b]
H[i][j] = sum相对视角有什么意义呢?
想象一下,如果你要判断输出点
(i, j)是不是猫的眼睛。你需要看整张输入图片吗?不需要!你只需要看(i, j)附近的几个像素点就够了。也就是说,上面伪代码里的偏移量
a和b,根本不需要跑遍整张图片(从-image_height到image_height)。我们只需要让a和b在一个小范围(比如-1, 0, 1)里循环就可以了。
平移不变性
在图像中,x的平移会导致h的平移:
由于为了满足平移不变性:v不应该依赖于(i, j)。
为了解决这个问题,我们必须添加一个限制:
它的物理意义是:
- 无论我现在站在图片的哪个绝对位置 ,我用来观察周围偏移量 的 权重 都是同一套。
局部性
当评估时,我们不应该用远离的参数。
解决方法:当 时,使得
(Delta),在这里可以被理解为最大视距或者视野的半径。
最终的2D卷积公式:
如果用代码表示:查找表变成了一个小巧的滑动窗口(卷积核)
# 假设 Delta = 1,我们的感受野半径是 1
# 那么窗口的宽度就是 1 + 1 + 1 = 3,这就是经典的 3x3 卷积核
for i in range(image_height):
for j in range(image_width):
sum = 0
# 这里的循环不再是全图,而是被严格限制在了 -1 到 1 之间
for a in range(-1, 2):
for b in range(-1, 2):
# 只有这 3x3 = 9 个像素会参与计算!
sum += v_a_b[a][b] * X[i+a][j+b]
H[i][j] = sum总结
回到你最开始那张猫狗分类的 PPT。如果不加限制(全连接 MLP),我们需要 36亿 个参数。
但是,通过这两页 PPT 的推导:
- 平移不变性 :让全图共享同一套权重,不需要每个像素点都配一套。
- 局部性 :让这套权重的作用范围限制在一个极小的 窗口里(比如 )。
原本 36 亿个参数,现在 仅仅只需要 9 个参数 (也就是 在 窗口里的值)
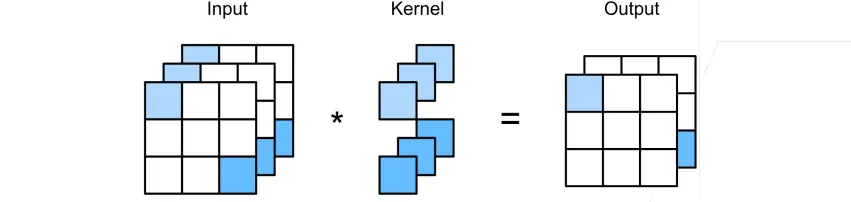
图像卷积
互相关运算
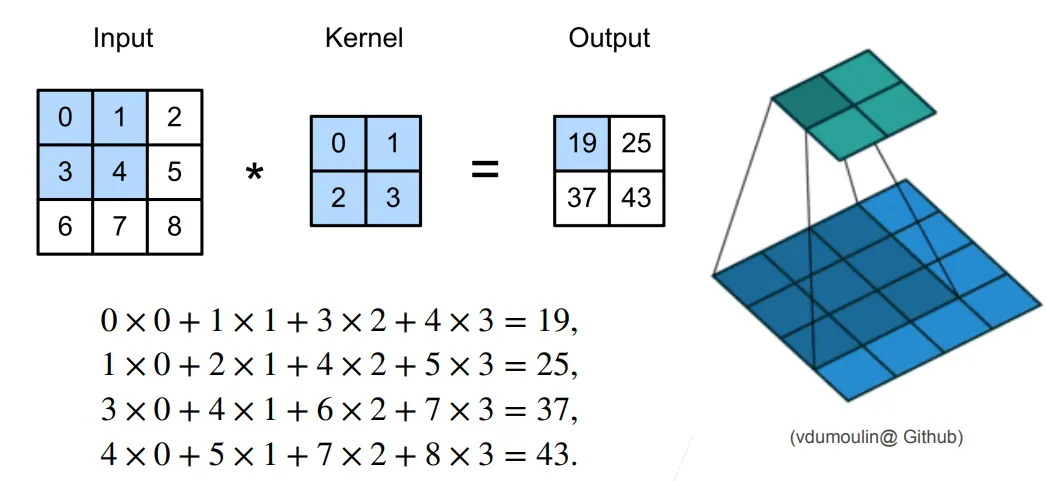
二维卷积层:
- 输入:
- 核:
- 偏差:
- 输出:
- 和 是可学习的参数
不同核运算的不同效果

交叉相关 VS 卷积
二维交叉相关:
二维卷积:
注意这里的 !在严谨的数学信号处理中,“卷积”是要求把权重矩阵(也就是滤波器) 先上下翻转,再左右翻转(相当于旋转 180 度) ,然后才能贴到图像上去做乘加运算。
- 在传统的图像处理里,这些权重是科学家手动设计好的(比如专门用来找边缘的 Sobel 算子),翻转了效果就不对了。
- 但在深度学习里,权重矩阵 里面的值是随机初始化的,然后 让神经网络自己通过反向传播(Backpropagation)学出来的
既然是学出来的,网络完全有能力自己把那个“翻转”的过程给吸收掉。
代码实现
二维互相关运算:
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y实现二维卷积层:
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias图像中的目标边缘检测
这是一个卷积层的一个简单应用:通过找到像素变化的位置,来检测图像中不同颜色的边缘。首先,我们构造一个简单黑白图像:
X = torch.ones((6, 8))
X[:, 2:6] = 0
Xtensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])中间四列为黑色0,其余像素为白色。
接下来构造卷积核:
K = torch.tensor([[1.0, -1.0]])现在,我们对参数和卷积核进行互相关运算:
Y = corr2d(X, K)
Ytensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])学习卷积核
当我们无法手动设计滤波器时,我们可以学习由X生成Y的卷积核:
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')在10次迭代之后,误差已经降到足够低。现在我们来看看我们所学的卷积核的权重张量。
conv2d.weight.data.reshape((1, 2))tensor([[ 1.0010, -0.9739]])这与我们之前手动指定的卷积核非常相近。
填充和步幅
填充
实例引入
-
假设我们给定(32 x 32)的输入图像
-
应用 5 x 5 大小的卷积核
- 第1层得到输出大小28 x 28
- 第7层得到输出大小4 x 4
-
更大的卷积核可以更快地减小输出大小
- 形状从减少到:

在这个实例中,我们的卷积层最多不能超过7层。那么如果我们想要使用更深的网络怎么办?
深度学习是关系如何使用更深的网络来进行预测。
解决这个问题的第一个办法就是用填充。
填充
在输入图像的周围添加额外的行/列。
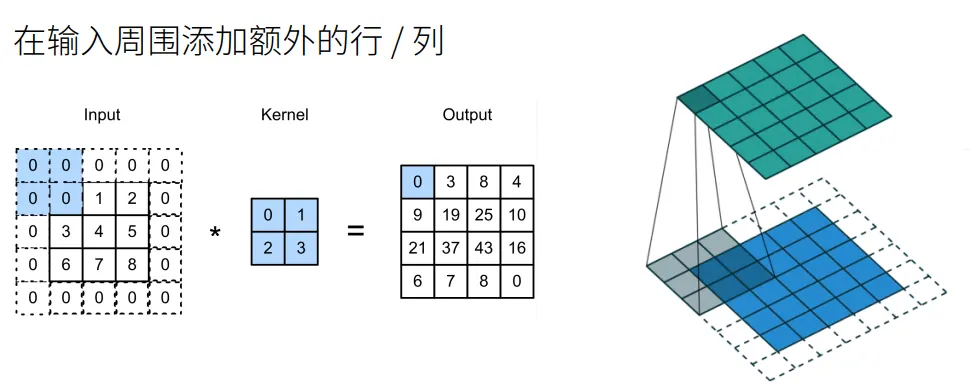
- 填充行和列,输出形状为:
- 通常取(卷积后图像不会发生变化)
- 当为奇数:在上下两侧填充
- 当为偶数:在上侧填充,在下侧填充
步幅
实例引入
在给定输入大小为224 x 224,在使用5 x 5卷积核的情况下,需要44层将输出降低到4 x 4。
需要大量计算才能得到较小输出。

在前面的例子中,我们默认每次滑动一个元素。 但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。
步幅
步幅是指行/列的滑动步长。
例子:高度3 宽度2 的步幅
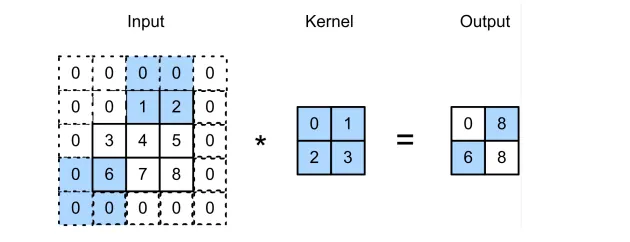
给定高度和宽度的步幅,输出形状是:
如果:
如果输入的高度和宽度可以被步幅整除:
总结
- 填充和步幅是卷积层的超参数
- 填充在输入周围添加额外的行/列,来控制输出形状的减少量
- 步幅是每次滑动窗口时的行/列的步长,可以成倍的减少输出形状
代码实现
填充
import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape如果卷积核的高度和宽度不同,我们可以填充不同的高度和宽度:
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape步幅
将高度和宽度的步幅设置为2:
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape复杂例子:
# 定义卷积层
# in_channels=1: 输入通道数为 1
# out_channels=1: 输出通道数为 1(使用 1 个卷积核)
# kernel_size=(3, 5): 卷积核的高度为 3,宽度为 5
# padding=(0, 1): 高度方向不填充(上下各 0 行),宽度方向左右各填充 1 列
# stride=(3, 4): 高度方向步长为 3,宽度方向步长为 4
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
# 假设 X 是输入张量,通常形状为 (批量大小, 通道数, 高度, 宽度)
# comp_conv2d 是一个常用的辅助函数,用于执行前向传播并返回结果
# .shape 用于查看输出特征图的尺寸
comp_conv2d(conv2d, X).shape多输入多输出通道
多个输入通道
彩色图像可能由RGB三个通道:

如果转换为灰度会丢失信息。
当包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核:
我们可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和得到二维张量。这是多通道输入和多输入通道卷积核之间进行二维互相关运算的结果。
每个通道都有自己的值,可能不一样
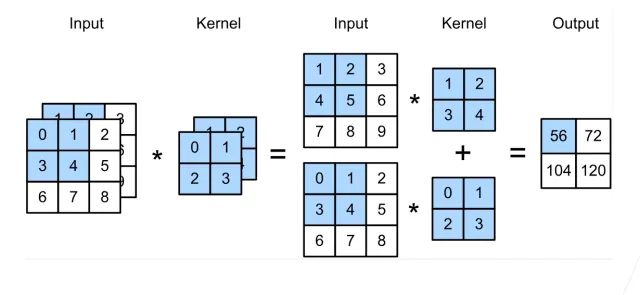
输入
核
输出
星号表示卷积操作
多输出通道
无论有多少输入通道,到目前为止我们只用到单输出通道。
-
一个三维核 = 一个提取器:
- 想象一个厚度为 的三维卷积核。它在输入 上滑动时,会把所有 个通道的对应信息进行加权并 相加 。这一整套操作,最终只会生成一个二维的输出特征图(单输出通道)。
-
多个三维核 = 多个提取器:
- 既然一个三维核只能提取出一种特定的跨通道复合特征,那如果我们需要提取 种不同的复合特征怎么办?很简单,我们就准备 个完全不同的三维卷积核 。
我们可以有多个三维卷积核,每个核生成一个输出通道。
输入
核
输出
公式解析: 图中的公式 表示的就是这个过程。这里的 代表第 个三维卷积核。整个输入 跟第 个三维核做完整的卷积(包含了最后的通道求和),就得出了输出的第 个通道(一层二维特征图)。循环 次,就把所有的输出通道生成完毕了。
这就是为什么卷积核 的形状是 ——它本质上是把 个形状为 的三维卷积核打包在了一起。
输入通道数量核输出通道数量其实没有什么相关性。
多输入和输出通道
每个输出通道可以识别特定模式:
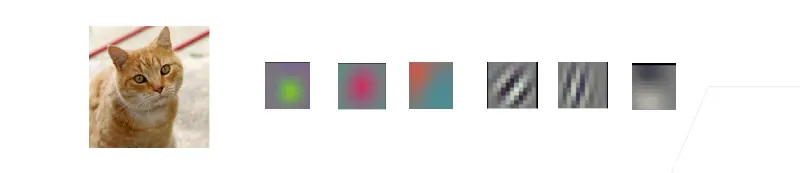
输入通道核识别并组合输入中的模式:
- 输入通道将各个通道中的结果加权相加,得到组合的模式识别。
1 x 1卷积层
1 x 1卷积层:卷积层的高和宽都等于1。它不会识别图片的空间信息,但它可以融合不同通道的信息。
本质:在单个像素点的位置上,把不同通道的信息做了一次加权融合 。
1 x 1 卷积层 vs 全连接层
卷积层的视角:
假设我们有一张特征图,高度是,宽度是,输入通道数是。
- 输入形状:
- 经过1 x 1卷积:卷积核在空间上滑动,直接输出 个通道。
- 最终输出形状:(直接就是一个完美的三维立体矩阵)。
全接连层视角:
如果我们要用全连接层来完全模拟上面的 1x1 卷积,数据需要经历三个步骤:
- 拉平空间维度:我们不是把整个输入拉成一条线,而是 只把空间的高和宽拉平 。把 个像素点排成一长列。
- 经过全连接层:全连接层的权重矩阵大小是 。二维输入矩阵 乘上权重矩阵 ,得到新的二维矩阵: 。
- 重新折起:为了让它变回图像,我们只需要把长度为 的这一列像素, 按照原本的高和宽重新排列成网格 。
经过“拉平 -> 全连接 -> 还原”这三步曲,最终得到的数据形状和具体数值,与直接用 卷积得出的结果是一模一样的。
卷积之所以优雅,就在于它 在底层自动帮我们保持了空间的网格结构 。它就像是一个自带了“拉平”和“还原”功能的空间共享全连接层,省去了我们手动变形数据的麻烦。
池化层
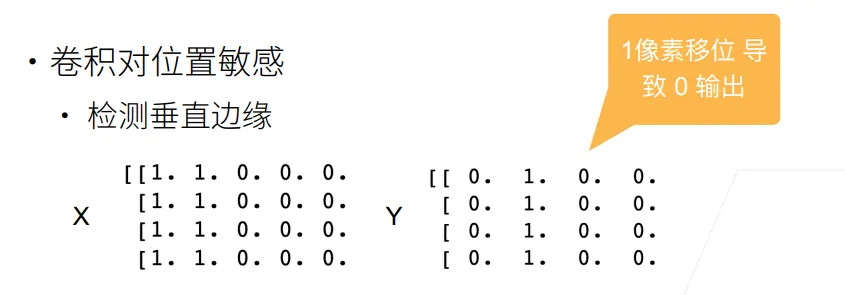
重新理解卷积层的”平移不变性”
在第一次介绍卷积层时,我们说卷积层具有平移不变性,当时我们说其物理意义如下:
无论我现在站在图片的哪个绝对位置 ,我用来观察周围偏移量 的 权重 都是同一套。
当我们说卷积层不怕平移时,我们真正指的是它的权重共享机制:
- 意思:一个用来检测垂直边缘的卷积核,不管这个边缘出现在图片的左上角还是右下角,它都能检测出来,因为同一个卷积核滑过了整张图片。
- 结果:如果输入图片里垂直边缘向右移动了一个像素,那么卷积层输出的特征图里,垂直边缘的激活值也会跟着向右移动一个像素。
为了与后续池化层的平移不变性区分,我们给卷积层的这一特性一个更加贴切的名字:卷积层的平移等变性。
那么卷积层的平移等变性会带来什么问题呢?
在前面的学习中我们了解到,卷积层的主要作用是特征提取,但是卷积层本身并没有分类/预测的作用。所以通常我们还需要在卷积层后再次引入全连接层(负责最终的分类)。
如果输入X稍微动了一下,输出Y里的那个值为1的特征也就跟着换了位置。对于后面的全连接层来说,特征出现在位置A和位置B,对它而言可能是完全不同的输入,这就导致模型很脆弱。
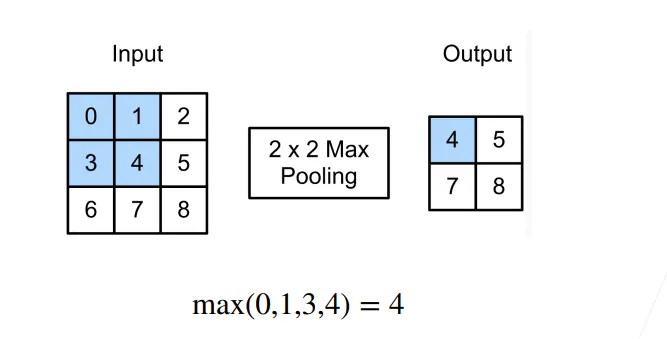
池化层
二维最大池化层
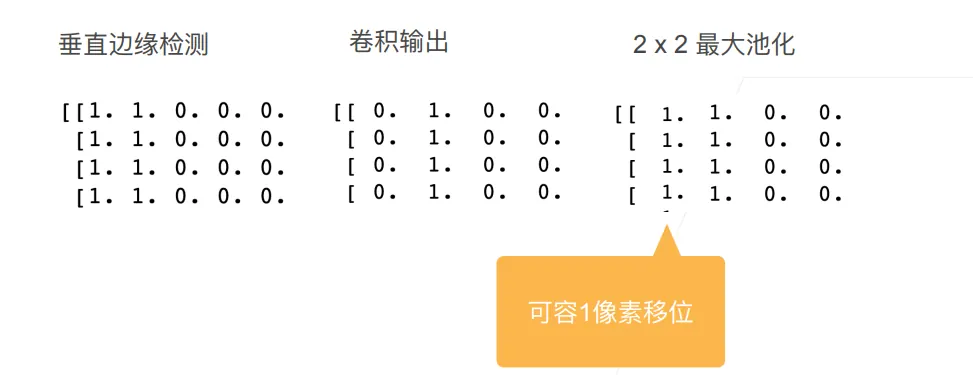
池化层才是真正用来解决“像素移位导致判断失误”的武器。
- 意思是什么? 最大池化是在一个小窗口(比如 )里选出最大值。
- 结果是什么? 假设特征图里有一个很强烈的激活值(比如数字 9)。不管这个 9 是在 窗口的左上角、右上角、还是左下角,经过 Max Pooling 之后,输出的结果 全都是 9 。
- 这就叫“不变” :输入发生了微小的平移,但池化层的输出 保持不变 。
使用池化层解决前面的问题:
平均池化层
最大池化层:每个窗口中最强的模式信号。
平均池化层:将每个池化层中的最大操作替换为平均。
池化层与卷积层
- 形式上相似:都有滑动窗口、填充和步幅
- 和卷积一样,池化操作也是拿着一个小窗口在输入的特征图上移动。
- 步幅:决定窗口每次移动的距离。
- 填充:可以在周围补0。
- 核心区别一:完全没有可学习的参数
- 卷积层 :里面的卷积核包含了一大堆权重和偏置,这些数字是未知的,需要模型在训练时通过梯度下降一步步学出来。
- 池化层 :它只是一个 定死的数学计算规则 。不管是最大池化还是平均池化,都不涉及任何需要更新的权重矩阵。它只是纯粹地在做信息的提取和压缩。
- 核心区别二:面对多通道时的独立运作
- 卷积层在多通道时是“融合”的 :一个多通道的卷积核会同时深入所有输入通道提取特征,然后把各通道算出的结果 相加 ,最终变成 1 个输出通道。
- 池化层在多通道时是“独立隔离”的 :池化层遵循“各人自扫门前雪”的原则。如果输入特征图有 64 个通道,池化层会分别且独立地在第 1 个通道上执行池化,然后在第 2 个通道上执行池化……一直到第 64 个通道。各个通道之间井水不犯河水,没有任何信息的相加或融合。

代码实现
池化运算实现:
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y使用框架提供的池化层:
pool2d = nn.MaxPool2d(3)
pool2d(X)默认情况下,深度学习框架中的步幅与汇聚窗口的大小相同。因此,如果我们使用形状为(3, 3) 的汇聚窗口,那么默认情况下,我们得到步幅形状为(3, 3)。
填充和步幅可以手动设定:
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)还可以更进一步的设置任意大小窗口的池化层,并分别设定填充和步幅的高度和宽度:
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)卷积神经网络(LeNet)
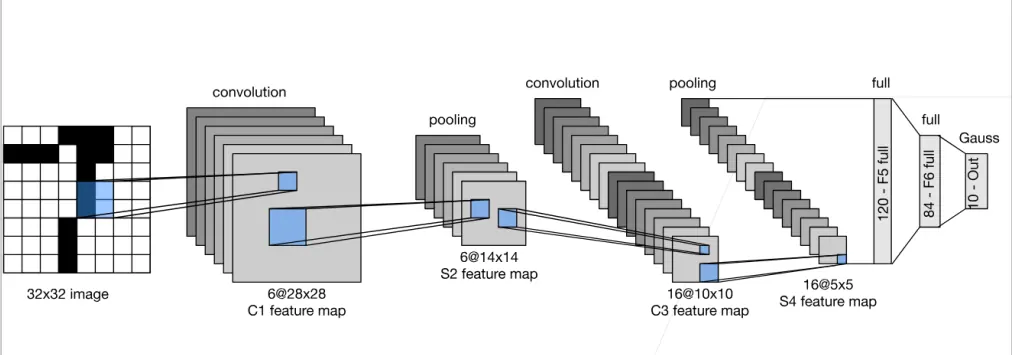
LeNet是在1998年提出的最早的卷积神经网络之一,最初被广泛应用于识别支票和信封上的手写数字。
LeNet奠定了现代卷积神经网络的基础设计模式,即卷积层提取特征 -> 池化层降维 -> 全连接层分类。
结构分析
- 输入层
- 接收一张大小为32 x 32 像素的灰度图像(通道数为1)
- 特征提取阶段
这个阶段由两个”卷积 + 池化”的模块组成,主要负责从图像中自动提取有用的特征(如边缘、形状、纹理等)
- C1卷积层(Convolution):
- 使用6个大小为5 x 5 的卷积核在图像上滑动扫描。
- 输出6张大小为28 x 28的特征图。尺寸从32缩小到28是因为卷积操作去掉了边缘。(32 - 5 + 1 = 28)
- S2池化层(Pooling):
- 对C1层的输出进行下采样(通常是2 x 2的平均池化或最大池化)
- 它将图像的长宽缩小一半,输出6张大小为14 x 14的特征图。这一步可以大幅减少计算量,并让网络对图像的轻微偏移具有一定的容忍度。
- C3卷积层(Convolution):
- 使用16个5 x 5的卷积核对前一层的输出进行更深层次的特征提取。
- 输出16张大小为 10 x 10的特征图(14 - 5 + 1 = 10)
- S4池化层(Pooling):
- 再次进行2 x 2的下采样
- 输出16张大小为 5 x 5的特征图
- C1卷积层(Convolution):
- 分类阶段
提取完高维特征后,网络需要将这些特征综合起来,做出最终的判断。在进入全连接层之前,S4层的输出(16张 5 x 5的图)会被展平成一个一维向量(包含16 x 5 x 5 = 400个数值)。
- F5全连接层(Full):包含12个神经元,与上一层的400个节点全连接
- F6全连接层(Full):包含84个神经元。
- 输出层:包含10个神经元,分别代表数字0到9。
图中输出层使用”Gauss”代表径向基函数连接。但是在现代的深度学习实现中,这一层通常被替换为Softmax激活函数,用来直接输出这张图片属于每个数字的概率。
代码
定义LeNet:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))可以看出使用深度学习框架实现此类模型非常简单。我们只需要实例化一个Sequential块并将需要的层连接在一起。
现在我们已经实现了LeNet,让我们看看LeNet在Fashion-MNIST数据集上的表现:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)使用GPU计算模型准确度:
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]训练函数:
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')最终训练LeNet-5模型:
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())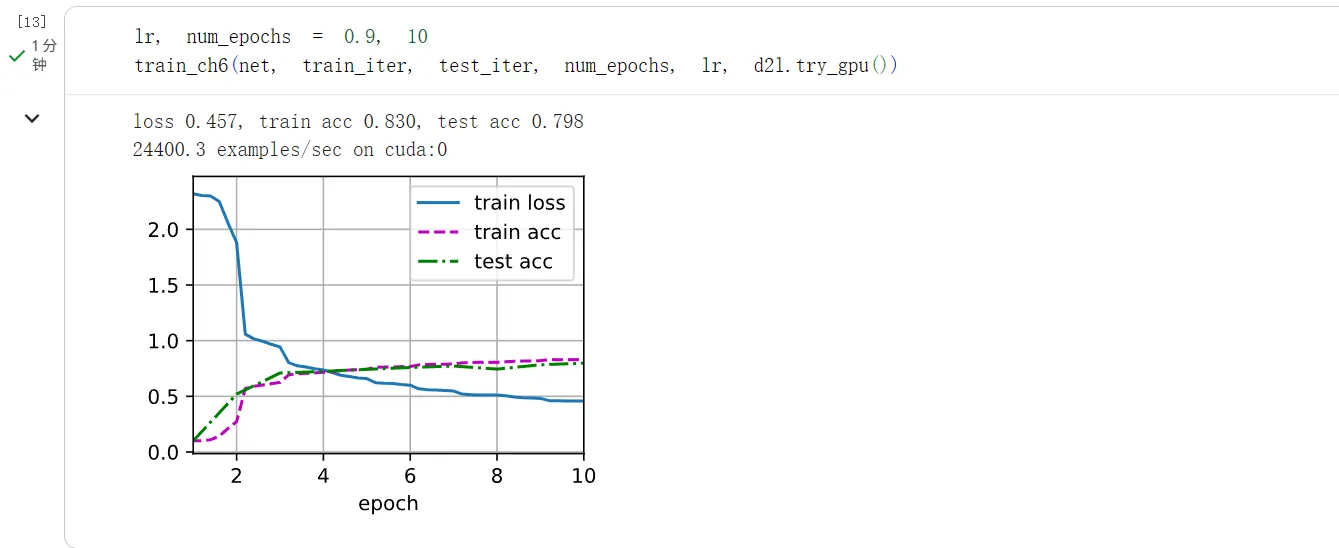
当前模型的训练误差和测试误差相差无几,则当前模型可能存在欠拟合。
当前模型优化的方向可以尝试增大模型容量。
简单优化增大模型容量:
net = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 48, kernel_size=5), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(48 * 5 * 5, 256), nn.ReLU(),
nn.Linear(256, 128), nn.ReLU(),
nn.Linear(128, 64), nn.ReLU(),
nn.Linear(64, 10))我调大了模型容量,并在最后又手动增加了一个全连接层。
训练:
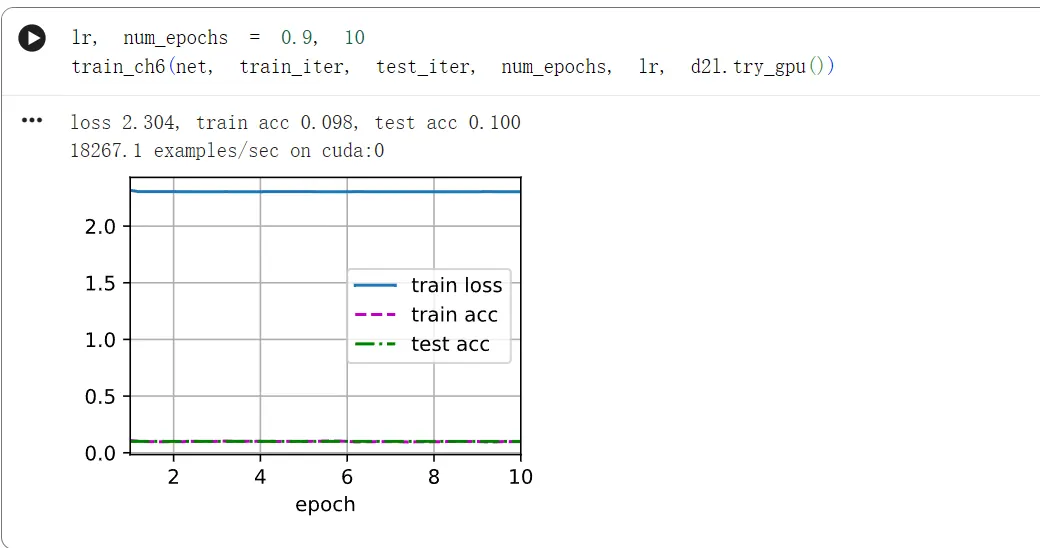
这里出现了一个经典的现象:ReLU神经元坏死
简单解释一下:ReLU 的定义是 。它的导数(梯度)非常特殊:
- 如果 ,梯度是 。
- 如果 ,梯度是 0。
罪魁祸首出现在上:
- 在训练的第一轮、第一个批次,由于使用了高达0.9的学习率,一个巨大的参数更新步伐迈了出来。
- 不幸的是,这个巨大的步伐把网络中绝大多数甚至全部神经元的参数(权重和偏执)推向了一个状态:使得对于当前和未来的所有训练样本,这些神经元的净输入全部小于0。
- 一旦输入变成负数,ReLU的输出就是0,而且最致命的是,它的梯度就永远变成了0。
将学习率减小为0.05,同时增加训练轮数:
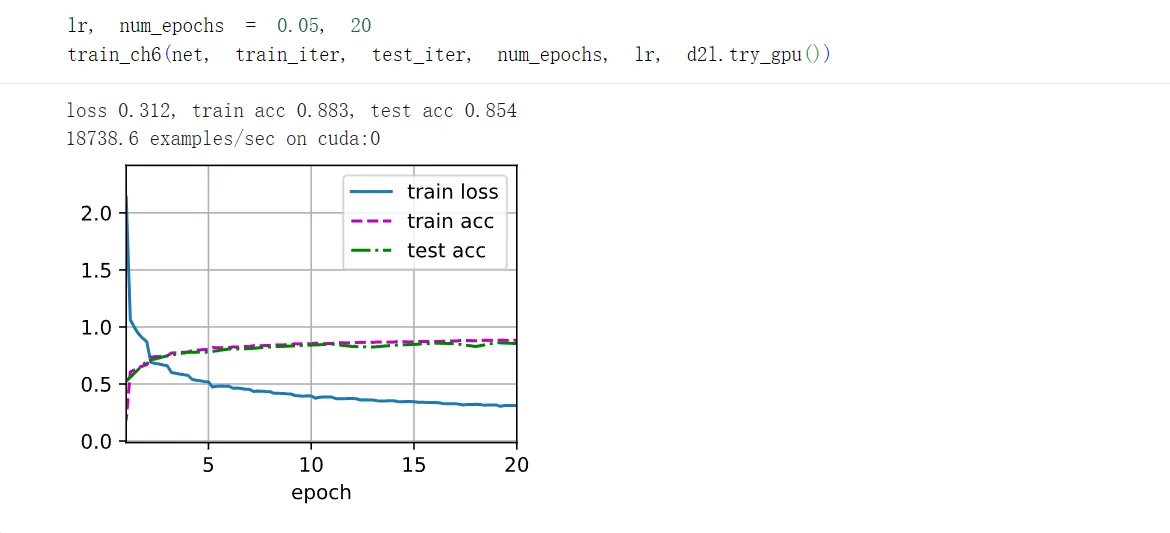
至少我们可以明显看出这次的优化是有效果的,通过增加模型容量,我们准确率从:80%提升到了85%。