信任是昂贵的,别指望在廉价的人身上找到它。—— 沃伦·巴菲特
从全连接层到卷积
分类猫和狗的图片
使用一个还不错的相机采样图片(12M像素),则RGB图片有36M元素。
使用100大小的单隐藏层MLP,模型有3.6B元素。实际上这个数字远大于世界上所有的猫和狗的总数。(900M狗,600M猫)
100 * 36M = 3.6B

如果要存储3.6B的参数,大约需要14GB的内存。想要训练这个模型将不可实现,因为需要有大量的GPU、分布式优化训练的经验和超乎常人的耐心。
图片识别的两个原则:
- 平移不变性:不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
- 局部性:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。

重新考察全连接层
不改变全连接层的本质,只改变我们观察它的视角。
核心目标:保留图像的 2D 空间结构,将全连接层的公式重写为基于“相对位置(偏移量)”的形式。
在之前我们处理Fashion-MNIST数据集时,我们将一张2D图片(28 X 28)拉平成一个1D的长向量。这样做的代价是彻底破坏了图像的空间结构。
但是现在我们不能拉平:
- 让输入X保持2D矩阵形状
X[k][l] - 让隐藏层输出H也保持2D矩阵形状
H[i][j]
现在我们的目标是,要怎么计算出图片中某个特定位置(i, j)的像素值。
绝对位置视角
在全连接层中,为了计算输出图上的哪怕一个点,我也必须把输出图上的所有点都看一遍。
用伪代码来写,表达如下:
# 假设我们要计算输出图上坐标为 (i, j) 的这个点 H[i][j]
sum = 0
# 遍历输入图上的每一个绝对坐标 (k, l)
for k in range(image_height):
for l in range(image_width):
# 拿到输入图上 (k, l) 位置的像素值 X[k][l]
# 乘以对应的权重 W
sum += W[i][j][k][l] * X[k][l]
H[i][j] = sum这里的
W[i][j][k][l]就是 4D 张量。
相对距离视角
其实什么都没有变,只是换了一种说话方式:
与其说“去拿绝对坐标 (k, l) 的像素”,不如说“以我现在的位置 (i, j) 为中心,去拿偏移了 (a, b) 距离的像素”。
- 在横轴上:原本的
k变成了i + a(当前位置向右偏 a) - 在纵轴上:原本的
l变成了j + b(当前位置向下偏 b)
伪代码如下:
# 依然是计算输出图上坐标为 (i, j) 的这个点 H[i][j]
sum = 0
# 这次我们不遍历绝对坐标了,我们遍历“偏移量” (a, b)
# 假设偏移量可以是从图的最左边到最右边,最上边到最下边
for a in range(-image_height, image_height):
for b in range(-image_width, image_width):
# 我们站在 (i, j) 的位置,拿到偏移 (a, b) 后的像素值 X[i+a][j+b]
# 乘以对应的权重 V
sum += V[i][j][a][b] * X[i+a][j+b]
H[i][j] = sum相对视角有什么意义呢?
想象一下,如果你要判断输出点
(i, j)是不是猫的眼睛。你需要看整张输入图片吗?不需要!你只需要看(i, j)附近的几个像素点就够了。也就是说,上面伪代码里的偏移量
a和b,根本不需要跑遍整张图片(从-image_height到image_height)。我们只需要让a和b在一个小范围(比如-1, 0, 1)里循环就可以了。
平移不变性
在图像中,x的平移会导致h的平移:
由于为了满足平移不变性:v不应该依赖于(i, j)。
为了解决这个问题,我们必须添加一个限制:
它的物理意义是:
- 无论我现在站在图片的哪个绝对位置 ,我用来观察周围偏移量 的 权重 都是同一套。
局部性
当评估时,我们不应该用远离的参数。
解决方法:当 时,使得
(Delta),在这里可以被理解为最大视距或者视野的半径。
最终的2D卷积公式:
如果用代码表示:查找表变成了一个小巧的滑动窗口(卷积核)
# 假设 Delta = 1,我们的感受野半径是 1
# 那么窗口的宽度就是 1 + 1 + 1 = 3,这就是经典的 3x3 卷积核
for i in range(image_height):
for j in range(image_width):
sum = 0
# 这里的循环不再是全图,而是被严格限制在了 -1 到 1 之间
for a in range(-1, 2):
for b in range(-1, 2):
# 只有这 3x3 = 9 个像素会参与计算!
sum += v_a_b[a][b] * X[i+a][j+b]
H[i][j] = sum总结
回到你最开始那张猫狗分类的 PPT。如果不加限制(全连接 MLP),我们需要 36亿 个参数。
但是,通过这两页 PPT 的推导:
- 平移不变性 :让全图共享同一套权重,不需要每个像素点都配一套。
- 局部性 :让这套权重的作用范围限制在一个极小的 窗口里(比如 )。
原本 36 亿个参数,现在 仅仅只需要 9 个参数 (也就是 在 窗口里的值)
图像卷积
互相关运算
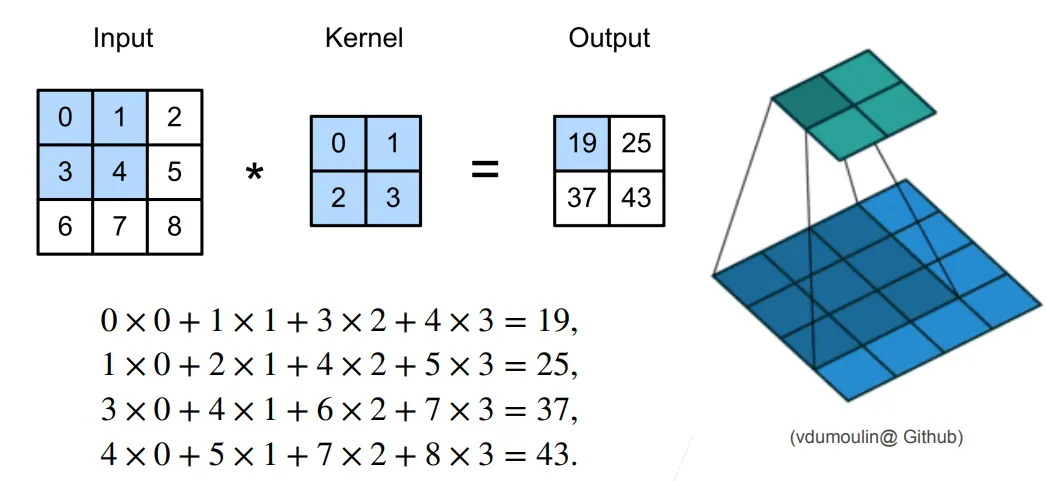
二维卷积层:
- 输入:
- 核:
- 偏差:
- 输出:
- 和 是可学习的参数
不同核运算的不同效果

交叉相关 VS 卷积
二维交叉相关:
二维卷积:
注意这里的 !在严谨的数学信号处理中,“卷积”是要求把权重矩阵(也就是滤波器) 先上下翻转,再左右翻转(相当于旋转 180 度) ,然后才能贴到图像上去做乘加运算。
- 在传统的图像处理里,这些权重是科学家手动设计好的(比如专门用来找边缘的 Sobel 算子),翻转了效果就不对了。
- 但在深度学习里,权重矩阵 里面的值是随机初始化的,然后 让神经网络自己通过反向传播(Backpropagation)学出来的
既然是学出来的,网络完全有能力自己把那个“翻转”的过程给吸收掉。
代码实现
二维互相关运算:
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y实现二维卷积层:
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias图像中的目标边缘检测
这是一个卷积层的一个简单应用:通过找到像素变化的位置,来检测图像中不同颜色的边缘。首先,我们构造一个简单黑白图像:
X = torch.ones((6, 8))
X[:, 2:6] = 0
Xtensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])中间四列为黑色0,其余像素为白色。
接下来构造卷积核:
K = torch.tensor([[1.0, -1.0]])现在,我们对参数和卷积核进行互相关运算:
Y = corr2d(X, K)
Ytensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])学习卷积核
当我们无法手动设计滤波器时,我们可以学习由X生成Y的卷积核:
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')在10次迭代之后,误差已经降到足够低。现在我们来看看我们所学的卷积核的权重张量。
conv2d.weight.data.reshape((1, 2))tensor([[ 1.0010, -0.9739]])这与我们之前手动指定的卷积核非常相近。