从零入门图神经网络
发布于
岁岁无虞,长安长乐
原文链接:A Gentle Introduction to Graph Neural Networks
什么是图
图是用来表示一些实体之间的关系。
- 实体:点
- 关系:边
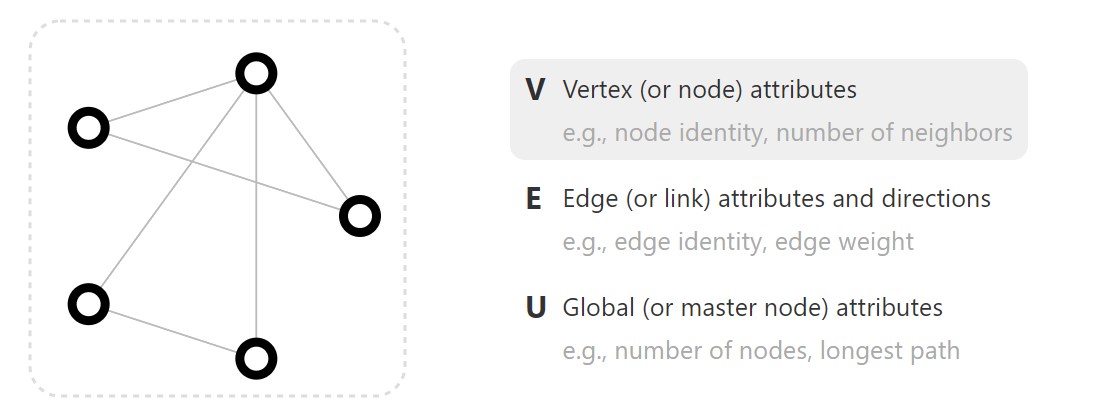
V :顶点属性
E :边属性和方向
U :表示全局信息,代表整个图
attribute :表示每个顶点,每条边和整个图表示的信息。这些信息是我们所关心的内容。
为了进一步描述每个节点、边或整个图,我们可以在图的每个部分中存储信息。
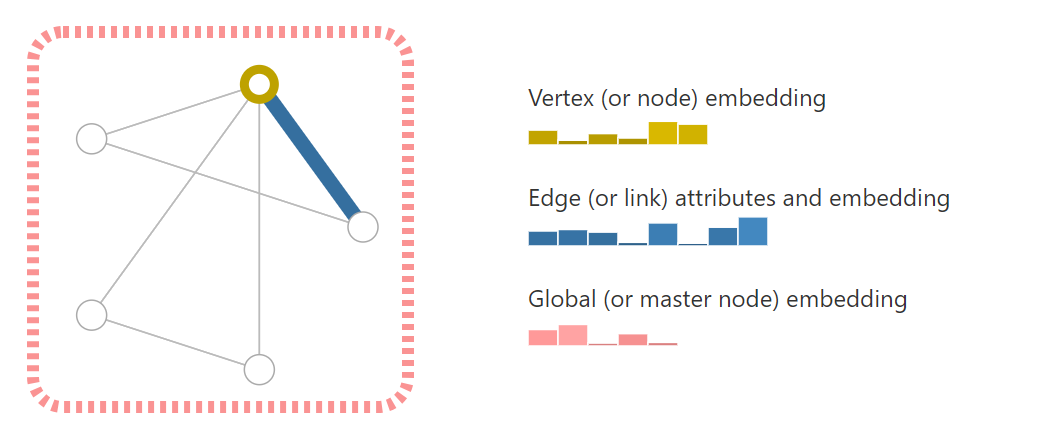
顶点:可以使用向量来表示。图中顶点有6个值,高矮代表大小。
边:可以使用不同的向量来表示。图中边使用一个长度为8的向量表示。
全局信息:使用一个长度为5的向量表示。
图神经网络的核心:
- 我们怎么样把我们想要的信息表示成这些向量。
- 这些向量是否能够通过数据来学到。

图可以分为有向图和无方向的图。
- 有向图:github的Follow关系。
- 无向图:微信好友关系。
数据是如何表示成图的
图片如何表示成图
假设我们有一张图(244x244x3),一般我们会把它表示为一个三个维度的Tensor。
从另一个维度来看,我们将把它视作一张图,每个像素就是一个点,如果像素之间是邻接关系则连接一条边。
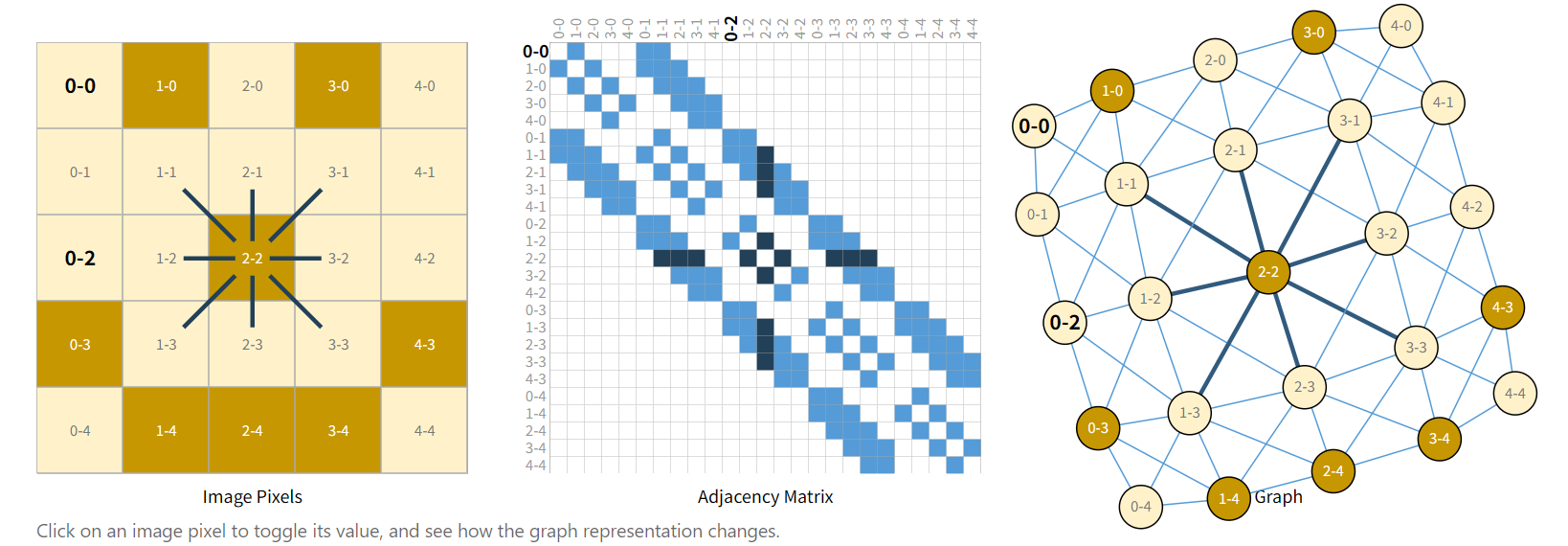
- 左侧:图像像素
- 中间:邻接矩阵
- 右侧:图
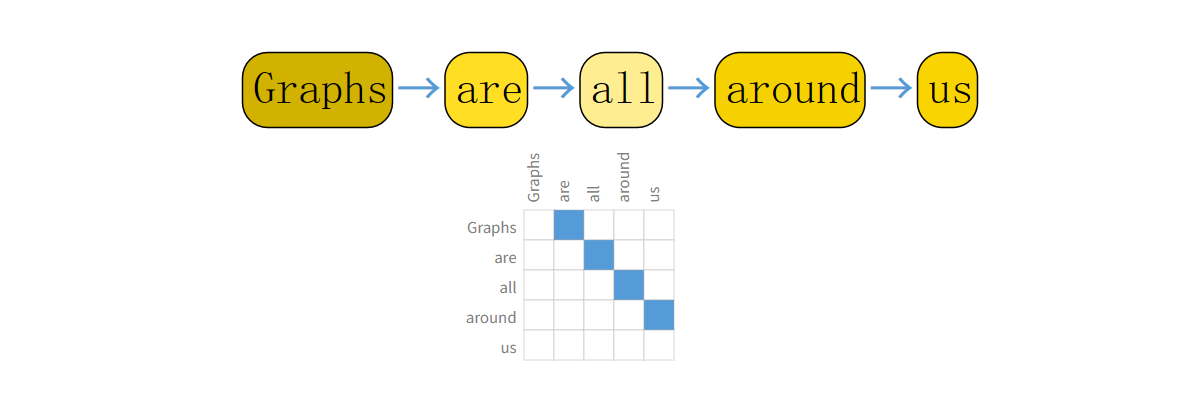
文本如何表示成图
文本可以认为是一条序列,我们可以把每一个词当作一个顶点。一个词和下一个词之间,有一条有向边。
广阔的图数据世界
除了上述列出的两种数据可以表示为图,还有很多别的数据可以表示为图。
分子表示为图
把每一个原子作为一个顶点,而分子间的共价键作为边。

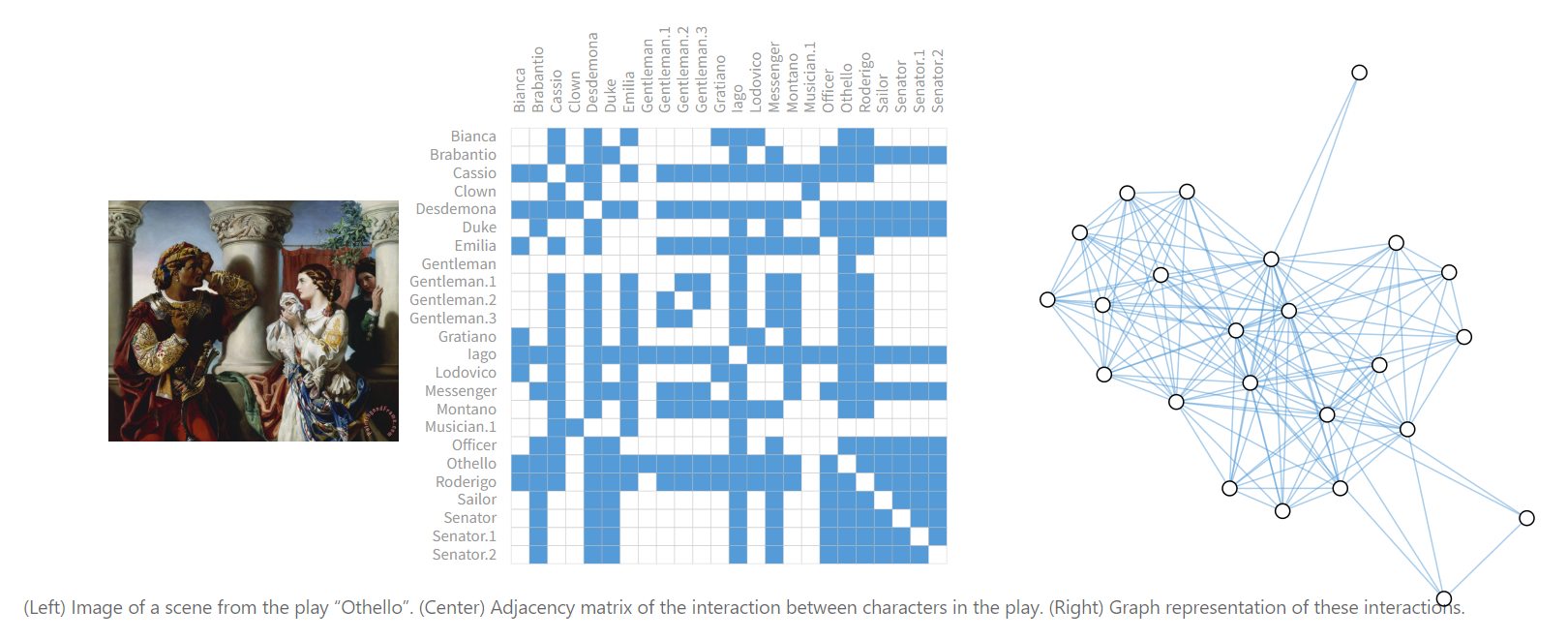
社交网络
社交网络是研究个人、机构和组织集体行为模式的工具。我们可以构建一个图来表示人群,将个体建模为节点,将个体之间的关系建模为边。
引用网络图
科学家在发表论文时经常引用其他科学家的工作。我们可以将这些引用网络可视化为一个图,其中每篇论文都是一个节点,每个有向边是一篇论文与另一篇论文之间的引用。
图结构化适用的问题
图级别任务
在图级别任务中,我们的目标是预测整个图的属性。例如,对于一个用图表示的分子,我们可能想要预测该分子的气味,或者它是否会与某种疾病相关的受体结合。
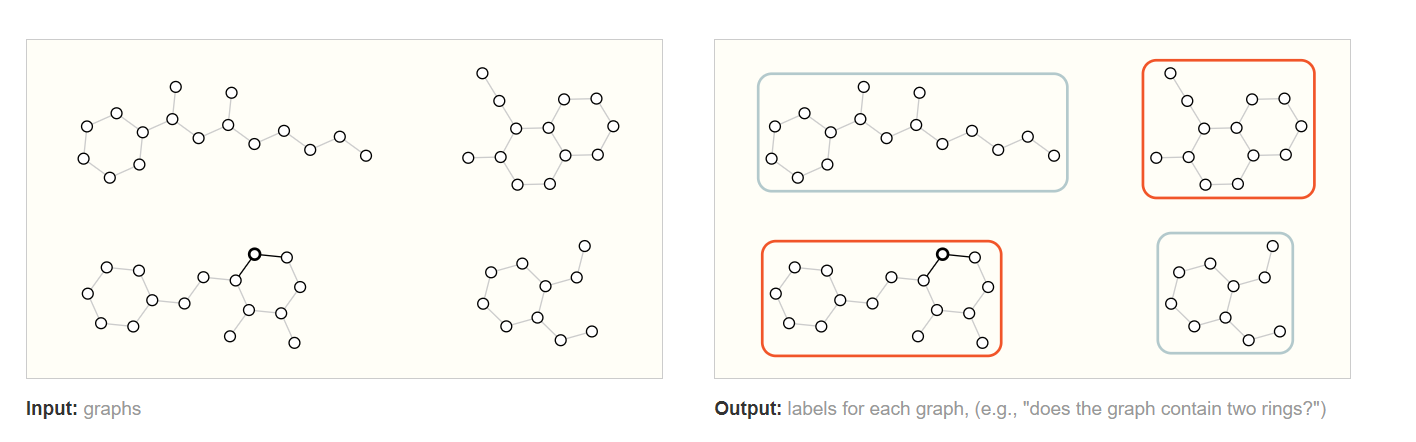
这是一个简单的图分类,按照图中环的数量进行分类
顶点层面的任务
顶点级任务关注的是预测图中每个节点的身份或角色。
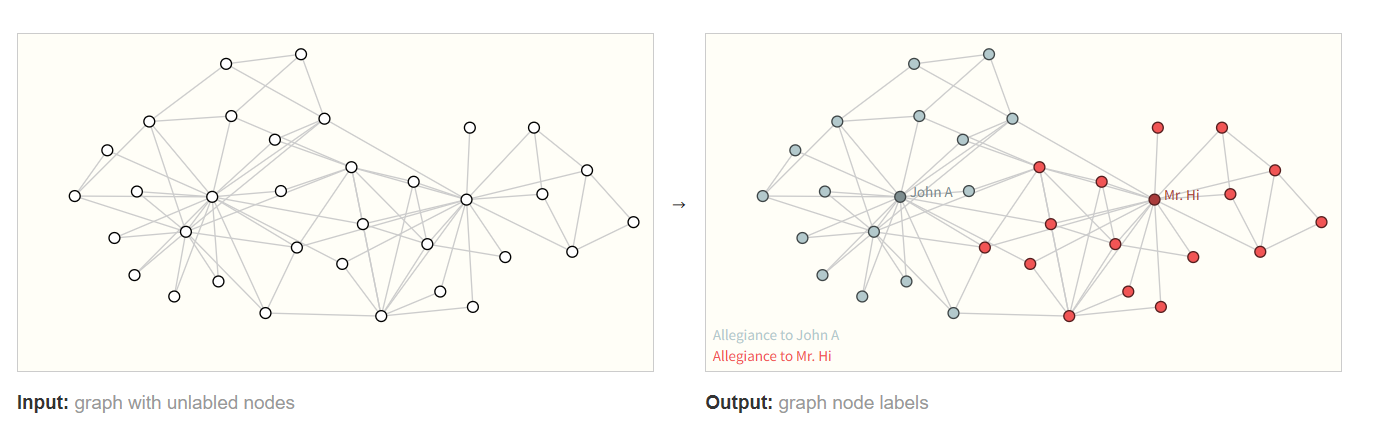
在训练道场的两个老师决裂了,所有的学生必须要选择一个老师进行跟随。
通过学生和老师之间的比赛图,判断学生会跟随老师A还是老师B
边级别上的任务
边级问题是指以图中两个节点之间的关系或连接为研究对象的预测任务。
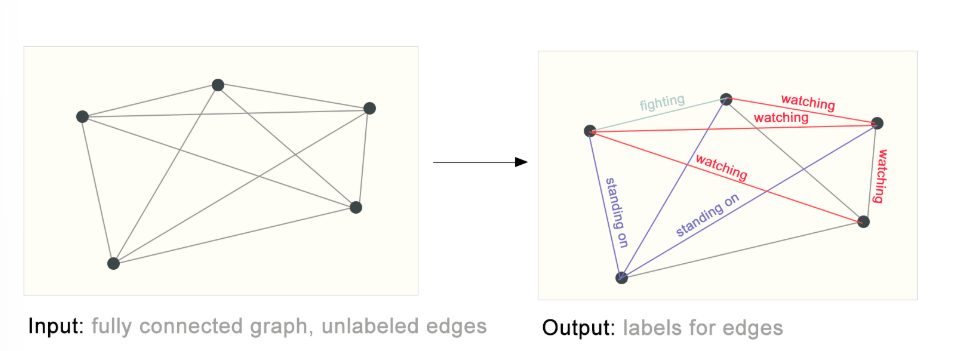
给出一个确定的图,来预测边上的属性。
机器学习运用在图上的挑战
如何将图表示为与神经网络兼容的格式
在图中,我们需要利用四种类型的信息来进行预测:节点(Nodes)、边(Edges)、全局上下文(Global-context)和连通性(Connectivity)。
前三者相对容易处理:例如,对于节点,我们可以给每个节点分配一个索引,并将节点的特征存储在矩阵中,从而形成节点特征矩阵。尽管这些矩阵的样本数量是可变的,但它们不需要特殊技术即可直接处理。
而图的连接性要复杂的多:
-
空间效率低下(稀疏性问题)
最显而易见的选择是使用 邻接矩阵(Adjacency Matrix) ,因为它易于张量化(Tensorisable)。但这种表示方法存在明显的弊端。稀疏矩阵不利于在GPU上计算,在GPU上计算稀疏矩阵一直是一个比较难的技术问题。
-
置换不变性挑战
另一个问题是, 同一种连通结构可以由多种不同的邻接矩阵来编码 。我们无法保证深度神经网络对这些不同的矩阵输入能产生相同的结果(也就是说,它们不具备置换不变性)。
学习“置换不变操作”是近年来的研究热点。
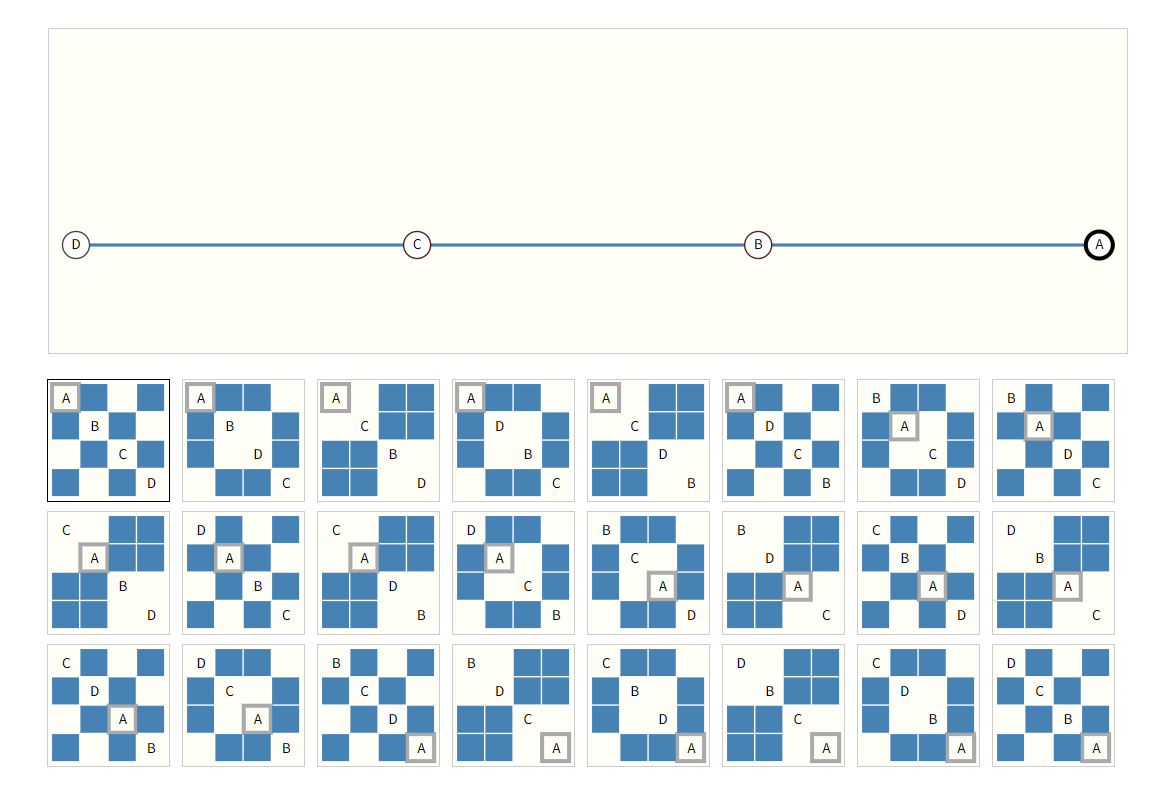
随意的交换邻接矩阵的行和列,都不会影响图的含义。
标准的表示形式
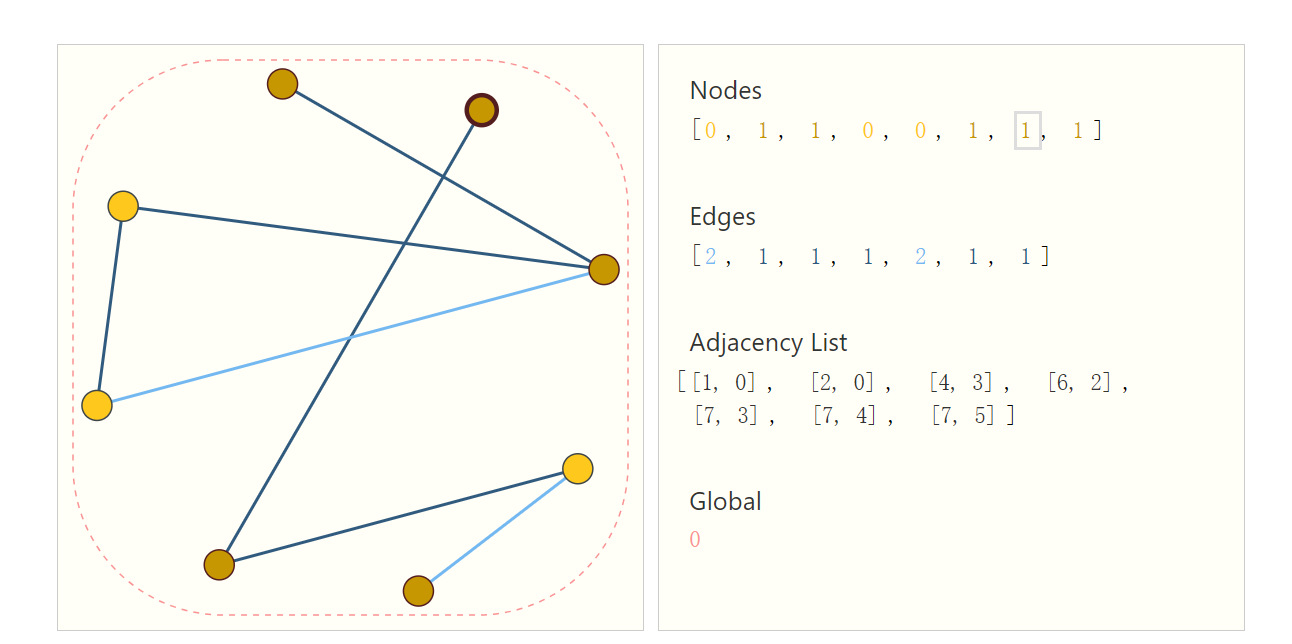
在该图中,顶点和边的属性都适用标量来表示,也可以使用向量。
- Adjacency Lsit:邻接列表
- 邻接列表长度与图的边数相等
- 它的第项表示第条边连接的哪两个节点
该表示方法的优势:
- 存储高效
- 顺序无关
Graph Neural Networks
GNN是一个对图上所有的属性(包括顶点、边和全局上下文)进行的一个可以优化的变换,并且这个变换可保留图对称性。
我们使用”消息传递的图神经网络”来构建GNN。GNN采用”图输入、图输出”架构,这意味着这些模型类型接收图作为输入,将信息加载到其节点、边和全局上下文中,并逐步转化这些向量,而不改变图的连接性。
最简单的GNN
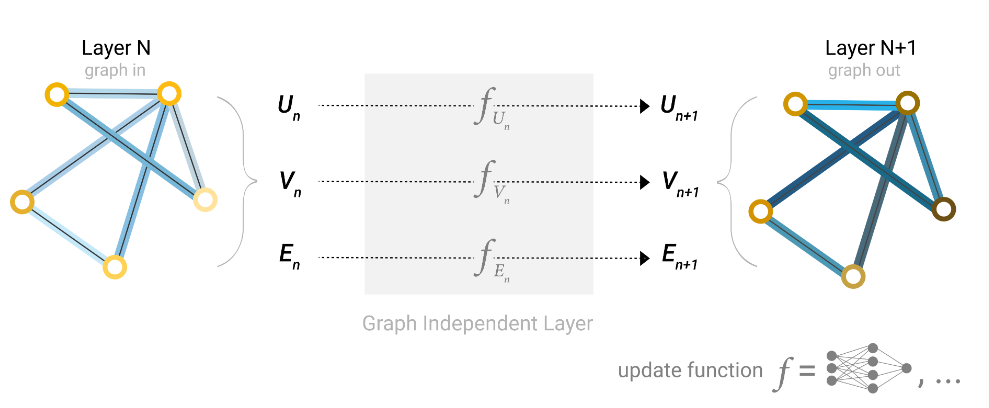
对于全局向量、顶点向量、边向量分别构建一个MLP,这三个MLP就组成了一个GNN的层。
作用:对于顶点的向量,边的向量和全局的向量分别找到对应的MLP,然后放进去得到输出作为对应的更新。
- 经过一次更新后,图中所有的属性都是被更新过的,但是整个图的结构没有发生变化。
- MLP是对每一个向量独自作用的,不会考虑所有的连接信息,所有无论顶点如何排序,都不会改变结果。
如何使用GNN进行预测
对顶点进行预测
使用GNN进行预测与一般的神经网络没有太多区别。
以二分类问题为例,由于图中的顶点已经包含向量表示,我们只需要在GNN后添加一个输出维度为2的全连接层,再使用softmax就可以得到二分类输出。
如果是n分类问题,则添加输出维度为n的全连接层。
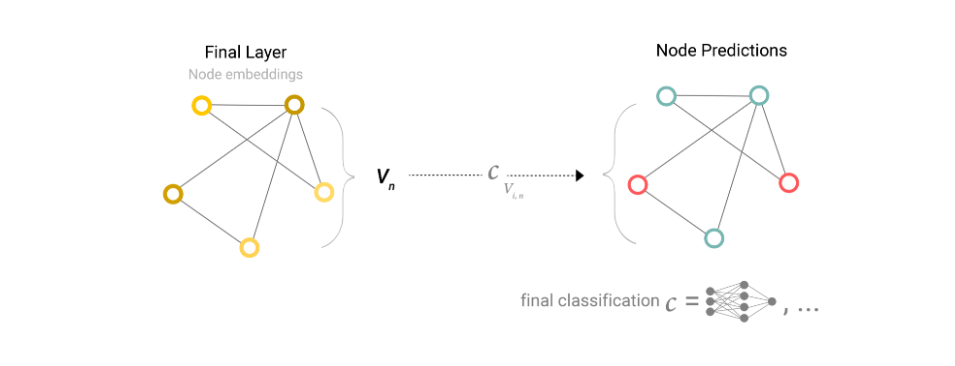
不管有多少顶点,只有一个全连接层,所有的顶点共享一个全连接层。
pooling技术(汇聚)
如果我们依旧想对一个顶点做预测,但是我们并没有这个顶点的向量。
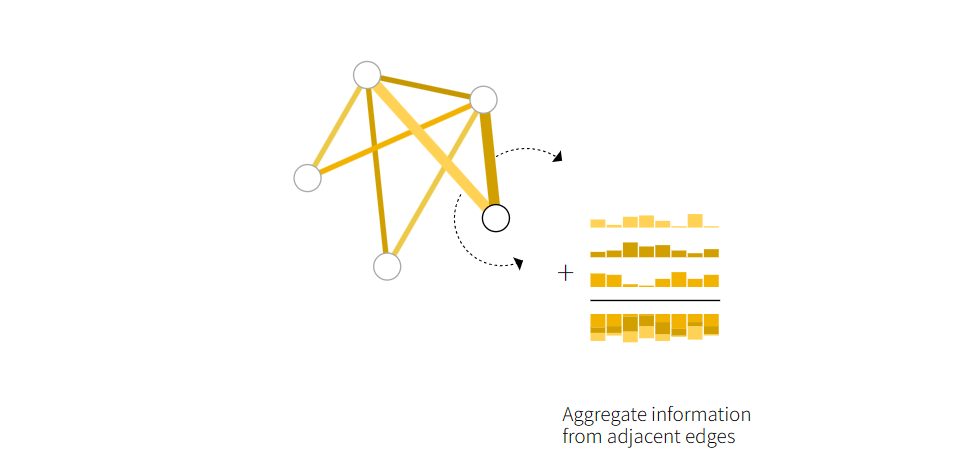
我们可以将与点连接的所有边的向量拿出来,同时把全局的向量拿出来。把这些向量全部加起来用来代表这个点的向量。
示意图:
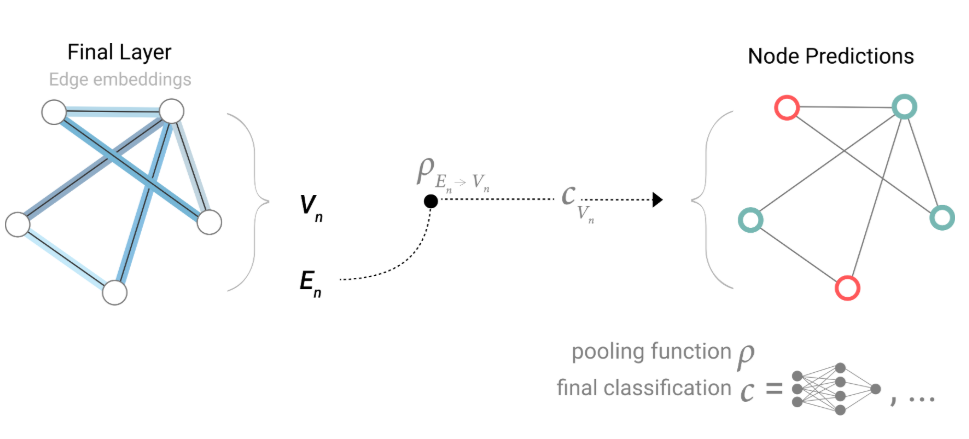
- 通过一个汇聚层让信息从边到顶点
- 最后让向量输入到顶点共享的输出层
- 得到顶点的输出
如果我们有顶点的向量,却没有边的向量,却想要对每个边做预测的话,我们就将顶点的向量汇聚到边上。
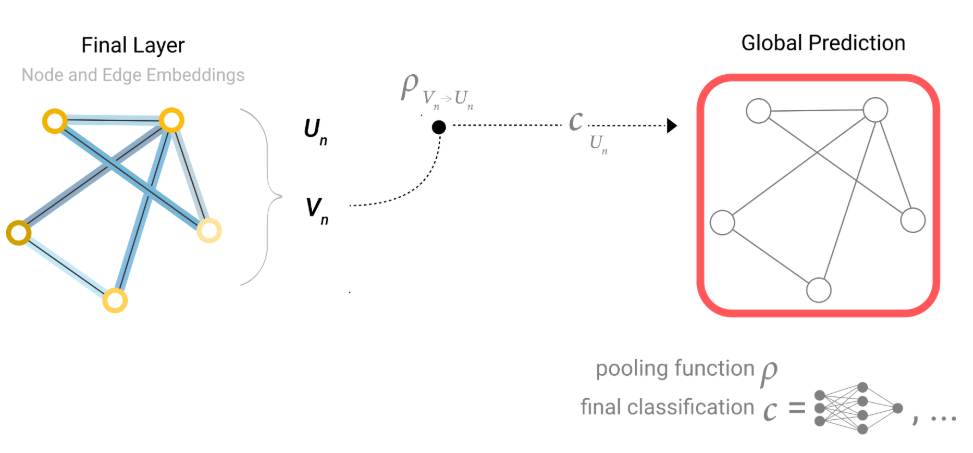
如果我们有顶点的向量,却没有全局的向量,却想对整个图做预测,我们将所有的顶点向量相加作为全局向量。
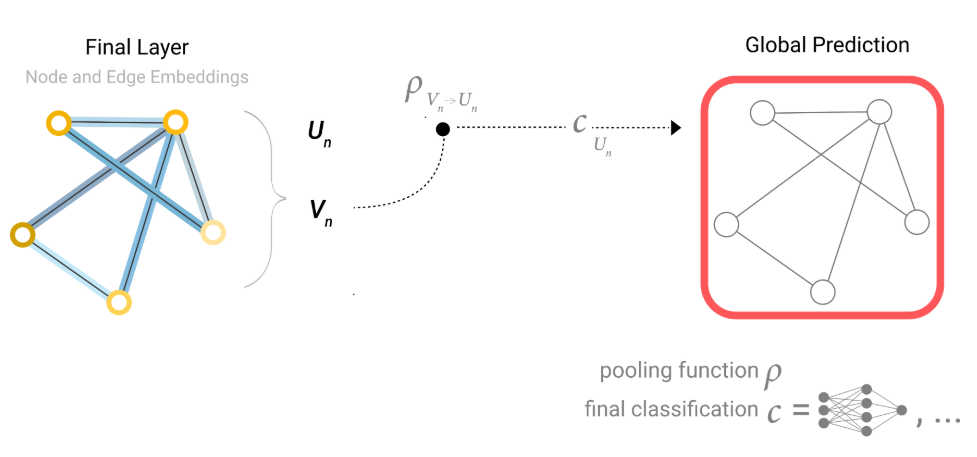
总结
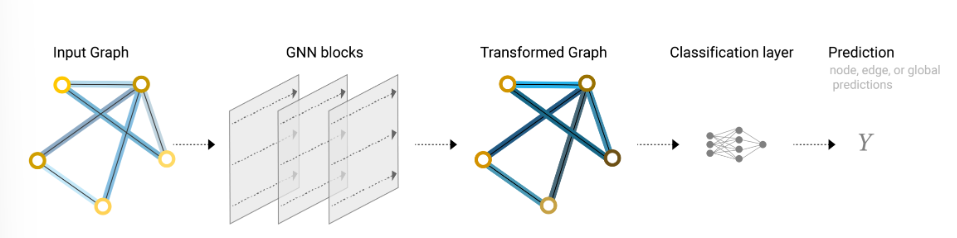
一个完整的端到端GNN简单预测流程如下:
- Input Graph:带有初始特征的节点、边和全局信息的原始图
- GNN blocks(GNN模块):经过一系列转换层。(当前图中的虚线表示对于顶点、边、和全局信息分别进行独立的线性或非线性变换)
- Transformed Graph:特征被更新后的图
- Classification layer:经过一个MLP或全连接层,将特征映射到任务所需的输出空间。
- Prediction:得到最终结果Y
虽然这个情况很简单,但是这个模型有很大的局限性,在GNN blocks时,我们并没有使用图的结构信息。导致我们最后的预测结果可能无法充分利用图的所有信息。
信息传递
消息传递的步骤:
- 对于图中的每个节点,收集所有相邻节点的向量
- 通过聚合函数(如sum)进行聚合
- 把所有聚合的向量进入MLP进行更新
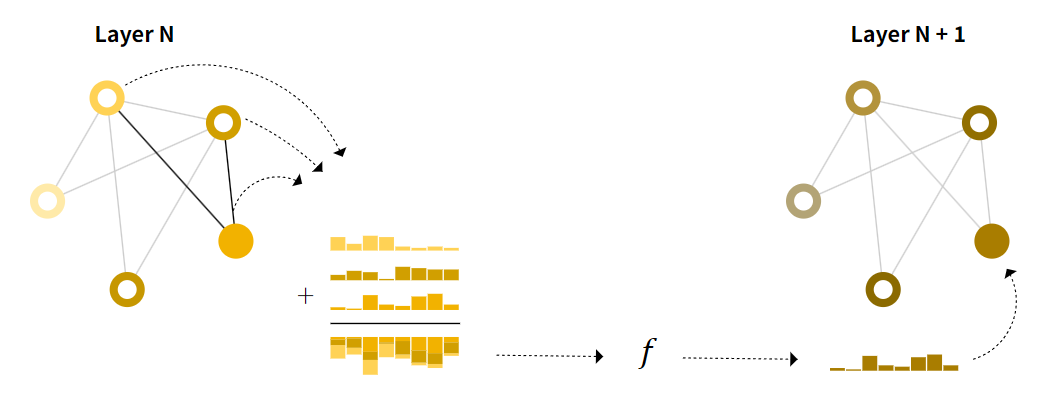
通过将消息传递GNN层堆叠在一起,节点最终可以合并整个图中的信息;经过三层后,节点拥有有关距它三步远的节点的信息。
我们可以通过一个记号表示上述信息传递过程:
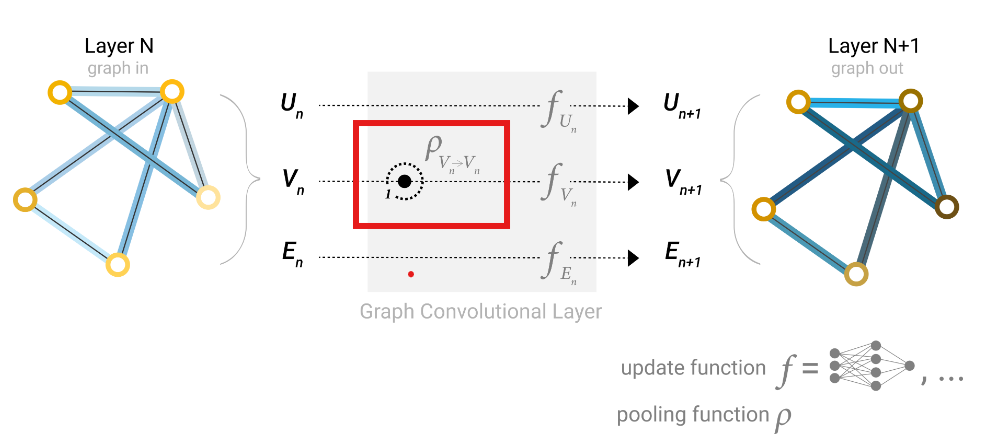
顶点之间通过1近邻来进行消息汇聚
学习边缘表示
在之前的学习中,如果我们缺失某一些属性,我们会从别的属性汇聚过来,来弥补这个属性。
我们不一定只能在最后一步,即输出层之前进行汇聚。而是可以在比较早的时候,就在顶点和边之间信息进行汇聚。
第一个例子:
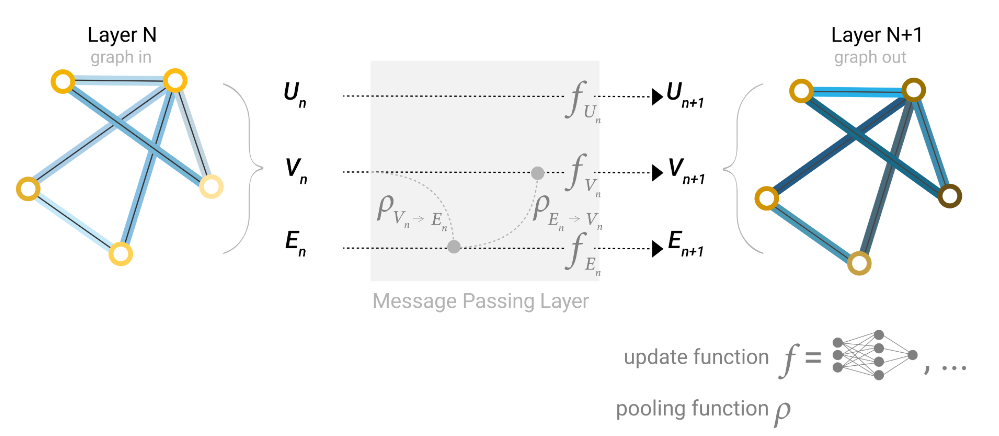
- 通过把顶点的向量传递给边
如果维度不一样需要投影
- 边特征更新
- 通过把更新后的边的向量传递给顶点
- 顶点特征更新
- 全局状态更新
如果我们更改汇聚顺序,如先从边汇聚到顶点,则会得到不一样的结论。
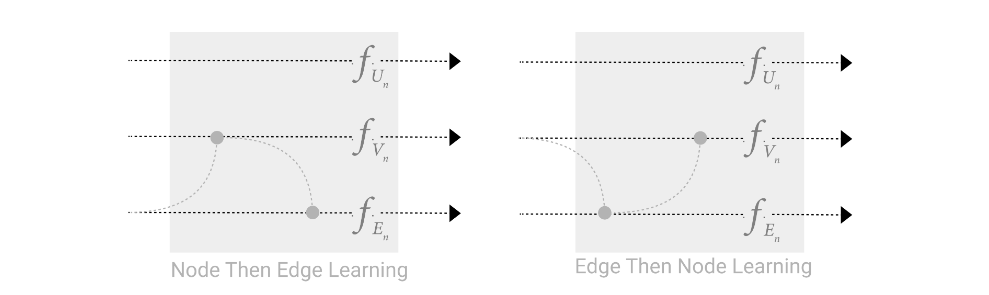
两种顺序并没有优劣之分,只是结果不同
交替更新:
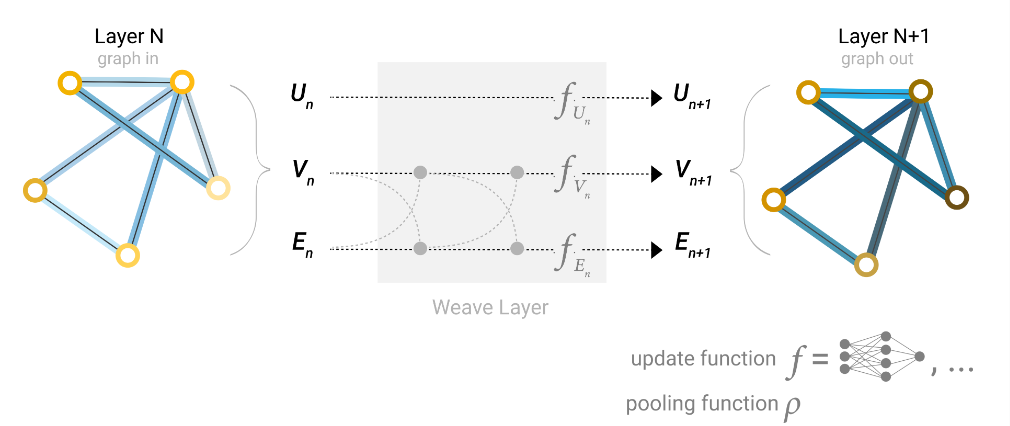
第一轮交织:
- 生成中间节点状态:系统同时提取节点自身的当前特征和与其相连的边特征,将两者汇聚。
- 生成中间边状态:同步地,系统提取边自身的当前特征和与其相连的节点特征,将两者汇聚。
第二轮交织:
- 节点聚合边的新状态:将第一步生成的”中间节点状态”与”中间边状态”再次进行交叉汇聚,作为节点更新函数的输入。
- 边聚合节点的新状态:将第一步生成的”中间边状态”与”中间节点状态”也再次交叉汇聚,作为边更新函数的输入。
最终更新:
- 经过极其充分的混合后,数据被送入神经网络(如多层感知机 MLP) 和 中,输出下一层 的最终特征 和 。全局特征 在这张图中则是独立更新为 。
优势:
- 边特征表达能力强
- 更密集的特征交互
- 对称美学与架构通用性
全局信息
到目前位置,我们描述的网络都存在一个缺陷:如果我们的图真的比较大,即使我们多次应用消息传递,图中彼此相距较远的节点也可能永远无法有效地相互传输信息。
为了解决这个问题,我们加入一个叫做master node(context vector)的点,这个点是一个虚拟的点,与所有的顶点相连,与所有的边相连。可以充当它们之间传递信息的桥梁,构建整个图的表示。
这个master node就是图的全局表示(U)。
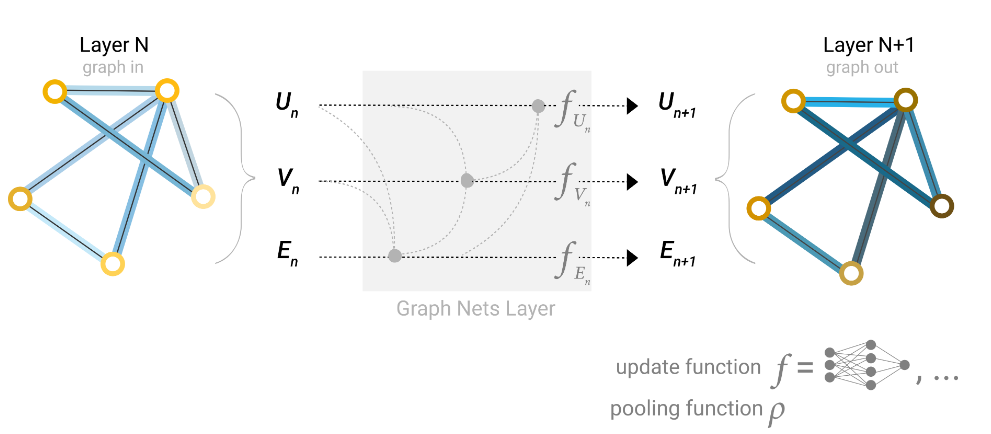
- 当把顶点的信息汇聚给边的时候,也会将U汇聚过去,因为U是与边相连的
- 当把边的信息汇聚给顶点时,也会将U汇聚,因为U是与所有顶点相连的
- 更新全局信息U的时候,会汇聚所有的顶点信息和边的信息
超参数对于精度的解释
作者在网页中嵌入了一个GNN的训练程序,并且使用了一个比较小的分子图的预测数据集进行训练,我们可以调节不同的超参数,来体验一下不同超参数的实际训练效果。
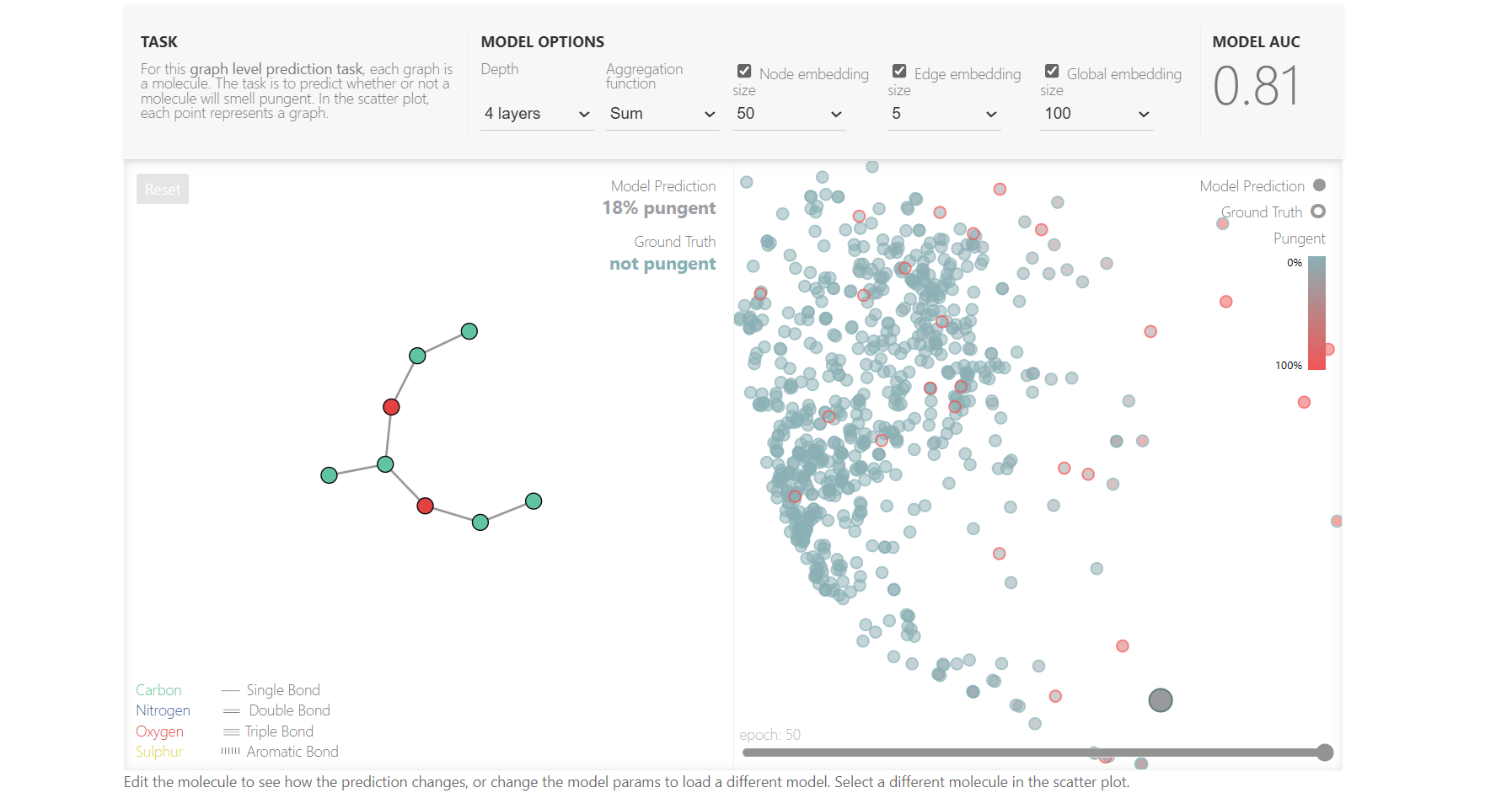
可选参数:
- 网络的层数
- 聚合函数(SUM、MEAN、MAX)
- 顶点、边、全局向量的维度
AUC是什么?
AUC 的全称是 Area Under the ROC Curve (ROC 曲线下的面积)。但抛开曲线不论,AUC 在数学上有一个极其直观的概率学解释:
假设你让模型对样本进行打分,你随机挑出一个“真正的正样本”和一个“真正的负样本”,模型给“正样本”打分高于“负样本”的概率,就是 AUC。
- AUC = 1.0 :完美模型。它给所有正样本的打分都比负样本高。
- AUC = 0.5 :瞎蒙模型。相当于抛硬币,模型根本分不清正负样本。
- AUC < 0.5 :比瞎蒙还差(通常说明你的模型把正负类搞反了,反向预测一下就能大于 0.5)。
通常,一个优秀的模型 AUC 会在 0.8 到 0.95 之间。我们在文末继续详细介绍AUC的数学定义。
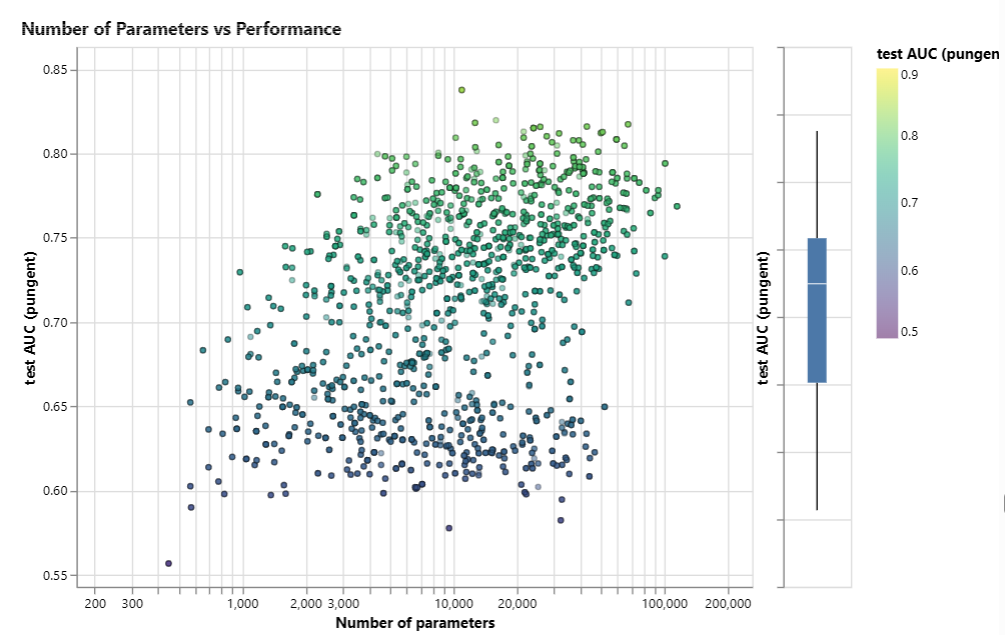
模型大小对于AUC的影响
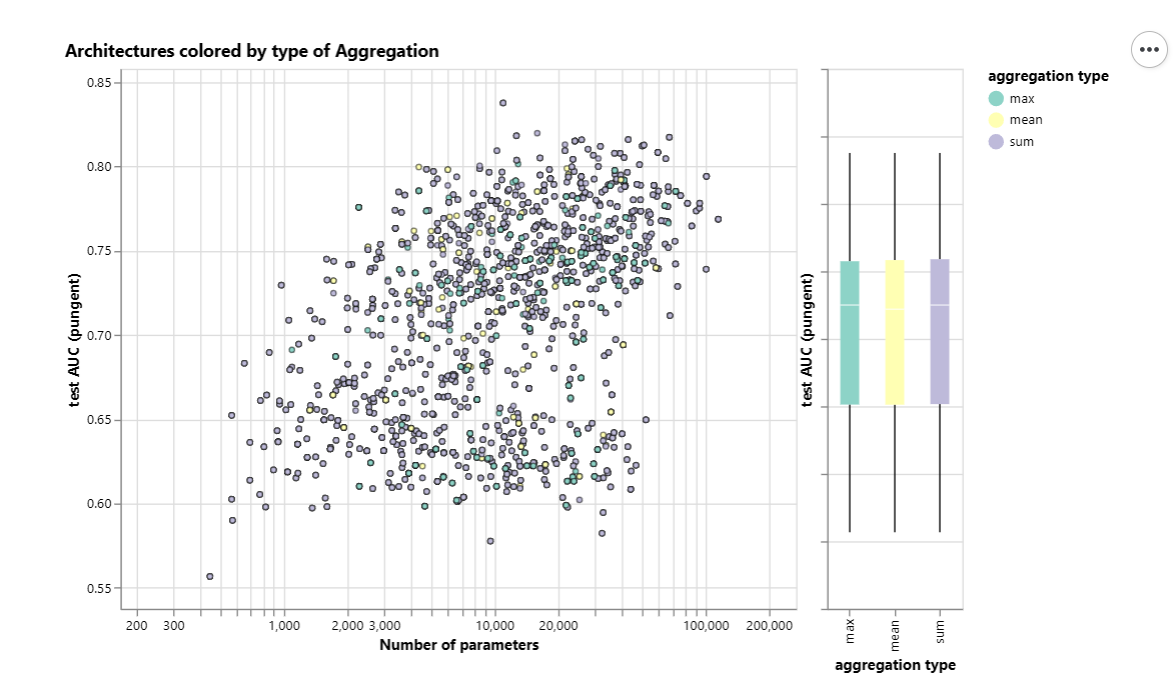
整体上看,当模型参数增加的时候,AUC的上限是在逐步增加的。
但是即使模型很大,我们模型的参数也需要调的比较好,才能获得不错AUC值,如果参数调的很烂,AUC的评分依旧可能很低,与小模型没有本质差别。
每个属性向量的长度
对于顶点、边和全局,当属性向量维度增大时,AUC中位数都会稍微高一点点。
但整体来说,好的很有限,因为这些图的方差都很大。
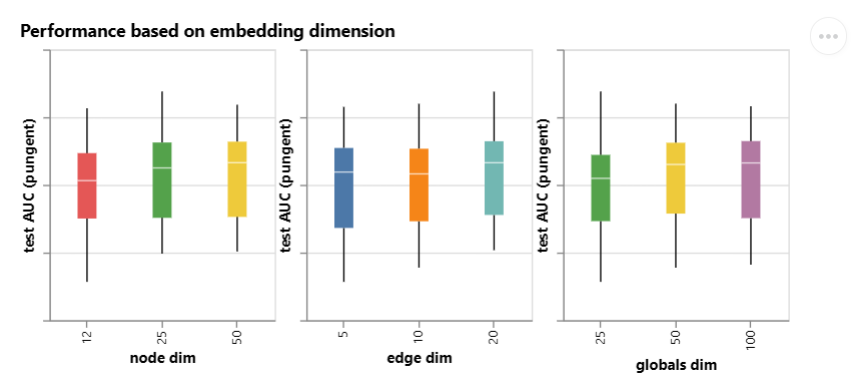
箱线图:
- 每个盒子中的白线代表中位数
- 盒子的上下边缘:
- 上边缘代表前25%的成绩
- 下边缘代表后25%的成绩
- 盒子的厚度代表了模型稳定性。盒子越扁,说明多次实验的结果越集中,模型约稳定;盒子越长,说明结果波动很大。
- 上下延伸的黑线:代表实验中出现的最高分和最低分。
模型层数
当模型层数增加时,AUC中位数逐步增高,但是模型的方差都很大,导致在左侧散点图中看起来比较耦合。
这警示我们,在调高模型层数时,我们也需要优化其他的参数,才能够获得明显提升。
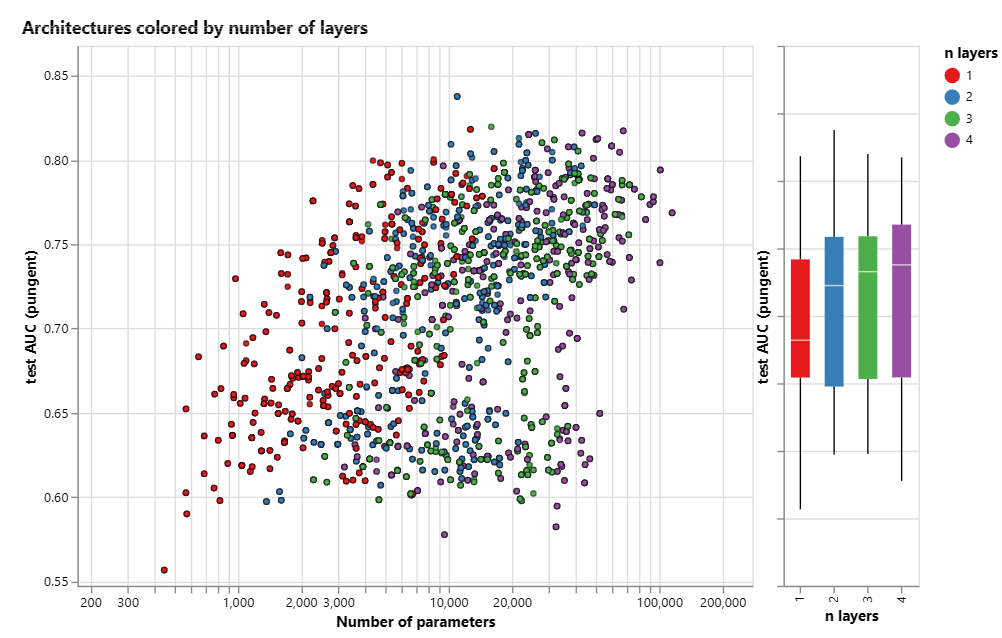
聚合函数
在该数据集上,通过箱线图观察,这三种聚合函数几乎是等价的。
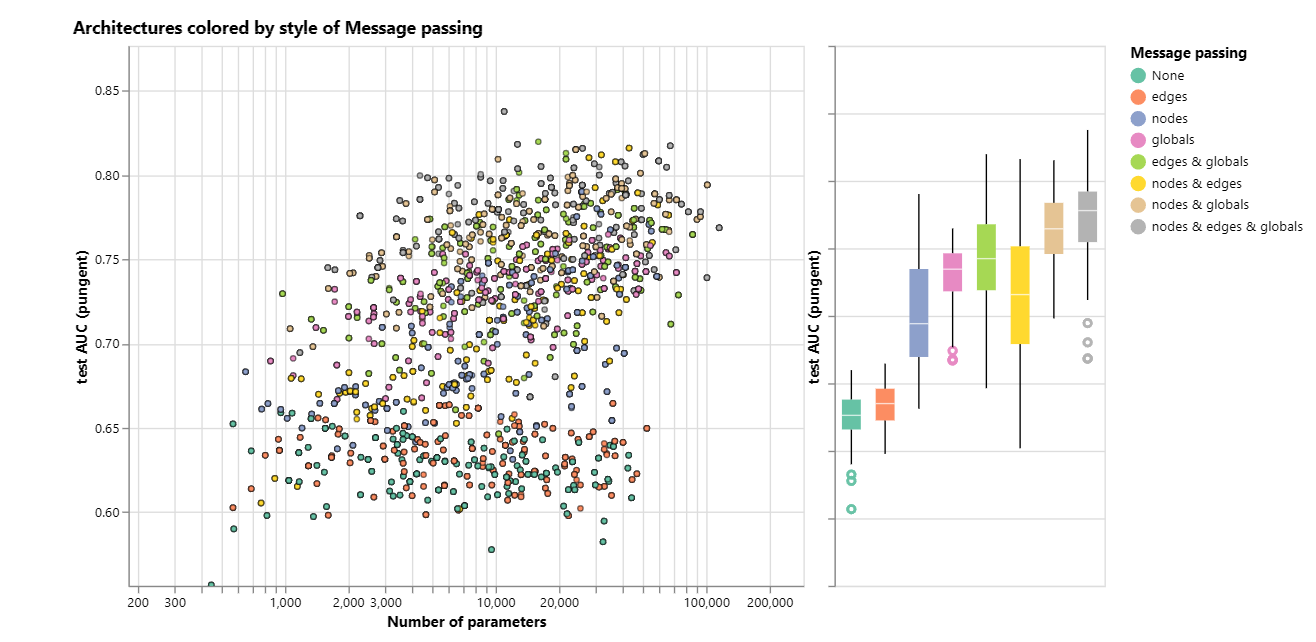
属性之间传递信息
随着我们不断的增加传递的信息,模型的AUC一直在变好,直到我们在顶点、边、全局之间都传递信息,它的AUC中值是最高的。