操作系统期末复习
覆水难收
1章:Introduce
概念考察
操作系统的定义与目标
操作系统 (Operating System, OS)
定义 :充当用户与计算机硬件之间中介 (Intermediary) 的程序。
内核 (Kernel) :一直运行在计算机上的程序(The one program running at all times)。
系统程序 (System Program) :随 OS 发布的程序,但不属于内核。
应用程序 (Application Program) :用户用来解决问题的程序。
OS 的两个主要视角 (Two Views) :
- 用户视角 (User View) :
- 注重 方便 (Convenience) 、易用 (Ease of use) 和 性能 (Performance) 。
- 例外 :嵌入式系统(Embedded systems)可能没有用户界面,主要为了完成特定任务。
- 系统视角 (System View) :
- 资源分配器 (Resource Allocator) :管理硬件(CPU、内存、I/O)和软件资源。面对冲突请求时,决定如何高效 (Efficient) 和 公平 (Fair) 地分配。
- 控制程序 (Control Program) :控制用户程序的执行,防止错误 (Errors) 和对计算机的不当使用 (Improper use)。
计算机系统组织
启动 (Bootstrap program) :
- 位于 ROM 或 EPROM 中,称为 固件 (Firmware) 。
- 初始化系统,加载 OS 内核并开始执行。
中断 (Interrupts) —— 考试高频点
- 定义 :硬件或软件向 CPU 发出的信号,打断当前执行流程。OS 是中断驱动 (Interrupt driven) 的。
- 中断向量 (Interrupt Vector) :存放中断服务程序 (Interrupt Service Routine, ISR) 地址的表格。
- 中断处理过程 :
- 保存当前 CPU 状态(寄存器、程序计数器 PC)。
- 通过中断向量跳转到对应的 ISR。
- 处理完毕后恢复状态,返回原程序。
- 中断类型 :
- 硬件中断 (Hard interrupt) :由硬件设备触发(如 I/O 完成)。
- 软件中断 (Software interrupt) :也称为 陷阱 (Trap) 或 异常 (Exception) 。
- 来源:软件错误(如除零错误 Division by zero )或 用户请求 OS 服务( System Call )。
I/O 操作 (I/O Structure) :
- 设备控制器 (Device Controller) :管理特定类型的设备,拥有本地缓冲区 (Local Buffer)。
- CPU 的作用 :将数据在主存 (Main Memory) 和 本地缓冲区 之间移动。
- I/O 过程 :设备控制器完成操作后,通过中断通知 CPU。
存储结构:
- 存储层次 (Storage Hierarchy) :
- 从上到下:寄存器 (Registers) -> 缓存 (Cache) -> 主存 (Main Memory) -> 固件磁盘 (Solid-state disk) -> 机械硬盘 (Magnetic disk) -> 光盘/磁带 。
- 规律 :越往上,速度越 快 ,成本越 高 ,容量越 小 。
- 易失性 (Volatility) :
- Volatile (易失) :断电丢失数据(如 Main Memory, Cache, Registers)。
- Non-volatile (非易失) :断电保留数据(如 Disk, NVRAM)。
- 缓存 (Caching) :将频繁使用的数据从慢速存储复制到快速存储。遵循 局部性原理 。
双重模式 (Dual-mode Operation) —— 保护机制的核心
用户模式 (User mode) :mode bit = 1。执行用户程序。
内核模式 (Kernel mode) :mode bit = 0。也叫监视器模式 (Monitor mode)。执行 OS 代码。
特权指令 (Privileged Instructions) :
- 定义 :可能引起损害的机器指令(如 I/O 控制、定时器管理、修改中断表)。
- 规则 : 只能在内核模式下执行 。如果在用户模式下尝试执行,硬件会将其视为非法指令并陷入 (Trap) 给 OS。
模式切换 (Transition) :
- 用户程序调用 系统调用 (System Call) -> 变为内核模式 -> 执行服务 -> 返回用户模式。
系统管理组件
进程管理 (Process Management)
内存管理 (Memory Management)
存储管理 (Storage Management)
保护与安全 (Protection and Security)
2章:系统架构 System Structures
概念考察
操作系统服务
对用户有帮助的服务 (Helpful to the User)
- User Interface (用户接口)
- Program Execution (程序执行)
- I/O Operations (I/O 操作)
- File-system Manipulation (文件系统操作)
- Communications (通信)
- Error Detection (错误检测)
确保系统高效运行的服务 (Ensuring Efficient Operation)
- Resource Allocation (资源分配)
- Accounting (记账)
- Protection and Security (保护与安全)
- Protection (保护)
- Security (安全)
系统调用(System Calls)
System Calls (系统调用) : 提供了操作系统服务与用户程序之间的 编程接口 (Programming Interface) 。
参数传递(Parameter Passing):
- Registers (寄存器)
- Block/Table in Memory (内存块/表)
- 将块的地址 (Address of block) 作为参数传给寄存器。
- Stack (堆栈)
系统调用的类型:
- Process Control (进程控制)
- File Management (文件管理)
- Device Management (设备管理)
- Information Maintenance (信息维护)
- Communication (通信)
- Protection (保护)
操作系统设计与实现
Policy (策略) : What will be done? (要做什么?)
Mechanism (机制) : How to do it? (怎么做?/ 如何实现?)
原则 : Separation of policy from mechanism (策略与机制分离) 。
优点 : 提供了最大的 灵活性 (Flexibility) 。
操作系统结构
Simple Structure (简单结构)
Monolithic Structure (宏内核/单体结构)
- 特点 : 内核是一个巨大的、复杂的程序,包含所有 OS 功能(文件系统、CPU 调度、内存管理等)。
- 优点 : Performance (性能高) ,因为所有内核功能在同一地址空间,通信开销小。
- 缺点 : Difficult to implement and maintain (难以实现和维护) 。修改一部分代码可能会影响整个内核 (Changes in one section adversely affect others)。
Microkernel System Structure (微内核结构)
- 特点:移除内核中非必要的组件,只保留最核心的功能(通常是进程间通信 IPC、内存管理、CPU 调度)。将文件系统、设备驱动等作为用户态 (User Mode) 的服务进程运行。
- 通信 : 通过 Message Passing (消息传递) 进行通信。
- 优点 :
- Easier to extend (易于扩展)
- Easier to port (易于移植)
- More reliable & secure (更可靠、更安全)
- 缺点:
- Performance overhead (性能开销)
系统启动(System Boot)
Bootstrap program (引导程序) :
- 代码通常存储在 ROM 或 EEPROM 中(被称为 Firmware (固件) )。
- 负责初始化系统的所有方面 (Initialize all aspects),加载操作系统内核并开始执行。
BIOS (Basic Input Output System) : 传统的引导固件。
UEFI (Unified Extensible Firmware Interface) : 现代的引导固件,比 BIOS 更强大。
GRUB : 常见的 Linux 引导加载程序 (Bootstrap loader),允许选择内核或双系统。
3章:进程概念(Process Concepts)
概念考察
进程与程序的区别 (Process vs Program)
程序 (Program) : 是被动的实体 ( Passive entity ),存储在磁盘上的可执行文件。
进程 (Process) : 是执行中的程序 ( A program in execution ),是动态的实体 ( Active entity )。
关系 : 一个程序可以对应多个进程(例如多个用户运行同一个程序)。
进程在内存中的组成 (Process Memory Layout)
进程在内存中包含以下部分(从高地址到低地址通常分布如下,但也看具体实现):
Stack (栈) : 存放临时数据(函数参数、返回地址、局部变量)。
Heap (堆) : 运行时动态分配的内存 ( Dynamically allocated during run time )。
Data section (数据段) : 存放全局变量 ( Global variables )。
Text section (代码段) : 存放程序代码。
进程状态 (Process State)
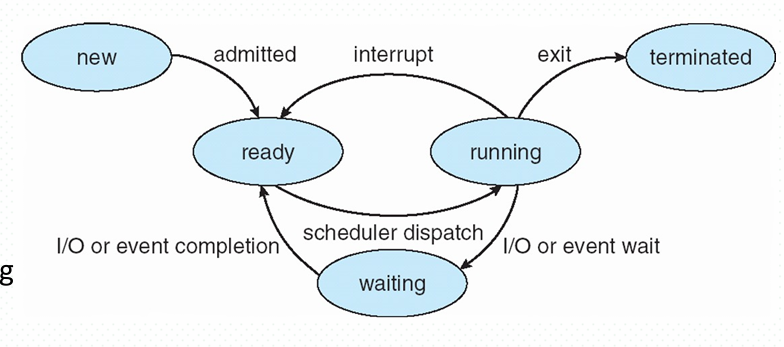
- New (新建) : 进程正在被创建。
- Running (运行) : 指令正在被执行。
- Waiting (等待/阻塞) : 进程等待某个事件发生(如 I/O 完成或信号)。
- Ready (就绪) : 进程等待被分配处理器 ( Waiting to be assigned to a processor )。
- Terminated (终止) : 进程完成执行。
进程控制块 (PCB - Process Control Block)
PCB 是操作系统内核中用于管理进程的数据结构,也叫 Task Control Block 。
包含的信息:
- Process state (进程状态)
- Program counter (程序计数器 - 下一条指令地址)
- CPU registers (寄存器内容)
- CPU scheduling information (调度信息,如优先级)
- Memory-management information (内存管理信息)
- Accounting information (记账信息,如CPU使用时间)
- I/O status information (I/O状态信息,打开的文件列表等)
- 注意:PPT中提到 PCB 不包含 User Data (用户数据)。
进程调度(Process Scheduling)
调度队列 (Scheduling Queues)
- Job queue : 系统中所有进程的集合。
- Ready queue : 驻留在内存中、就绪并等待执行的进程集合。
- Device queues : 等待特定 I/O 设备的进程集合。
调度器类型 (Schedulers)
Short-term scheduler (CPU scheduler, 短期调度) :
- 从 Ready queue 中选择进程分配 CPU。
- 执行频率极高 ( Frequently ,毫秒级)。
- 必须非常快。
Long-term scheduler (Job scheduler, 长期调度) :
- 从磁盘的作业池中选择进程装入内存 ( Into ready queue )。
- 执行频率较低 ( Infrequently ,秒/分钟级)。
- 关键作用 : 控制 Degree of multiprogramming (多道程序度/内存中进程的数量)。
- 目标是保持 I/O-bound (I/O密集型) 和 CPU-bound (CPU密集型) 进程的良好混合。
Medium-term scheduler (中期调度) :
- 涉及 Swapping (交换)。
- 将进程从内存移出到磁盘 ( Swap out ),再移回 ( Swap in )。
- 目的是降低多道程序度,释放内存。
上下文切换 (Context Switch)
- 定义:CPU 从一个进程切换到另一个进程时,保存当前进程状态 ( Save state ) 并加载新进程状态 ( Load saved state )。
- 状态保存在 PCB 中。
- Overhead (开销) : 切换期间系统不做任何有用的工作。
进程操作(Operations on Processes)
fork(): 创建新进程。- 返回值 : 在父进程中返回子进程的 pid (>0) ;在子进程中返回 0 。出错返回负数。
- 子进程是父进程的副本(地址空间复制)。
exec(): 在fork()后使用,用新程序替换当前进程的内存空间。wait(): 父进程等待子进程结束。exit(): 进程结束执行并请求 OS 删除自身。- 级联终止 (Cascading termination) : 如果父进程终止,所有子进程也必须终止(某些系统机制)。
两个特殊状态 (非常重要) :
- Zombie (僵尸进程) : 子进程已终止 (
exit()此时资源已释放),但父进程还没有调用wait()来获取其状态。PCB 仍保留。 - Orphan (孤儿进程) : 父进程终止了,但子进程还在运行。通常由
init进程收养。
进程间通信(IPC - Interprocess Communication)
两种基本模型
Shared Memory (共享内存) :
- 建立一块共享内存区域。
- 优点 : 速度快 (内存访问速度),方便。
- 缺点 : 需要处理同步 ( Synchronization ) 问题,缓存一致性问题。
- 通信由用户进程控制,而非 OS。
Message Passing (消息传递) :
- 通过
send()和receive()交换消息。 - 优点 : 不需要冲突避免,适合少量数据,适合分布式系统。
- 由 OS 内核处理 ( Kernel )。
消息传递的分类:
- Direct Communication (直接通信) :
- 必须显式命名对方 (
send(P, msg),receive(Q, msg))。
- 必须显式命名对方 (
- Indirect Communication (间接通信) :
- 通过 Mailboxes (邮箱) 或 Ports (端口) 发送。
- 多对多关系。
- Synchronous vs Asynchronous (同步 vs 异步) :
- Blocking (阻塞) = Synchronous : 发送方发完后等待接收方收到;接收方等待消息到达。
- Non-blocking (非阻塞) = Asynchronous : 发送方发完就走;接收方可能收到有效消息或 Null。
客户机-服务器通信(Client-Server System)
Sockets (套接字)
- 定义:通信的端点 ( Endpoint for communication )。
- 组成:IP Address + Port number (端口号)。
- 例如:
161.25.19.8:1625。
RPC (Remote Procedure Calls, 远程过程调用)
- 抽象了网络系统间的过程调用。
- Stubs (存根) : 客户端的代理 ( Proxy ),负责 Marshalling (参数打包/编组)。
- Big-endian / Little-endian : 不同架构的数据表示问题,通过 XDR (External Data Representation) 解决。
4章:多线程程序(Multithreaded Programming)
概念考察
线程基础(Thread)
定义 (Definition) : 线程是 CPU 使用的基本单元 (Basic unit of CPU utilization),也称为 轻量级进程 (Lightweight Process, LWP) 。
组成 (Composition) : 线程包含:
- Thread ID (线程ID)
- Program Counter (程序计数器)
- Register set (寄存器组)
- Stack (栈)
共享资源 (Shared Resources) : 同一进程中的线程共享以下资源:
- Code section (代码段)
- Data section (数据段)
- OS resources (操作系统资源,如打开的文件、信号)
优点 (Benefits) :
- Responsiveness (响应度高): 即使部分阻塞,程序仍能继续运行(如Web浏览器)。
- Resource Sharing (资源共享): 线程默认共享进程内存和资源(进程间通信需共享内存或消息传递,开销大)。
- Economy (经济性): 创建和切换线程的开销比进程小 (Context switching is faster)。
- 考点 : 进程切换涉及保存 PCB,刷新 TLB 等,开销大;线程切换主要保存寄存器和栈,开销小。
- Scalability (可扩展性): 能充分利用 Multiprocessor architectures (多处理器架构)。
多核编程
并发 vs 并行 (Concurrency vs. Parallelism) :
- Concurrency (并发) : 任务在时间段内交替推进 (Making progress)。单核 CPU 通过调度实现并发。
- Parallelism (并行) : 任务在同一时刻同时执行 (Simultaneous execution)。需要多核 (Multicore) 系统。
多线程模型(Multithreading Models)
User Threads (用户线程) : 由用户层线程库管理,内核不可见。快,但如果一个线程阻塞,整个进程都阻塞。
Kernel Threads (内核线程) : 由 OS 内核管理。
映射模型 (Mapping Models) :
- Many-to-One (多对一) : 多个用户线程映射到一个内核线程。
- 缺点: 并发度低,一个阻塞全阻塞。
- One-to-One (一对一) : 一个用户线程对应一个内核线程。
- 优点: 并发度高 (More concurrency)。
- 缺点: 创建内核线程有开销,可能限制线程数量。
- 示例: Linux , Windows , Solaris 9+.
- Many-to-Many (多对多) : 多个用户线程复用多个内核线程。
- 特点: 灵活,但这模型实现复杂。
- Two-level Model (双层模型) : M:M 的变种,允许绑定某个用户线程到特定内核线程。
线程库(Thread Libraries)
- Pthreads : POSIX 标准 (IEEE 1003.1c),不仅是实现,更是 规范 (Specification) 。
pthread_create(): 创建线程。pthread_join(): 等待线程结束。
- Windows Threads : 内核级线程库。
- Java Threads : 由 JVM 管理,通常基于宿主机的线程模型(如在 Linux 上是 1:1)。
隐式线程(Implicit Threading)
Thread Pools (线程池) :
- 预先创建一定数量的线程放入池中。
- 优点:
- 服务请求通常比创建新线程快。
- 限制线程总数,防止资源耗尽。
线程问题(Thread Issues)
Thread Cancellation (线程取消) : 终止正在运行的线程。
- Asynchronous cancellation (异步取消) : 立即终止目标线程 (可能导致资源未释放)。
- Deferred cancellation (延迟取消) : 目标线程定期检查是否应终止 (更安全)。
5章:进程调度(Process Scheduling)
概念考察
进程执行周期(Process Execution Cycle)
- CPU Burst (CPU脉冲) : 进程在CPU上执行计算的时间。
- I/O Burst (I/O脉冲) : 进程等待I/O完成的时间。
- 进程的执行是 CPU Burst 和 I/O Burst 交替进行的 (Alternating Sequence)。
- CPU-bound process (CPU密集型进程) : 只有少量非常长的 CPU bursts。
- I/O-bound process (I/O密集型进程) : 有大量非常短的 CPU bursts。
调度器与分派器 (Scheduler & Dispatcher)
Short-term scheduler (短程调度器) : 从内存中的就绪队列 (Ready Queue) 中选择进程并分配 CPU。
Dispatcher (分派器) : 负责将 CPU 的控制权交给由调度器选择的进程。主要工作包括:
- Switching context (切换上下文)
- Switching to user mode (切换到用户模式)
- Jumping to the proper location (跳转到适当位置重启程序)
Dispatch latency (分派/调度延迟) : 分派器停止一个进程并启动另一个进程所需的时间。
调度时机与方式 (Scheduling Timing & Mode)
调度发生在以下四种情况:
- Running $\rightarrow$ Waiting (e.g., I/O request)
- Running $\rightarrow$ Ready (e.g., interrupt, time slice expired)
- Waiting $\rightarrow$ Ready (e.g., I/O completion)
- Terminates (进程终止)
- Non-preemptive (非抢占式) : 进程一旦获得 CPU,就会一直运行直到终止或切换到 Waiting 状态(即情况 1 和 4)。
- Preemptive (抢占式) : 当前运行的进程可以被中断并强制移出 CPU(即情况 2 和 3 也可能发生调度)。现代操作系统(Windows, Linux, macOS)几乎都是抢占式的。
线程与多核调度
线程调度(Thread Scheduling)
- User-level threads(用户级线程) 由线程库管理
- Kernel-level threads (内核级线程) 由操作系统管理
Contention Scope (竞争范围) :
- Process-contention scope (PCS, 进程竞争范围) : 线程库在 LWP (Lightweight Process) 上调度用户线程 (Many-to-one, Many-to-many 模型)。
- System-contention scope (SCS, 系统竞争范围) : 内核决定哪个内核线程在 CPU 上运行 (One-to-one 模型, Linux/Windows)。
多处理器调度 (Multiple-Processor Scheduling)
Symmetric Multiprocessing (SMP, 对称多处理) : 每个处理器自我调度 (Self-scheduling),共享这就绪队列。最常用。
Processor Affinity (处理器亲和性) : 进程倾向于在同一个处理器上运行(利用缓存)。
- Soft affinity (软亲和) : 试图保持,但不保证。
- Hard affinity (硬亲和) : 强制在特定处理器运行。
Load Balancing (负载均衡) :
- Push migration : 周期性检查,将任务从超载处理器推出去。
- Pull migration : 空闲处理器从忙碌处理器拉取任务。
Multicore Processors (多核处理器) : 一个物理芯片上有多个计算核心。
- Memory Stall (内存停顿) : 处理器等待内存数据的时间。
- Multithreading (Hyperthreading, 超线程) : 利用内存停顿时间,在一个核心上交替执行两个硬件线程。
实时调度(Real-Time CPU Scheduling)
基础定义:
- Soft real-time (软实时) : 尽量满足,但不保证 (No guarantee)。
- Hard real-time (硬实时) : 必须在截止时间前完成 (Must be serviced by its deadline)。
- Event Latency (事件延迟) : 从事件发生到服务开始的时间。
- Interrupt latency (中断延迟) + Dispatch latency (调度延迟) 。
Rate Monotonic Scheduling (RMS, 单调速率调度)
- 类型 : Static priority (静态优先级)。
- 规则 : 周期越短,优先级越高 (Shorter periods = Higher priority)。
- 优先级 : 与周期成反比。
- 局限性 : 即使 CPU 利用率未达 100%,也可能无法满足截止时间。
Earliest Deadline First (EDF, 最早截止期优先)
- 类型 : Dynamic priority (动态优先级)。
- 规则 : 截止时间越早,优先级越高 (Earlier deadline = Higher priority)。
- 优势 : 理论上是 Optimal (最优的),可以达到 100% CPU 利用率。
计算题
五大准则 (Criteria)
CPU utilization (CPU利用率) : CPU 忙碌的时间比例。
Throughput (吞吐量) : 单位时间内完成的进程数量 。
Turnaround time (周转时间) : 从进程提交到完成的时间段。
- 公式 : $Turnaround Time = Completion Time - Arrival Time$
Waiting time (等待时间) : 进程在就绪队列 (Ready Queue) 中等待的总时间。
- 公式 : $Waiting Time = Turnaround Time - Burst Time$
- 注意:这是衡量调度算法好坏的关键指标。
Response time (响应时间) : 从提交请求到产生第一个响应 (First response) 的时间(注意:不是输出结果的时间)。适用于交互式系统 (Interactive systems)。
调度算法
FCFS(First-Come, First-Served)
规则:先到达的进程先服务
特点:Non-Preemptive
缺点:Convoy effect (护送效应) —— 短进程被长进程阻塞,导致平均等待时间变长。
Shortest-Job-First(SJF)
规则:选择下一个CPU burst最短的进程
特点:
- 可以是 Preemptive (抢占式) 或 Non-preemptive (非抢占式)。
- Optimal (最优的) : 提供最小的 平均等待时间 (Average Waiting Time) 。
抢占式SJF(Shortest-Remaining-Time-First, SRTF)
- 当新进程到达时,如果其 CPU burst 小于当前运行进程的 剩余时间 (Remaining time) ,则发生抢占。
Priority Scheduling(优先级调度)
规则:CPU 分配给优先级最高 (Highest priority) 的进程。
- 通常:数字越小,优先级越高 (Smallest integer $\equiv$ highest priority)。
缺点:Starvation (饥饿) / Indefinite blocking (无限阻塞) —— 低优先级进程可能永远无法执行。
注意选择题
解决方案 : Aging (老化) —— 随着时间推移,逐渐增加等待进程的优先级。
Round Robin(RR, 轮转调度)
规则:每个进程分配一个 Time Quantum (时间片, q) 。
特点 : Preemptive (抢占式)。时间片用完后,进程被放到就绪队列的末尾。
性能分析 :
- $q$ 太大 $\rightarrow$ 退化为 FCFS 。
- $q$ 太小 $\rightarrow$ Context switch (上下文切换) 开销过大。
- 经验法则: 80% 的 CPU bursts 应该短于时间片 $q$。
Multilevel Queue(多级队列)
规则:就绪队列被分为多个独立的队列(如前台/后台)。
特点:队列之间有固定的优先级(如前台优先于后台),且进程不能在队列间移动。
Multilevel Feedback Queue(多级反馈队列)
规则:允许进程在队列之间移动 (Move between queues)。
逻辑:
- 使用过多 CPU 时间的进程会被移到低优先级队列。
- 在低优先级队列等待过久的进程会被移到高优先级队列 ( Aging )。
参数 : 队列数量、每个队列的算法、升级/降级的方法。
Highest Response Rate First(HRRF, 高响应优先)
规则:综合考虑等待时间和服务时间,避免长作业饥饿。
公式:
$$
Response Ratio = \frac{Waiting Time + Expected Burst Time}{Expected Burst Time} = 1 + \frac{W}{S}
$$
特点:非抢占式。
6章:进程同步(Process Synchronization)
概念考察
基础背景
Race Condition(竞争条件):
- 定义:多个进程并发访问和操作同一数据,且执行结果取决于访问发生的特定顺序的情况。
- 后果:数据不一致(Data inconsistency)
- 解决:需要进程同步(Process Synchronization)和互斥(Mutual Exclusion)
临界区问题(The Critical-Section Problem)
Critical Section(临界区/段):
- 进程中访问共享资源(Shared Resources)的那段代码。
- 结构:
- Entry section (进入区) : 申请进入临界区。
- Critical section (临界区) : 执行核心操作。
- Exit section (退出区) : 退出并释放锁。
- Remainder section (剩余区) : 其他代码。
★ 解决方案的三个必要条件 (Necessary Conditions):
- Mutual Exclusion(互斥访问):如果进程 $P_i$ 正在其临界区执行,其他进程不能进入临界区。
- Progress(前进/空闲让进):如果临界区为空(没有进程在执行),且有进程想进入,则不能无限期推迟选择哪个进程进入(即不能死锁)。
- Bounded Waiting(有限等待):当一个进程申请进入临界区后,到该申请被批准之间,其他进程进入临界区的次数必须有上限(防止 Starvation/饥饿 )。
信号量(Semaphores)
定义:一个整数变量,只能通过两个原子操作 (Atomic Operations) 访问:wait() 和 signal()。
wait()(也称为 P 操作): 减少信号量值。如果值 < 0,进程阻塞。signal()(也称为 V 操作): 增加信号量值。唤醒等待进程。
分类:
- Binary Semaphore (二元信号量) : 值只能是 0 或 1。也称为 Mutex Locks (互斥锁) 。主要用于互斥。
- Counting Semaphore (计数/多元信号量) : 值域不受限制。主要用于控制访问具有多个实例的资源(如缓冲池大小)。
忙等待(Busy Waiting):
- 在简单的信号量实现中,进程在无法进入临界区时会不断循环检查(如
while(S<=0);),这浪费 CPU 周期。 - 这种锁也称为 Spinlock (自旋锁) 。
- 优化 : 使用 Block (阻塞) 和 Wakeup (唤醒) 机制代替忙等待(进程进入 Waiting 状态,让出 CPU)。
死锁与饥饿(Deadlock & Starvation):
- Deadlock (死锁) : 两个或多个进程无限期等待一个只能由等待队列中的另一个进程触发的事件。
- Starvation (饥饿) : 进程无限期等待(例如在优先级调度中低优先级进程一直得不到执行)
管程(Monitors)
定义:一种高级同步机制 (High-level synchronization construct),由编程语言提供(如 Java, C#)。
特点:
- 管程内的共享变量只能通过管程内的过程(Procedures)访问
- 管程自动保证互斥(Only one process can be active within the monitor at a time)
Condition Variables (条件变量) :
- 用于管程内部的同步。
x.wait(): 进程挂起,直到另一个进程调用x.signal()。x.signal(): 唤醒一个等待的进程。如果没有进程等待,该操作无效(这与信号量的 signal 不同,信号量的 signal 总会使值+1)。
计算题
Peterson算法(Peterson’s Solution)
适用:两个进程的软件互斥方案。
关键变量 :
int turn: 表示轮到谁 (Who’s turn)。boolean flag[2]: 表示进程是否想进入 (Indicates if a process is ready to enter)。
逻辑:
1 | |
硬件同步
TestAndSet 和 Swap 指令:
- 它们是原子 (Atomic) 的(不可中断)。
- 用于实现互斥锁。
- 缺点:通常会导致忙等待 (Busy Waiting)。
★ 生产者-消费者问题 (Bounded-Buffer Problem)
信号量设置 :
mutex = 1: 互斥访问缓冲区 (Binary semaphore)。empty = n: 空缓冲槽的数量 (Counting semaphore)。full = 0: 满缓冲槽的数量 (Counting semaphore)。
代码逻辑:
1 | |
易错点/考点 :
wait(empty)和wait(mutex)的 顺序不能颠倒 ,否则会导致 死锁 (Deadlock) 。
★ 读者-写者问题 (Readers-Writers Problem)
规则 :
- 允许多个读者同时读 (Multiple readers simultaneously)。
- 写者必须互斥 (Exclusive access for writers)。
- 写者与读者必须互斥。
信号量设置 :
wrt = 1: 控制写操作(也是读写互斥锁)。mutex = 1: 保护readcount变量。readcount = 0: 记录当前有多少读者。
代码逻辑:
1 | |
考点 : 这种写法是 读者优先 (Reader Preference) ,可能导致写者饥饿 (Starvation)。
★哲学家就餐问题 (Dining-Philosophers Problem)
- 问题 : 5个哲学家,5根筷子。每人需要左右两根筷子才能吃。
- 死锁场景 : 每个人都拿起了左边的筷子,都在等右边的 -> 死锁。
- 解决方案 (无死锁) :
- 最多允许4人同时坐下。
- 只有当左右两根筷子都可用时才拿起 (Monitor 方案)。
- 奇数号先拿左,偶数号先拿右 (Asymmetric solution)。
示例解决思路:
- 使用 互斥锁 ,对于拿筷子这一动作进行上锁。确保拿筷子这一动作是一气呵成的。在一个哲学家拿起 两个筷子开始进行吃饭前 ,不会有第二个哲学家进行拿筷子这一动作。确保不会出现每个哲学家各拿了一根筷子的情况。
1 | |
★理发师睡觉问题
理发师状态与顾客行为 :
- 理发师闲置 :如果没有顾客,理发师就 睡觉 。
- 顾客到来 (理发师忙碌) :
- 如果等待室的 N 把椅子都满了 ,新来的顾客 离开 。
- 如果理发师忙碌但有空位,顾客坐下 等待 。
- 顾客到来 (理发师睡觉) :顾客会叫醒理发师并接受服务。
代码逻辑:
1 | |
7章:死锁(Deadlocks)
概念考察
死锁定义
死锁(Deadlock):一组阻塞进程(blocked processes),每个进程都持有一个资源并等待获取该组中另一个进程所持有的资源。
特征:这些进程永远都无法继续执行。
死锁产生的四个必要条件:只有当这四个条件同时成立(hold simultaneously)时,死锁才会发生。
- 互斥(Mutual Exclusion):资源是不可共享的,一次只能由一个进程使用。
- 占有并等待(Hold and Wait):进程至少持有一个资源,并且正在等待获取其他进程持有的额外资源。
- 非抢占(No Preemption):资源不能被强行剥夺,只能由持有它的进程自愿释放。
- 循环等待(Circular Wait):存在一个等待进程集合 ${P_0, P_1, …, P_n}$,其中 $P_0$ 等待 $P_1$,$P_1$ 等待 $P_2$,…,$P_n$ 等待 $P_0$。
处理死锁的方法(Methods for Handling Deadlocks)
- 死锁预防 (Deadlock Prevention): 确保四个必要条件中至少有一个不成立。
- 死锁避免(Deadlock Avoidance): 操作系统利用先验信息(最大需求),动态决定是否分配资源,确保系统始终处于 安全状态 。
- 死锁检测与恢复 (Deadlock Detection and Recovery) : 允许死锁发生,检测它,然后恢复。
- 忽略(Ignore/Ostrich Algorithm) : 假装死锁从未发生 (Unix/Linux/Windows 常用)。
看到这里笑了:竟然主流操作系统都选择了无视(^_^)
死锁预防具体策略(Prevention Protocols)
破坏互斥 : 通常不可行 (non-sharable resources 必须互斥)。
破坏占有并等待 (Hold and Wait) :
- Protocol 1 : 进程开始执行前申请所有资源。
- Protocol 2 : 申请新资源前必须释放当前持有的所有资源。
- 缺点 : 资源利用率低 (Low resource utilization),可能导致饥饿 (Starvation)。
破坏非抢占 (No Preemption) : 如果申请资源被拒,则释放已占有的资源(隐式抢占)。
破坏循环等待 (Circular Wait) : 对所有资源类型进行 完全排序 (Total Ordering) ,要求进程按递增顺序申请资源。
活锁(Livelock)
定义:线程/进程没有被阻塞,但由于不断重复尝试操作并失败(例如:获取锁失败->释放锁->重试),导致无法取得进展。
与死锁区别 : 进程处于 Running 状态而非 Waiting 状态。
计算题
资源分配图 (Resource-Allocation Graph, RAG)
组成 : 进程节点 ($P$),资源节点 ($R$),请求边 ($P \to R$),分配边 ($R \to P$)
判断死锁 :
- 无环路 (No Cycle) $\Rightarrow$ 无死锁。
- 有环路 (Cycle) :
- 资源只有单个实例 (Single Instance) $\Rightarrow$ 死锁 。
- 资源有多个实例 (Multiple Instances) $\Rightarrow$ 可能死锁 (需要进一步分析是否有一个进程能完成并断开环路)。
银行家算法(Banker’s Algorithm) 死锁避免
关键矩阵 (Matrices)
- Available : 系统当前闲置资源。
- Max : 进程对资源的最大总需求。
- Allocation : 进程当前已持有的资源。
- Need : 进程还需要多少资源。
- 公式 : $Need[i,j] = Max[i,j] - Allocation[i,j]$
题型 A: 判断系统安全性 (Safety Algorithm)
- Work = Available 。
- 完成向量
Finish[i] = false(表示进程 Pi 尚未完成)。 - 寻找一个进程 $P_i$ 满足:
Finish[i] == false且Need[i] <= Work。 - 如果找到:
- 该进程执行完成,释放资源:
Work = Work + Allocation[i]。 Finish[i] = true。- 重复步骤 2。
- 该进程执行完成,释放资源:
- 若所有进程都能运行完成 (
Finish全为 true),则系统处于 安全状态 (Safe State) ,找到的序列为 安全序列 (Safe Sequence) 。
题型 B: 资源请求处理 (Resource-Request Algorithm)
假设进程 $P_i$ 请求资源 $Request_i$:
- 检查 : $Request_i \le Need_i$ 且 $Request_i \le Available$。如果不满足则报错或等待。
- 试探性分配 :
Available -= Request_iAllocation += Request_iNeed -= Request_i
- 安全性检查 : 对修改后的状态运行 Safety Algorithm 。
- 若 Safe $\Rightarrow$ 同意请求。
- 若 Unsafe $\Rightarrow$ 拒绝请求,恢复原状,进程等待。
死锁检测算法
数据结构 : 使用 Available, Allocation, Request (注意:没有 Max 和 Need)。
逻辑 :
Work = Available。- 对于所有
Allocation为 0 的进程,视为Finish = true(不占资源的进程不会造成死锁)。 - 寻找
Finish == false且Request[i] <= Work的进程。 - 如果找到,假设其执行并释放资源 (
Work += Allocation),标记Finish = true。 - 循环结束后,若仍有
Finish == false的进程,则系统 死锁 ,这些进程即为死锁进程。
需要注意的是:死锁检测和银行家算法中的判断系统安全性是两个算法,需要注意看题目中的关键词。
死锁检测:
Is the system in a deadlock state, and why?银行家算法:
Answer following questions, by means of the banker’s algorithm.Is the system now in a safe state, and why?只有在使用银行家算法时,才能使用安全序列等专有名词。否则可能被扣分。
8章:内存管理(Memory-Management)
概念考察
背景与基础
内存管理单元(Memory-Management Unit, MMU):
- 定义 : 运行时将逻辑地址 (Logical Address) 映射到 物理地址 (Physical Address) 的硬件设备。
- 基址寄存器 (Base Register) : 这里的基址寄存器通常被称为 重定位寄存器 (Relocation Register) 。
- 映射机制 : 用户进程生成的地址 + 重定位寄存器的值 = 物理地址。
地址空间(Address Spaces):
- 逻辑地址 (Logical Address) / 虚拟地址 (Virtual Address) : 由CPU生成的地址。
- 物理地址 (Physical Address) : 内存单元看到的地址。
- 逻辑地址空间 (Logical Address Space) : 程序生成的所有逻辑地址的集合。
- 物理地址空间 (Physical Address Space) : 对应的所有物理地址的集合。
地址绑定(Address Bingding)- 指令和数据绑定到内存地址的时机:
- 编译时(Compile time):如果已知内存位置,生成 绝对代码 (Absolute code) 。
- 加载时(Load time):如果编译时未知位置,生成 可重定位代码 (Relocatable code) 。
- 执行时(Execution time):进程在执行期间可以在内存中移动。需要硬件支持(如基址/界限寄存器)。(现代OS主要采用此方式)
动态加载与链接:
- 动态加载(Dynamic Loading): 子程序只有在被调用时才加载。提高内存利用率。
- 动态链接(Dynamic Linking):链接推迟到运行时。主要用于系统库(System Libraries)或共享库。
交换(Swapping)
- 定义 : 进程可以暂时从内存换出 (Swapped out) 到 备份存储 (Backing store) ,稍后再 换入 (Swapped in) 。
- 目的 : 允许物理地址空间总和超过实际物理内存,提高多道程序程度。
- 耗时 : 主要时间消耗在 传输时间 (Transfer time) ,与交换的内存大小成正比。
连续内存分配(Contiguous Memory Allocation)
保护机制 (Protection) : 使用 基址寄存器 (Base Register) (最小物理地址) 和 界限寄存器 (Limit Register) (范围大小) 来保护进程互不干扰。
分配方式:
- 固定分区 (Fixed-sized partitions) : (较旧技术) 易导致内碎片。
- 可变分区 (Variable partitions / MVT) : 操作系统维护一个空闲孔 (Hole) 表。
碎片 (Fragmentation) :
- 外部碎片 (External Fragmentation) : 总空闲空间足够,但由于不连续而无法分配。-> 解决方案:紧缩 (Compaction) (仅在动态重定位时可用)。
- 内部碎片 (Internal Fragmentation) : 分配给进程的内存比请求的大,主要发生在固定分区或分页中。
分页(Paging)
基本原理:
- 帧/页框(Frames):物理内存被划分为固定大小的块。
- 页(Pages):逻辑内存被划分为同样大小的块。
- 页表(Page Table):存储页号到帧号的映射。
优点:避免了外部碎片,但会有内部碎片(平均每进程半页)。
地址结构 : 逻辑地址分为 页号 (Page number, p) 和 页内偏移 (Page offset, d) 。
转换旁路缓冲(Translation Look-aside Buffer , TLB):
- 定义:一个高速缓存(Associative memory),存储部分页表项。
- TLB 命中 (TLB Hit) : 在TLB中找到页号,直接得到帧号 (速度快)。
- TLB 未命中 (TLB Miss) : 需要访问内存中的页表,然后更新TLB。
保护 : 页表中每一项有 有效/无效位 (Valid-invalid bit) 。
- Valid : 页面在逻辑地址空间内。
- Invalid : 页面不在逻辑地址空间内。
共享页 (Shared Pages) : 只读代码 (Reentrant code) 可以在进程间共享。
页表结构(Structure of page table)
分层分页 (Hierarchical Paging) : 将页表再分页(如两级页表 Two-level paging),解决页表在大逻辑地址空间下占用连续内存过大的问题。
哈希页表 (Hashed Page Tables) : 适用于地址空间大于32位的系统。使用哈希表处理冲突链表。
反向页表 (Inverted Page Tables) :
- 结构 : 整个系统只有一张表,每个物理帧 (Frame) 对应一个条目。
- 内容 : 包含 <进程ID (pid), 页号 (p)>。
- 优点 : 大幅减少页表占用的内存。
- 缺点 : 搜索时间变长 (通常配合哈希表使用)。
计算题
动态存储分配算法(Dynamic Storage- Allocation)
场景:有一维空闲内存块(Holes),新进程来了,给它分配哪一块?
- 首次适应 (First-fit) : 分配第一个足够大的孔。 (速度最快)
- 最佳适应 (Best-fit) : 分配最小的足够大的孔。 (产生最小的剩余孔)
- 最差适应 (Worst-fit) : 分配最大的孔。 (产生最大的剩余孔)
逻辑地址到物理地址的转换
- 逻辑地址空间大小 = $2^m$,页大小 = $2^n$。
- 页号 (p) = 逻辑地址的高 $m-n$ 位 (或者
逻辑地址 / 页大小,取整)。 - 页偏移 (d) = 逻辑地址的低 $n$ 位 (或者
逻辑地址 % 页大小,取余)。 - 物理地址 = (帧号 $f \times$ 页大小 $2^n$) + 偏移 $d$。
例题 (来自PPT) :
- 逻辑地址空间 $m=4$ (16 bytes),物理地址空间 32 bytes,页大小 $n=2$ (4 bytes)。
- 逻辑地址 0 (二进制 0000): $p=0, d=0$。查表 Page 0 -> Frame 5。物理地址 = $5 \times 4 + 0 = 20$。
- 逻辑地址 9 (二进制 1001): $p=2, d=1$。查表 Page 2 -> Frame 1。物理地址 = $1 \times 4 + 1 = 5$。
有效访问时间计算(Effective Access Time, EAT)
场景 : 包含TLB的系统中,CPU访问数据的平均时间。
- $\epsilon$: TLB 查找时间 (Associative lookup time)。
- $\alpha$: TLB 命中率 (Hit ratio)。
- $t$: 内存访问时间 (Memory access time)。
公式 :
$$
EAT = \alpha \times (\epsilon + t) + (1 - \alpha) \times (\epsilon + t + t)
$$
解释 :
- 命中时 : 查TLB ($\epsilon$) + 访问物理内存取数据 ($t$)。
- 未命中时 : 查TLB ($\epsilon$) + 访问内存页表取帧号 ($t$) + 访问物理内存取数据 ($t$)。 (注意:这里假设是一级页表,如果是多级页表,未命中时的内存访问次数会增加)。
内部碎片(Internal Fragmentation Calculation)
公式:
$$
\text{内部碎片} = \text{页大小} - (\text{进程大小} \pmod{\text{页大小}})
$$
(如果余数为0,则无碎片)
例题 :
- 页大小 2048 bytes,进程大小 72766 bytes。
- $72766 / 2048 = 35$ 页 … 余 1086 bytes。
- 进程占用了 35 个完整页 + 第 36 页的一部分 (1086 bytes)。
- 内部碎片 = $2048 - 1086 = 962$ bytes。
多级页表的大小计算(Multilevel Page Table Size)
逻辑:
- 对于32位地址,如果页大小是 4KB ($2^{12}$),则剩下 20 位用于页号。
- 如果使用一级页表,需要 $2^{20}$ 个条目,太大。
- 两级页表 (Two-level paging) : 将 20 位再切分,例如 外层页表 10位 ($p_1$) + 内层页表 10位 ($p_2$)。
- 计算 : 能够画出逻辑地址的结构图(如 10 | 10 | 12),并计算各级页表的大小。
9章:虚拟内存(Virtual Memory)
概念考察
背景与基本概念
虚拟内存:讲用户逻辑内存(Logical Memory)与物理内存(Physical Memory)分离。
核心优势:
- 逻辑地址空间可以远大于物理地址空间。
- 允许地址空间被多个进程共享
- 提高进程创建效率
- 支持更多程序并发运行
- 减少I/O负载
请求调页(Demand Paging)
定义:只有当页面被需要时才将其调入内存。(Bring a page into memory only when it is needed)。
- Lazy Swapper:只有在需要页面时才将其交换入内存。
有效位/无效位(Valid-Invalid Bit):
- Valid(1):页面合法且在物理内存中(In-memory)。
- Invalid(0):页面无效或在磁盘上(On disk)
缺页中断(Page Fault):
- 触发条件:访问的页面标记为Invalid
- 处理步骤:
- 硬件陷入内核(Trap to OS)内中断
- 操作系统检查引用是否合法:
- 如果不合法则终止
- 如果合法但不在内存中,则进行调页
- 寻找一个空闲帧(Free Frame)
- 启动磁盘操作,将所需页面读入空闲帧
- 修改页表,将其有效位设为Valid
- 重启指令
纯请求调页(Pure Demand Paging):进程开始执行时内存中没有任何页面,第一条指令即产生缺页中断。
写时复制(Copy-on-Write, COW)
常用于 fork()系统调用创建子进程
原理:父子进程最初共享(Share)相同的物理页面。只有当其中一个进程需要修改(Modify/Write)页面时,操作系统才会为该进程创建该页面的副本。
优点:极大提高了进程创建的效率,减少了不必要的内存拷贝。
系统抖动(Trashing)
定义:进程忙于页面的换进换出(Swapping page in and out),导致无法有效执行任务。
现象:CPU利用率急剧下降(CPU utilization drops sharply)
原因:进程分配到的帧数少于其运行所需的最小帧数(Not enough frames)
- OS监控到CPU利用率低$\rightarrow$ 引入更多进程 (增加多道程序度) $\rightarrow$ 内存更紧张 $\rightarrow$ 更多缺页 $\rightarrow$ CPU 利用率更低(恶性循环)。
解决方案:
- 工作集模型(Working-Set Model):基于局部性原理(Locality),确保为进程分配覆盖其当前工作集的足够帧数。
- 缺页率控制(Page-Fault Frequency,PFF):设置缺页率的上限和下限,动态调整分配给进程的帧数。
内存映射文件(Memory-Mapped Files)
原理:将磁盘文件的一组块映射到进程的内存页面中。
特点:文件I/O被视为常规的内存访问(Memory access),不再需要 read()/write()系统调用。
共享:多个进程可以通过映射同一个文件来实现高效的内存共享
内核内存分配(Allocating Kernel Memory)
伙伴系统(Buddy System):
- 从物理连续的段中分配内存。
- 内存块大小必须是2的幂(Power-of 2)
- 合并(Coalescing):释放内存时,如果相邻的伙伴块也是空闲的,则合并成更大的块。
Slab分配器(Slab Allocator):
- 用于管理内核对象(Kernel Objects, 如PCB,信号量)的缓存
- Slab:由一个或多个物理连续的页面组成
- 优点:没有 内部碎片 (No internal fragmentation) ,分配速度极快。
Linux地址空间实例
从高地址到低地址:
- Kernel Space: 内核空间 (用户不可访问)。
- Stack (栈): 函数调用栈帧,局部变量, 向下增长 (Grows downward) 。
- Memory Mapping Region: 共享库 (Shared libraries),mmap。
- Heap (堆): 动态内存分配 (malloc), 向上增长 (Grows upward) 。
- BSS Segment: 未初始化的全局变量。
- Data Segment: 已初始化的全局变量。
- Text Segment: 存放代码 (Program code)。
计算题
有效访问时间(Effective Access Time, EAT)
吃(eat),有端联想:)
公式:
$$
EAT = (1 - p) \times \text{Memory Access Time} + p \times \text{Page Fault Overhead}
$$
- $p$: 缺页率 (Page Fault Rate, $0 \le p \le 1$)。
- Memory Access Time: 内存访问时间 (通常为纳秒级, ns)。
- Page Fault Overhead: 缺页中断处理总开销 (通常为毫秒级, ms)。
- 注意单位换算:1 ms = 1,000,000 ns
页面置换算法(Page Replacement Algorithms)
题型: 给定一个引用串 (Reference String) 和 物理帧数 (Number of Frames) ,计算缺页次数。
PPT 经典案例 (Reference String):7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1
(假设有 3 个帧)
| 算法名称 (English) | 核心规则 (Rule) | 缺页次数 (PPT结果) | 备注 |
|---|---|---|---|
| FIFO(First-In-First-Out) | 先进先出 :替换在内存中驻留时间最长的页面。 | 15 | 存在Belady 异常(帧数增加,缺页反而增加)。 |
| OPT(Optimal) | 最佳置换 :替换未来最长时间不会被访问的页面。 | 9 | 理论最优,无法实现,用于作为评估标准。 |
| LRU(Least Recently Used) | 最近最少使用 :替换过去最长时间未被访问的页面。 | 12 | 性能接近 OPT,无 Belady 异常。实现常用栈或 计数器 。 |
二次机会算法(Second Chance/ Clock Algorithm)
- 机制:基于FIFO,但是增加一个引用位(Reference Bit)
- 规则:
- 检查队首页面的引用位。
- 若为
0: 替换该页 (Replace it)。 - 若为
1: 给它“第二次机会”,将引用位清零 (0),并将其移到队尾(或指针移动到下一页),继续检查下一个。
注意:老师PPT上明确指出:第一次换入页面时,访问位为0。
Buddy System计算
给定内存总大小,进行一系列分配和释放。规则:
- 向上取整到最近的 $2$ 的幂 (Round up to next power of 2)。
- 分裂:如果你需要 21KB,现有 256KB 块。
- $256 \rightarrow 128 + 128$
- $128 \rightarrow 64 + 64$
- $64 \rightarrow 32 + 32$ (分配一个 32KB 块给 21KB 请求)。
10章:文件系统
概念考察
文件概念
定义:文件是记录在二级存储 (Secondary Storage) 上的相关信息的命名集合 (Named collection of related information)。
- 逻辑视图(Logical View):用户讲文件视为一个连续的逻辑地址空间。
文件属性:
- Name : 唯一以人类可读形式保存的信息 (Only info in human-readable form)。
- Identifier : 文件系统内的唯一标签/数字 (Unique tag/number)。
- Type : 支持不同类型系统的需要 (e.g., .exe, .txt)。
- Location : 指向设备上文件位置的指针 (Pointer to file location)。
- Size : 当前文件大小。
- Protection : 控制谁能读、写、执行 (Controls reading, writing, executing)。
- Time, date, and user identification : 用于保护、安全和监控。
- 注意 : 文件信息保存在 目录结构 (Directory Structure) 中,具体体现为 文件控制块 (FCB, File Control Block) 。
文件操作(File Operations)
基本操作:
- Create : 分配空间 (Allocate space),在目录中创建条目 (Create directory entry)。
- Write : 在写指针 (Write pointer) 处写入。
- Read : 在读指针 (Read pointer) 处读取。
- Reposition within file (Seek) : 修改文件位置指针,不涉及 I/O。
- Delete : 释放空间 (Erase space),删除目录项 (Erase directory entry)。
- Truncate : 清空内容但保留属性 (Erase contents but keep attributes)。(易混淆点:Delete vs Truncate)
Open & Close :
- Open( $F_i$ ) : 搜索目录找到 $F_i$ 的条目,并将内容复制到内存中的 打开文件表 (Open-file table) 。
- 返回一个指向打开文件表条目的指针(在 Unix/Linux 中称为 File Descriptor ,Windows 中称为 File Handle )。
- Close( $F_i$ ) : 将内存中打开文件表的内容写回磁盘目录结构(如果需要),并从打开文件表中移除该条目。
打开文件表(Open-file table)中包含的信息:
- File pointer : 指向最后的读写位置 (Last read-write location)。每个打开该文件的进程都有一个唯一的指针。
- File open count : 多少个进程打开了该文件 (Reference count)。
- Disk location : 文件在磁盘上的物理位置。
- Access rights : 进程的访问模式 (Read/Write mode)。
文件访问方法(Access Methods)
顺序访问(Sequential Access):
- 基础磁带模型(Tape model)
- 操作:
read next,write next,rewind(重置到头部)。
直接访问(Direct Access/Relative Access):
- 基于磁盘模型。文件被视为块的序列 (Sequence of blocks)。
- 可以跳转到任意块 $n$ (Read $n$, Write $n$)。
- 相对块号 (Relative block number) : 允许 OS 决定文件放置位置,防止用户访问物理块。
索引访问 (Index-based Access) :
- 使用索引来查找记录。
目录结构(Direct Access/ Relative Access)
目录本身也是存储在磁盘上的文件。
常见结构:
- Single-level Directory:所有文件在同一个目录中。问题:命名冲突 (Naming problem),分组困难 (Grouping problem)。
- Two-level Directory:每个用户有自己的目录 (UFD, User File Directory)。解决了命名冲突,但隔离了用户,不利于共享。
- Tree-Structured Directories:树形结构,有根目录 (Root)。
- 绝对路径 (Absolute path) vs 相对路径 (Relative path) 。
- Acyclic-Graph Directories(无环图):允许文件共享(File Sharing)。
- 同一个文件可以出现在两个不同的目录中。
- 实现方式: Link (Unix 硬链接/软链接)。
- 问题: 删除文件时可能产生悬空指针 (Dangling pointer);遍历时可能重复统计。
文件挂载(File System Mounting)
文件系统必须先Mount才能被访问
Mount point:挂载点,即文件系统被附加到的目录位置。
计算题
权限计算(Permission/Protection)
Unix/Linux 使用 Access Bits (访问位) 来控制权限。
用户分类:
- Owner(所有者)
- Group(同组用户)
- Public/Others(其他所有人)
权限模式:
- R(Read) = 4
- W(Write) = 2
- X(Execute) = 1
计算方法(chmod命令):
- 例子:chmod 761 game
- 7 (Owner) = $4+2+1$ = RWX (Read, Write, Execute) -> Binary
111 - 6 (Group) = $4+2$ = RW- (Read, Write) -> Binary
110 - 1 (Public) = $1$ = –X (Execute only) -> Binary
001
文件指针偏移量计算(File Offset/ lseek)
概念:Current-file-position-pointer (cfo - current file offset)
操作:lseek(fd, offset, origin)
逻辑:
- 打开文件时,cfo通常初始化为0。(除非是Append模式)
- Read(n):cfo = cfo + n
- Write(n):cfo = cfo + n
- lseek(n):手动设置cfo;
11章:文件系统实现
概念考察
文件系统结构(File System Structure)
分层结构 (Layered File System) : 理解各层的功能。
- I/O Control : 包括设备驱动 ( Device Drivers ) 和中断处理,负责内存与磁盘间的信息传输。
- Basic File System : 向设备驱动发送通用命令(读/写物理块)。
- File-organization Module : 负责逻辑块 ( Logical Block ) 到物理块 ( Physical Block ) 的映射;管理空闲空间 ( Free Space Management )。
- Logical File System : 管理元数据 ( Metadata ),维护文件控制块 ( FCB - File Control Block ) 和目录结构。
虚拟文件系统 (VFS - Virtual File Systems) :
- 目的 : 允许不同的文件系统(如 FAT32, NTFS, ext2)通过统一的 API ( Generic API ) 被访问。
- 作用 : 分离文件系统的通用操作与具体实现。
- Linux VFS : 使用 Inode 和 Dentry 对象。
磁盘上的结构
- Boot Control Block (引导控制块) : 包含从该卷启动 OS 所需的信息 (UFS 中称为 Boot Block , NTFS 中称为 Partition Boot Sector )。
- Volume Control Block (卷控制块) : 记录分区的详细信息,如块大小、块总数、空闲块指针等 (UFS 中称为 Superblock )。
- Directory Structure (目录结构) : 组织文件。
- File Control Block (FCB) : 包含文件的所有详细信息(权限、拥有者、大小、数据块指针等)。
- 在 Unix/Linux 中称为 Inode (Index Node) 。
- 考点 : FCB 中包含哪些信息?(文件名通常不在 FCB 中,而在目录项中)。
内存中的结构
用于缓存文件系统信息以提高性能。
- Mount Table : 记录已挂载分区的信息。
- System-wide Open-file Table (系统打开文件表) : 包含所有打开文件的 FCB 副本。
- Per-process Open-file Table (进程打开文件表) : 包含指向系统打开文件表的指针,以及当前文件偏移量 ( Current File Pointer/Offset )。
- 文件打开过程 (Open File Operation) :
- 调用
open()。 - OS 检查系统表中是否已有该文件。
- 如果有,增加引用计数 ( Open Count )。
- 如果没有,从磁盘读取 FCB 到内存的系统表。
- 在进程表中新建条目指向系统表。
- 返回 File Descriptor (FD) 或 File Handle 给用户。
- 调用
目录实现
线性列表 (Linear List) : 文件名和数据块指针的列表。
- 优点: 编程简单。
- 缺点: 查找文件耗时 (Linear search time-consuming)。
哈希表 (Hash Table) : 使用哈希数据结构。
- 优点: 减少目录搜索时间。
- 缺点: 哈希冲突 ( Collisions )。
效率与性能(Efficiency and Performance)
缓存Cache:
- Buffer Cache(块缓存):缓存磁盘块
- Page Cache(页缓存):使用虚拟内存技术缓存文件数据(以页为单位)
- Unifued Buffer Cache(统一缓冲缓存):现代 OS (Linux) 使用页缓存同时处理内存映射 I/O ( Memory-mapped I/O ) 和常规 I/O (
read(),write()),避免双重缓存 (Double Caching) 的浪费。
磁盘调度优化技术
- Asynchronous Write (异步写) : 数据先写入缓存,稍后由系统刷入磁盘 (flush to disk)。
- Free-behind : 一旦请求了下一页,立即释放当前页(针对顺序访问优化)。
- Read-ahead (预读) : 请求第 i 页时,同时读取 i+1, i+2 页(针对顺序访问优化)。
RAM Disk(内存盘):
- 把一部分内存模拟成磁盘使用,速度极快,但数据易失。
计算题
磁盘分配方式
连续分配(Contiguous Allocation)
- 每个文件在磁盘上占用一组连续的块 ( Contiguous blocks )。由
Start Block和Length定义。 - 优点 : 支持 随机访问 (Random Access) ,读取速度快。
- 缺点:
- 外部碎片(External Fragmentation):磁盘空间浪费
- 文件大小难以动态增长
链接分配(Linked Allocation):
- 文件是磁盘块的链表 ( Linked List ),块可以分散。每个块包含指向下一个块的指针。
- 优点:无外部碎片
- 缺点:
- 只能顺序访问(Sequential Access Only),不支持随机访问
- 指针占用空间
- 实现:FAT(File Allocation Table)
- FAT表位于分区开头
- 计算题考点:
- 若指针长度为4bytes(32bits),最多支持多少个块?$2^{32}$个
- 最大文件大小 = $2^{32} \times \text{Block Size}$。
索引分配(Indexed Allocation)
- 所有指针放在一个索引块 (Index Block) 中。
- 优点 : 支持 随机访问 ,无外部碎片。
- 缺点 : 索引块的开销 ( Overhead )。
- 计算题考点 (重点! - Unix Combined Scheme) :
给定一个 Inode 结构:包含 12 个直接指针 ( Direct Blocks ),1 个单级间接指针 ( Single Indirect ),1 个双级间接指针 ( Double Indirect ),1 个三级间接指针 ( Triple Indirect )。
假设 Block Size = 4KB, Pointer Size = 4 Bytes。
问:能支持的最大文件大小是多少?
- 直接块能存 : $12 \times 4\text{KB} = 48\text{KB}$
- 单级间接块能存 : $(4\text{KB} / 4\text{B}) \times 4\text{KB} = 1024 \times 4\text{KB} = 4\text{MB}$
- 双级间接块能存 : $1024 \times 1024 \times 4\text{KB} = 4\text{GB}$
- 总大小 = 直接 + 单级 + 双级 + …
问:访问文件的第 N 块需要几次磁盘 I/O?
- 直接块: 1次 (读数据)
- 单级间接: 2次 (读索引 + 读数据)
- 双级间接: 3次 (读一级索引 + 读二级索引 + 读数据)
空闲空间管理
位图/向量图(Bit Vector /Bit Map)
- 用 1 bit 代表一个块 (0=allocated, 1=free)。
计算题考点 (PPT Page 43) :
如何找到第一个空闲块?
$$
\text{块号} = (\text{每个字的位数}) \times (\text{值为0的字的个数}) + \text{第一个1位的偏移量}
$$
例题 : 字长 16位。前4个字 (Word 0-3) 都是 0。Word 4 是 00001000... (假设从低位开始或者是特定的位模式,PPT例子里 Offset 是 11)。
计算: $16 \times 4 + 11 = 75$。即第 75 号块是空闲的。
其他方法:
- Linked List (空闲链表) : 遍历慢。
- Grouping (成组链接) : 第一个空闲块存储 n-1 个空闲块地址。
- Counting (计数) : 记录首块地址和连续空闲块的数量 (适用于连续分配)。
12章:存储结构
概念考察
存储设备层次结构 (Storage-device Hierarchy)
层次 (Hierarchy): 从上到下,速度变慢,容量变大,价格变低。
- Registers (寄存器)
- Cache (缓存)
- Main Memory (主存) - Volatile (易失性)
- Electronic Disk / SSD (固态硬盘)
- Magnetic Disk (磁盘) - Nonvolatile (非易失性) , Secondary Storage (二级存储)
- Optical Disk (光盘)
- Magnetic Tapes (磁带) - Tertiary Storage (三级存储)
机械硬盘物理结构(HDD)
物理组件:
- Platter(盘片)
- Track(磁道)
- Sector(扇区)
- Cylinder(柱面)
寻址:
- 硬盘被视为一个巨大的 一维逻辑块数组 (One-dimensional array of logical blocks) 。
- Mapping (映射):
- Logical Block Number (逻辑块号)
- $\rightarrow$
- <**Cylinder** (柱面), **Track** (磁道), **Sector** (扇区)>。
- 顺序:先填满一个磁道,再填满同一个柱面的其他磁道,最后从外向内移动到下一个柱面。
固态硬盘(SSD Solid-State Disks)
介质: 使用 NAND Flash (闪存)。
特性 (Characteristics):
- 无机械运动部件 ( No moving parts ),因此 Seek time (寻道时间) 和 Rotational latency (旋转延迟) 几乎为零。
- 可靠性 (Reliability): 抗震,但有写入寿命限制。
- 读写单位: 以 Page (页) 为单位读写 (4KB)。
- 擦除 (Erase): 必须先擦除 ( Erase ) 才能重写 ( Rewrite )。擦除以 Block (块,包含多个 Page) 为单位。这导致了 Write Amplification (写放大) 现象。
调度: 通常使用简单的 FCFS ,因为没有机械寻道开销。
磁盘管理 (Disk Management)
格式化 (Formatting):
- Low-level formatting / Physical formatting (低级/物理格式化): 将磁盘划分为扇区 (Sectors),通过磁盘控制器完成。包含 Header, Data area, Trailer (ECC)。
- High-level formatting / Logical formatting (高级/逻辑格式化): 操作系统创建文件系统 (File System),初始化空闲空间映射等。
Boot Block (引导块):
- 存放 Bootstrap program (引导程序) 的固定位置。
- 拥有引导分区的磁盘称为 Boot disk (启动盘) 或 System disk (系统盘)。
Bad Blocks (坏块): 不可靠的扇区,通常由硬件或操作系统进行 Sector Sparing (扇区备用) 或重映射来处理。
交换空间(Swap-Space Management)
- Swap Space(交换空间):磁盘上作为 Main Memory (主存) 扩展的部分(虚拟内存)。
- 通常作为独立的 Disk Partition (磁盘分区) 存在。
RAID结构(RAID Structure)
全称: Redundant Array of Independent Disks (独立磁盘冗余阵列)。
目的: 提高 Reliability (可靠性 - 通过冗余) 和 Performance (性能 - 通过并行)。
关键技术:
- Striping (条带化): 将数据分散存储在多个磁盘上(提高并行度/速度)。
- Mirroring (镜像): 将数据完全复制到另一个磁盘(提高可靠性)。
RAID 级别 (RAID Levels) - 考试重点:
- RAID 0 : Block Striping (条带化)。 无冗余 (Non-redundant) 。速度最快,但任意一盘坏则数据全丢。
- RAID 1 : Mirroring (镜像)。最昂贵,写入性能略低,读取性能好,可靠性高。
- RAID 5 : Block-Interleaved Distributed Parity (块交错分布式奇偶校验)。数据和校验码 (Parity) 分散在所有 N+1 个磁盘上。允许坏 1 块盘。
- RAID 6 : P+Q Redundancy 。双重校验,允许坏 2 块盘。
计算题
磁盘性能指标(Performance Measures)
总访问时间 (Total Access Time) = 寻道时间 + 旋转延迟 + 传输时间 + 控制器开销
- Seek Time (寻道时间): 磁臂移动到指定 Cylinder (柱面) 的时间。通常题目会直接给出平均值。
- Rotational Latency (旋转延迟): 磁盘旋转将指定 Sector (扇区) 移到磁头下的时间。
- 公式: 平均旋转延迟 = $\frac{1}{2} \times \frac{60 \text{ seconds}}{\text{RPM (转速)}}$
- 例如 7200 RPM: 一圈需要 $60/7200 = 0.0083s = 8.33ms$。平均延迟 = $8.33 / 2 \approx 4.17ms$。
- Transfer Time (传输时间): 读取数据所需时间。
- 公式: $\frac{\text{Data Size (数据大小)}}{\text{Transfer Rate (传输速率)}}$
磁盘调度算法
给定一个请求队列 (Request Queue) 和当前磁头位置 (Head Start),计算 Total Head Movement (磁头移动总距离/总柱面数)。
算法:
FCFS(First-Come, First-Served)
- 按请求到达的顺序服务。
SSTF(Shortest Seek Time First)
- 优先选择距离当前磁头 最近 (Minimum seek time) 的请求
SCAN
- 磁头就像电梯,从一端移动到另一端 ( One end to the other ),处理沿途所有请求,到达顶端后 反向 (Reverse) 。
C-SCAN
- 类似于 SCAN,但到达一端后,立即返回 (Immediately returns) 到磁盘的开头(0),返回途中 不服务 (Without servicing) 任何请求。相当于单向电梯。
LOOK/C-LOOk
- 类似 SCAN / C-SCAN,但磁头 只移动到最远的请求位置 (Only goes as far as the final request) , 不走到磁盘物理端点 (0 或 199) 。
13章:I/O系统
概念考察
I/O系统架构(I/O System Architecture)
I/O设备:硬件本身(如磁盘Disk、 鼠标 mouse)
设备控制器(Device Controller / Host Adapter):
- 控制端口、总线、设备
- 包含的寄存器:
- 状态寄存器(Status Register):指示忙/闲状态
- 控制寄存器(Control Register):接收命令
- 数据输入寄存器(Data-in Register):读取数据
- 数据输出寄存器(Data-out Register):写入数据
- 功能:控制基本I/O操作,在设备和控制器寄存器之间传输数据。
I/O子系统(I/O Subsystem):
- 内核I/O子系统(Kernel I/O Subsystem):
- 负责调度(Scheduling)
- 缓冲(Buffering)
- 缓存(Caching)
- 假脱机(Spooling)
- 错误处理(Error Handling)
- 驱动程序(Device Drivers):
- 隐藏设备细节(Encapsulate/Hide details)
- 提供统一接口(Uniform Interface)
层次结构(Layered Structure):
Hardware -> Device Controller -> Device Driver -> Kernel I/O Subsystem -> Application I/O Interface.
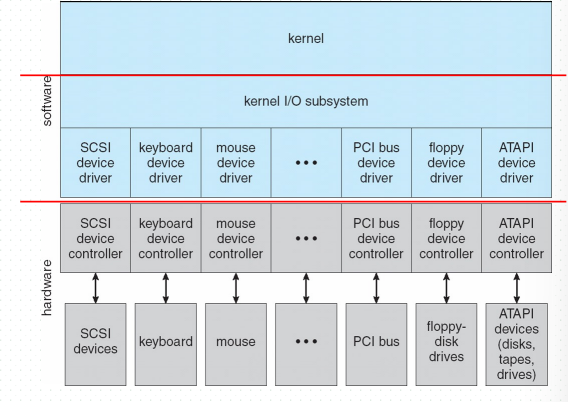
I/O硬件基础
总线(Bus):
- PCL Bus:连接处理器-内存子系统(Processor-memory subsystem)和快速设备
- Expansion Bus(扩展总线):连接慢速设备如keyboard,serial port(串口)
- SCSI(Small Computer System Interface):通常连接磁盘
- PCLe(Pcl Express):高吞吐量(High throughput)
通信方式:
- 端口:设备连接点
- I/O独立编址(Direct I/O Instructions):使用专门的I/O指令(Special I/O instructions)。
- 内存映射(Memory-mapped I/O):
- 控制器寄存器映射到内存地址空间
- CPU使用标准内存指令(LOAD, STORE)访问设备
- 效率更高,适合显卡等大数据量设备
3种I/O控制方式
轮询(Polling/ Busy-waiting)
中断(Interrupt) 内中断
- 设备准备好后发送信号给CPU
- CPU响应中断(Catch interrupt),执行中断处理程序(Interrupt Handler)
- 效率高于轮询
DMA(Direct Memory Access, 直接访问内存)
- 用于大数据快传输
- CPU 只需设置 (Set up) DMA 控制器的寄存器(源/目的地址 Source/Destination、计数器 Counter)。
- DMA 直接在设备和内存之间传输数据 (Transfer directly between device and memory),无需 CPU 干预 (Without CPU intervention)。
- 传输完成后,DMA 发送一个中断 (One interrupt per block) 给 CPU。
应用程序I/O接口
块设备(Block Devices):
- 以块 (Block) 为单位传输(如 Disk)。
- 支持
read(),write(),seek()(随机访问 Random Access)。 - Raw I/O : 绕过文件系统直接访问 (Access directly bypassing file system)。
字符设备(Character-stream Devices):
- 以字节流 (Stream of bytes) 传输(如 Keyboard, Mouse, Serial ports)。
- 支持
get(),put()。
网络设备(Network Devices):
- Socket 接口 (Socket Interface)。
时钟与定时器(Clocks and Timers):
- 提供当前时间 (Current time)、经过的时间 (Elapsed time)。
- 产生定时中断 (Trigger periodic interrupts)。
I/O模型
阻塞I/O(Blocking I/O):
- 进程发起I/O后被挂起(Process is suspended/moved to wait queue)
- 直到 I/O 完成 (Until I/O completion)。
- 大多数操作系统默认采用 (Default)。
非阻塞I/O(Non-blocking I/O):
- 进程发起 I/O 后不挂起,立即返回 (Returns immediately)。
- 通常结合多线程 (Multi-threading) 使用。
异步I/O(Asynchronous) I/O:
- 进程发起调用后立即返回,继续执行 (Continues execution)。
- 当 I/O 完成后,系统通知进程 (Signal process when I/O completed)。
内核I/O子系统功能(Kernel I/O Subsystem Functions)
I/O 调度 (I/O Scheduling) :
- 重排 I/O 请求顺序 (Reorder I/O requests)。
- 目的:减少等待时间 (Reduce waiting time),保证公平性 (Fairness)。
缓冲 (Buffering) : 在内存中临时存储数据 (Store data in memory while transferring)。 三个主要原因 (Three major reasons) :
- 解决 速度不匹配 (Cope with device speed mismatch )。
- 解决 传输大小不一致 (Cope with device transfer size mismatch )。
- 支持 “拷贝语义” (Maintain “copy semantics” )。
缓存 (Caching) :
- 保存数据副本 (Hold copy of data)。
- 目的:提高访问速度 (Improve performance),利用局部性 (Locality)。
假脱机 (Spooling - Simultaneous Peripheral Operation On-Line) :
- 将独占设备 (Dedicated device,如 Printer) 模拟为共享设备 (Shared device)。
- Daemon (守护进程) : 实际上控制设备打印。
- Queue (队列) : 数据暂存在磁盘的 Spool 目录中。
错误处理 & 保护 (Error Handling & I/O Protection) :
- I/O 指令通常是特权指令 (Privileged instructions)。
- 必须通过系统调用 (System Calls) 执行。
I/O请求的生命周期
- 请求 : 用户进程发起
read()系统调用。 - 检查 : 内核检查参数。如果数据在 Cache 中,直接返回。
- 排队 : 如果需要物理 I/O,I/O 子系统将请求排队,进程阻塞 (Blocking)。
- 驱动 : 驱动程序分配缓冲区,向设备控制器寄存器写入命令。
- 硬件操作 : 设备控制器操作硬件,传输数据(可能通过 DMA)。
- 中断 : 数据传输完成,产生中断。
- 处理 : 中断处理程序接收数据/状态,通知驱动程序。
- 完成 : 驱动程序通知 I/O 子系统,将数据从内核传送到用户空间,将进程状态改为 就绪 (Ready) 。
- 唤醒 : 进程重新被调度执行。