CCF短期速成指北
c++
注意所有的数据结构都在std命名空间下使用。注意在代码开头加入:
using namespace std;为节省时间可以:
typedef long long ll;如果long long 也无法满足你,请依次尝试:
unsigned long long__int128unsigned __int128CCF真的很狗,如果你不确定会不会超过long long,请直接使用
unsigned __int128
IO简要熟悉
IO优化
C++默认输入输出(cin/cout)为了兼容C语言的输入输出,做了一些额外的工作,导致它们比C语言慢很多。
基础IO优化就是关掉这些额外工作,导致让 cin和 cout跑的飞快,甚至比 scanf还快。
1 | |
ios::sync_with_stdio(false):- 取消C++标准流与C标准流的同步
- 副作用:不能再使用
sanf、printf、getchar等c语言风格的代码
cin.tie(nullptr):- 解除
cin和cout的绑定 - 作用:执行
cin之前,不会再检查输出缓冲区中的是否有东西。
- 解除
尽量别使用 endl:
cout << endl;等价于cout << "\n" << flush;- 不仅会换行,还会强制刷新缓冲区。
- 优化方法:在输出大量数据(比如输出N个换行)时,请使用
"\n"代替endl
1 | |
在acwing中某一题中,开启io优化前后效果如下:

上方的提交无IO优化
下方的提交开启了IO优化
时间缩短了 1/3。
格式化输出
如果你关闭了同步流,对于程序的输出,建议只使用 cout或 printf()中的一种。
保留N位小数
1
printf("%.2lf\n",x); //输出3.14,保留两位小数补0
1
printf("%03d\n", t); //输出005,凑齐三位
字符串与整行读取(T3 大模拟)
cin >> s遇到空格就会停止。如果题目说”输入一行包含空格的指令”,必须用 getline.
1 | |
注意事项
如果你先读取了一个数字,紧接着要读取一行字符串,必须手动处理前一行遗留的回车符。
1 | |
stringstream 空格切割机
使用 getline()读取一行的数据后,我们往往还需要解析期中的内容。
1 | |
字符串$\leftrightarrow$数字转换
字符串转数字:#include <string>
stoi():string To intstoll():string To long longstof():string To floatstod():string To double
数字转字符串:
1 | |
格式化读取
在处理固定格式的字符串时,C语言的 sscanf()比正则表达式还好用。
场景:题目输入日期格式 2025-11-21 或 IP 地址 192.168.1.1。
1 | |
实际使用时,先使用
cin或getline等方法读取字符串,再使用sscanf()解析数据
容器(vector)
C++中的 vector等于Java中的 ArrayList。
头文件:#include <vector>
创建空int类型示例:
1 | |
快速初始化:
1 | |
常用方法
获取大小
1 | |
获取最后一个元素
1 | |
插入
末尾插入:
1
myVector.push_back(7); //将7添加到末尾中间插入:
1
2myVector.insert(myVector.begin(), 5); //将5添加到下标为0位置
myVector.insert(myVector.begin()+2,10);//将10添加到下标为2的位置
访问
随机访问:
1 | |
遍历访问:
1 | |
1 | |
1 | |
1 | |
删除元素
删除末尾元素:
1
myVector.pop_back();删除指定下标元素:
1
myVector.erase(myVector.begin()+2); //删除下标为2的元素删除连续多个元素:
1
myVector.(myVector.begin()+1, myVector.begin()+4); //删除下标[1,4)的元素清空所有元素:
1
myvector.clear();
排序Sort
头文件:#include <algorithm>
默认升序排序:
1 | |
自定义排序规则:
1 | |
a > b 为为降序排列,a < b为升序排列。
- greater<>:降序
- less<>:升序
记忆技巧:
当我们参数申明顺序为
bool cmp(int a , int b)时,在返回比较结果前,我们依然将a写在前,b写在后如a b。我们将a、b当作排序后列表中的相邻元素,顺序同样为a在前,b在后。
如果为升序即为前面的元素a小,后面的元素b大,则
a < b如果降序则前面的元素a大,后面的元素b小,则
a > b
引用
C++中的引用与Java中的引用概念相似,是一种为已有变量起别名的机制。
为什么在这里突然讲解引用呢?因为在给sort函数传递自定义 cmp函数时,我们一定要注意什么时候我们必须传递引用。这会极大的影响程序的运行时间。我们结合一道leetcode中的题目为例:
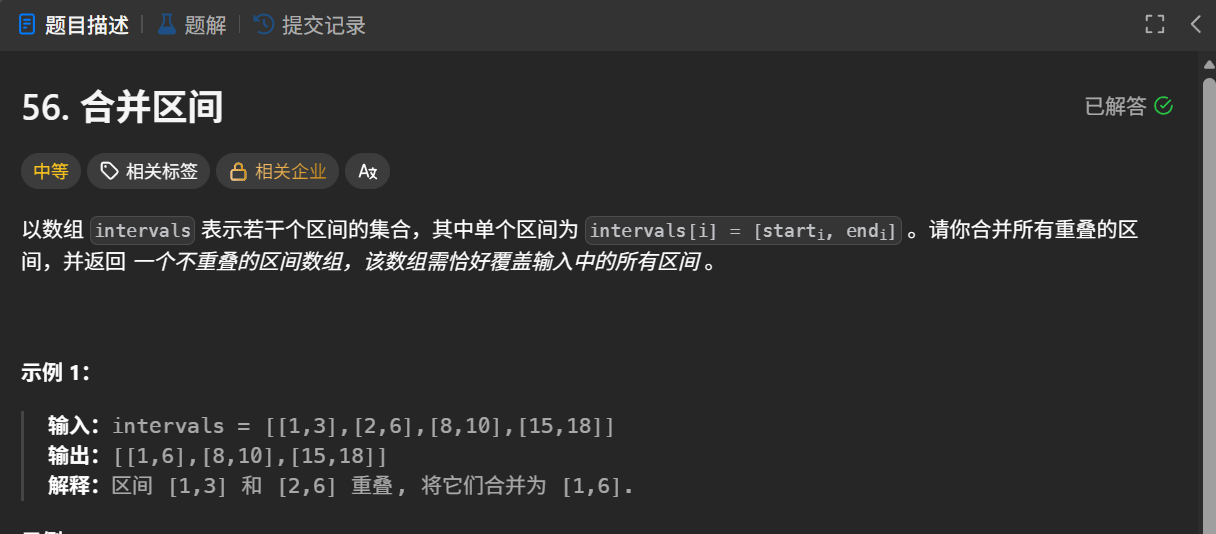
这道题的常见思路如下:
1 | |
由于我们比较的是 vector<int>类型,所以我传入 cmp方法,定义按照数组的首元素降序排序。
此时它的运行时间如下:
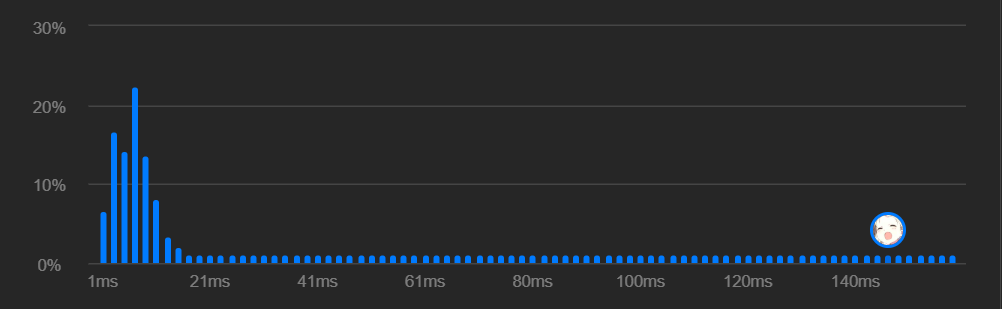
为什么这么慢呢?就是因为 cmp方法中我没有传 vector<>的引用,而是直接传了形参。此时c++在传递参数时会将原本的 vector<int>完整的拷贝一遍,这不仅浪费大量的空间,还浪费大量的时间。
我们仅需将cmp做小小改动如下:
1 | |
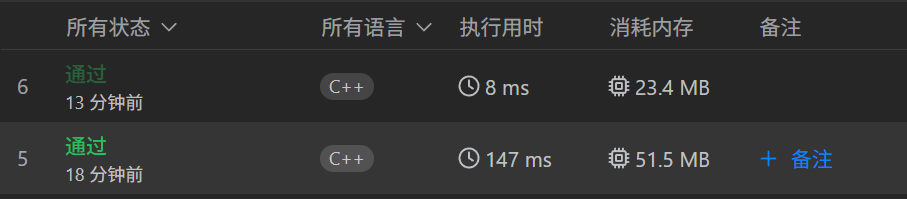
不管是时间还是空间都可以得到大幅优化。
Map
在c++中,常用的map有4种,分别是 std::map、std::multimap、std::unordered_map、std::unordered_multimap。
| 容器类型 | 底层结构 | 是否有序 | 键是否唯一 | 查找时间复杂度 | 头文件 |
|---|---|---|---|---|---|
std::map |
红黑树 | 有序 | 唯一 | O(log n) | <map> |
std::multimap |
红黑树 | 有序 | 可重复 | O(log n) | <map> |
std::unordered_map |
哈希表 | 无序 | 唯一 | O(log n) | <unordered_map> |
std::unordered_multimap |
哈希表 | 无序 | 可重复 | O(log n) | <unordered_map> |
通用属性:
map.size()map.empty()map.begin()
创建map
四种哈希表的默认构造都一样,只需声明键和值的数据类型即可:
1 | |
有序Map
基于红黑树实现的 map和 multimap可以指定比较器:
1 | |
自定义比较器:
1 | |
哈希Map
基于哈希表实现的 ordered_map和 ordered_multimap,可以指定哈希函数和相等比较器:
1 | |
与java中相同,如果map中存储的为自定义类型,一定要同时重写
MaHash和MyEqual方法。
插入元素
四种map的插入元素均可使用:
1 | |
针对 map和 unorder_map唯一键的map,可以使用操作符 []。
1 | |
查找元素
find(key)- 返回指向第一个匹配元素的迭代器
- 如果没找到返回end()
count(key)- 返回匹配该键的元素的数量
- 唯一键map返回0/1
- 重复键返回值可能大于1
equal_range(key)- 返回一对迭代器,表示所有匹配该键的范围。
修改元素
唯一键map
- 支持操作符
[]:
1 | |
- 使用迭代器:
1 | |
重复键map
只能通过迭代器修改:
1 | |
mm.equal_range():返回一对迭代器,表示所有匹配该键的范围。range.first指向匹配的第一个元素位置range.second指向最后一个匹配元素的下一个位置
如果在重复键map中使用
.find(),会返回第一个匹配的元素。
删除元素
- 按键删除:
1 | |
- 唯一键map:删除该键唯一定义元素。
- 重复键map:删除该键对应的所有元素。
- 按迭代器删除:
1 | |
- 清空容器
1 | |
Pair
头文件:#include <utility>
用来存储两个数据成员,可以是不同类型的两个值。
创建pair
1 | |
访问元素
- first:第一个值
- second:第二个值
1 | |
修改元素
1 | |
比较操作
pair支持比较运算符(==,<,>等)
比较规则:先比较 first,如果相等再比较 second
1 | |
Set
set的实现与Map类似,常用的有四种:set、multiset、unordered_set、unordered_multiset。
| 容器类型 | 底层结构 | 是否有序 | 键是否唯一 | 查找时间 | 时间复杂度 | 头文件 |
|---|---|---|---|---|---|---|
| set | 红黑树 | ✅ 有序 | ✅ 唯一 | O(log n) | 插入/删除/查找 O(log n) | <set> |
| multiset | 红黑树 | ✅ 有序 | ❌ 可重复 | O(log n) | 插入/删除/查找 O(log n) | <set> |
| unordered_set | 哈希表 | ❌ 无序 | ✅ 唯一 | 平均 O(1),最坏 O(n) | 插入/删除/查找 平均 O(1) | |
| unordered_multiset | 哈希表 | ❌ 无序 | ❌ 可重复 | 平均 O(1),最坏 O(n) | 插入/删除/查找 平均 O(1) |
通用属性:
- size()
- empty()
创建Set
set的创建与map相似,只不过只需要传入一个数据类型即可:
1 | |
有序set可以传入比较器:
1 | |
哈希表set可以传入哈希函数和相等比较函数。
1 | |
插入元素
四种set都使用 insert()方法进行插入,只是唯一元素set和重复元素set的insert()方法返回值略有不同。
唯一元素set:
- 返回:
pair<iterator, bool>iterator:指向元素的位置bool:表示是否插入成功
set、map等排序元素,迭代器不能加减运算,但可以自增。
1 | |
可重复元素set:
- 返回:
iterator:指向新插入的元素。
1 | |
批量插入:insert(first, last);
接收两个迭代器first和last表示插入的范围 [first, last),这两个迭代器可以来自任何符合标准的容器(如 std::vector、std::list 等),此时它没有返回值。
该方法批量插入其他容器的值。
1 | |
查找元素
所有的set都支持以下四种查找方法:
find(key):返回迭代器。count(key):返回匹配元素个数。- set中只能是0/1
- multiset中可能大于1
equal_range(key):返回一对迭代器,表示所有匹配元素的范围。
1 | |
删除元素
所有的set都支持使用erase()方法来删除元素:
erase(iterator pos):删除迭代器指向的元素。erase(key):删除值为 key 的元素- set:删除一个元素
- multiset:删除所有相等元素
- 返回成功删除元素的个数
erase(iterator first, iterator last):批量删除。- 对于无序set可能意义不大。
- 对于有序set可以删除一个大小区间内的所有值
clear():删除所有元素。
1 | |
批量删除与批量插入不同,批量删除时的首尾迭代器都只能来自 set自己。
1 | |
set运算
set运算的函数在头文件 #include <algorithm>中,不仅可以对 set类型使用,对于 vector<>等页可以使用。
set运算对于unordered_set不可用。
取交集
取交集使用函数:set_intersection()
1 | |
取并集
取并集使用函数:set_union()
1 | |
Deque
Stack
Stack 是容器适配器,底层基于 deque
容器适配器:不是新的容器,而是对已有容器的封装,提供更简化、更特定的接口。
头文件:#include <stack>
栈的使用非常简单,只有几种常见的简单操作:
- 创建栈:
1 | |
- 常用操作
s.push(x):将元素压入栈顶s.pop():弹出栈顶元素(不返回值)s.top():访问栈顶元素s.empty():判断栈是否为空s.size():返回栈中元素数量
Queue
Queue也是适配性容器。底层是 deque
头文件:#include <queue>
- 创建队列:
1 | |
- 常用操作
q.push(x):在队尾插入元素q.pop():删除队头元素(不返回值)q.front():访问队头元素q.back():访问队尾元素q.empty():判断队列是否为空q.size():返回队列中元素数量
Deque
双端队列。
头文件:#include <deque>
| 操作 | 功能说明 |
|---|---|
push_back() |
在尾部插入元素 |
push_front() |
在头部插入元素 |
pop_back() |
删除尾部元素 |
pop_front() |
删除头部元素 |
at(pos) |
返回指定位置元素(带范围检查) |
operator[] |
返回指定位置元素(不检查范围) |
front() |
获取第一个元素 |
back() |
获取最后一个元素 |
begin()/end() |
获取迭代器(正向遍历) |
size() |
返回元素个数 |
empty() |
判断容器是否为空 |
clear() |
清空所有元素 |
insert() |
在指定位置插入元素 |
erase() |
删除指定位置或区间元素 |
String
截取、查找、拼接
截取子串 substr()
语法:
s.substr(pos, len):指定开始位置与截取的长度s.substr(pos):未指定长度,将截取从pos开始的所有字符
1 | |
查找位置 find()
查找某个字符或字串第一次出现的位置。
- 语法:
find(target):查找第一次出现的位置。find(target, pos):从pos下标开始找。
- 返回值:返回下标(
size_t类型) - 判空:如果找不到,返回
string::npos(这是一个常数)
1 | |
拼接 +和 +=
将多个字符串连接起来。
注意:尽量用
+=,效率略高于s = s +
1 | |
修改操作:删、插、换
删除 erase
- 语法:
s.erase(pos, len) - 作用:从
pos开始删除len个字符
1 | |
插入 insert
- 语法:
s.insert(pos, str) - 用途:在
pos下标之前插入字符串
1 | |
替换 replace
- 语法:
s.replace(pos, len, new_str) - 用途:将从
pos开始的len个字符替换为new_str
1 | |
类型转换
数字转字符串:
to_string(val)1
2int a = 123;
string s = to_string(a);字符串转数字:
- stoi(s):
int - stoll(s):转
long long(CSP建议用这个,防止溢出) - stod(s):转
double
- stoi(s):
常用算法
快速幂算法
将计算$a^b$的时间复杂度从O(b)降低到O(logb)
核心思想:二进制拆分
我们计算$3^{11}$。普通算术是:$3 \times 3 \times 3 \dots$ 乘 11 次。
快速幂的思想是利用二进制:
- 把指数11写成二进制:(1011)。
- 这意味着:$11 = 1 \times 2^3 + 0 \times 2^2 + 1 \times 2^1 + 1 \times 2^0 = 8 + 2 + 1$。
- 所以:
$$
3^{11} = 3^{(8 + 2 + 1)} = 3^8 \times 3^2 \times 3^1
$$
我们只需要知道$3^1, 3^2, 3^4, 3^8 \dots$这些权重为2的幂次的值,然后把二进制位为1的那些项乘起来即可。
代码实现
通常题目会要求对结果取模:
1 | |
倍增法
倍增法的核心思想与快速幂相似:不要一步一步走,而是按2的幂次跳着走。
任何整数k都可以被分解为2的幂次之和(二进制表示)。例如:如果要走13步,二进制为(1101)8 + 4 + 1,我们只预先需要计算:
- 走$2^0 = 1$步到了哪。
- 走$2^1 = 2$步到了哪。
- 走$2^2 = 4$步到了哪。
- …
- 走$2^{30}$步到了哪。
然后组合这些跳板即瞬间可到达目的地。把O(k)的线性操作降维成O(log k)的操作。
预处理:造表
假设 dp[u][i]的物理意义是:从状态u出发,经过$2^i$步,到达的状态。
我们要从小到达填满这个 dp表。
dp[u[0]:走$2^0=1$步。这是题目直接告诉你的(比如a -> b)。dp[u][1]:走 $2^1=2$ 步。等于先走 1 步,再走 1 步。dp[u][i]:走 $2^i$ 步。等于先走 $2^{i-1}$ 步(一半),再从那里走 $2^{i-1}$ 步(另一半)。
状态转移的核心公式:
$$
dp[u][i] = dp[; dp[u][i-1] ;][i-1]
$$
查询:拼凑
给你一个任意大的整数K,我们把它拆成2进制,比如k = 13:(1101)
- 第 0 位是 1 $\rightarrow$ 跳 $2^0$ 步,更新位置。
- 第 1 位是 0 $\rightarrow$ 不跳。
- 第 2 位是 1 $\rightarrow$ 跳 $2^2$ 步,更新位置。
- 第 3 位是 1 $\rightarrow$ 跳 $2^3$ 步,更新位置。
模板代码:
1 | |
字符串编码
对于字符串的比较,等操作是比较耗费时间的,此时我们可以通过将字符串编码来将不太长的字符串编码为数字类型。
以 unsigned long long 类型为例,最长可以编13位不区分大小写的单词。
我们就以编码26位的小写字符串为例:
1 | |
这里有一个易错点,至少对于我来说是,最开始我实现的代码为:
1 | |
我将字母a-z,分别映射为数字0-25。一个字母对应一个数字,这很合理。
但是此时的问题是:当输入字符串AA和A时,由于我将字符A映射为0,所以这两个字符串编码是相等的,都是0。
所以将字母编码时,我们必须从1开始编码。
附一张使用编码前后效率如图:80ms->40ms

CCF做题有感
第一题:学会照着题目编程
CCF的第一道题一般都是非常简单的,不考察任何的算法以及优化,我们只需要照着题目的要求编程即可。题目怎么说我们就怎么写代码。
哪怕你想到了优化方法,也不要轻易尝试,这有会增加你花费在第一题上的时间。
第二题
找到背后的模型
第二题通常考察简单的算法模型,感觉基本范围都没有超过leetcode 热题100中的范围,只是有时我们可能看不出背后的算法模型。感觉像的就可以尽量关联一下。
38次第二题,是一个B****FS(广度优先搜索):
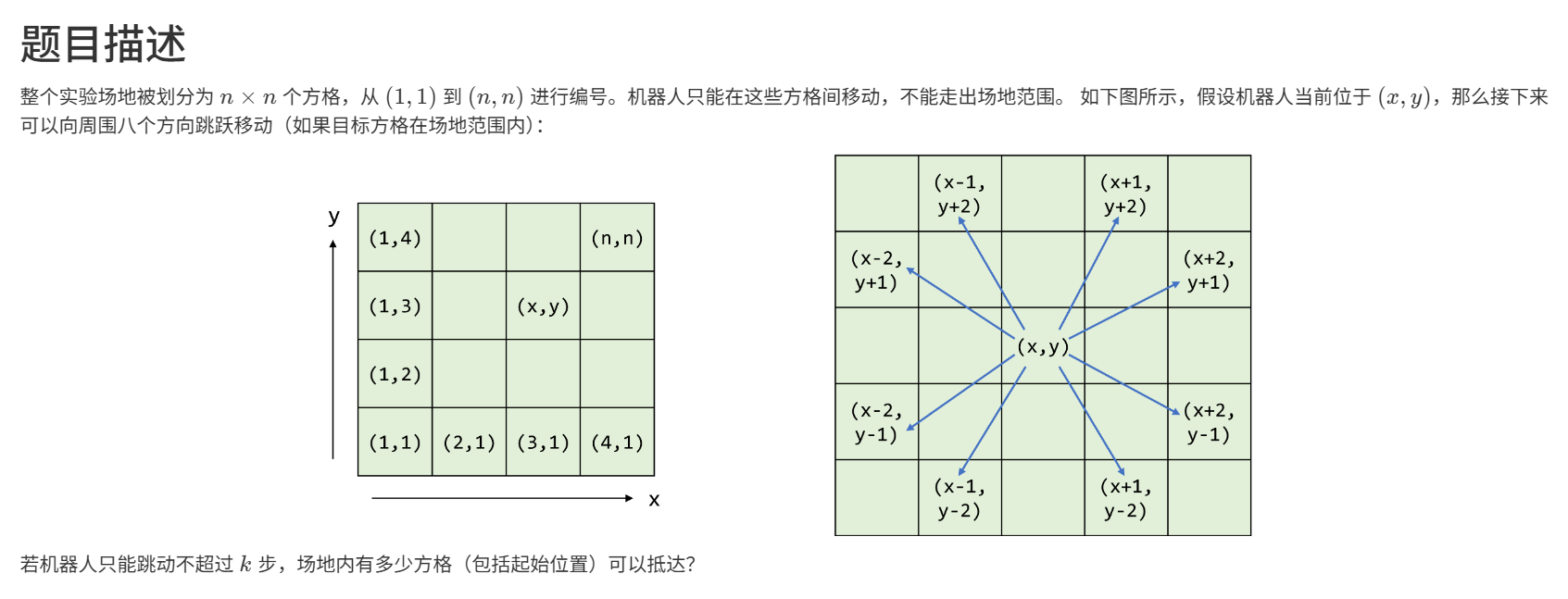
区分BFS与DFS的适用范围:
BFS(广度优先搜索):
- 覆盖范围、最短路径、层序遍历
DFS(深度优先搜索):
- 所有解、连通性、回溯
不过针对具体问题还是需要具体分析,建议当你考虑使用者两个算法其中一个时,不妨也仔细思考一下另一种方法。
37次第二题,是一个(不限数量)背包问题:

36次第二题,是一个前缀和与后缀和问题:
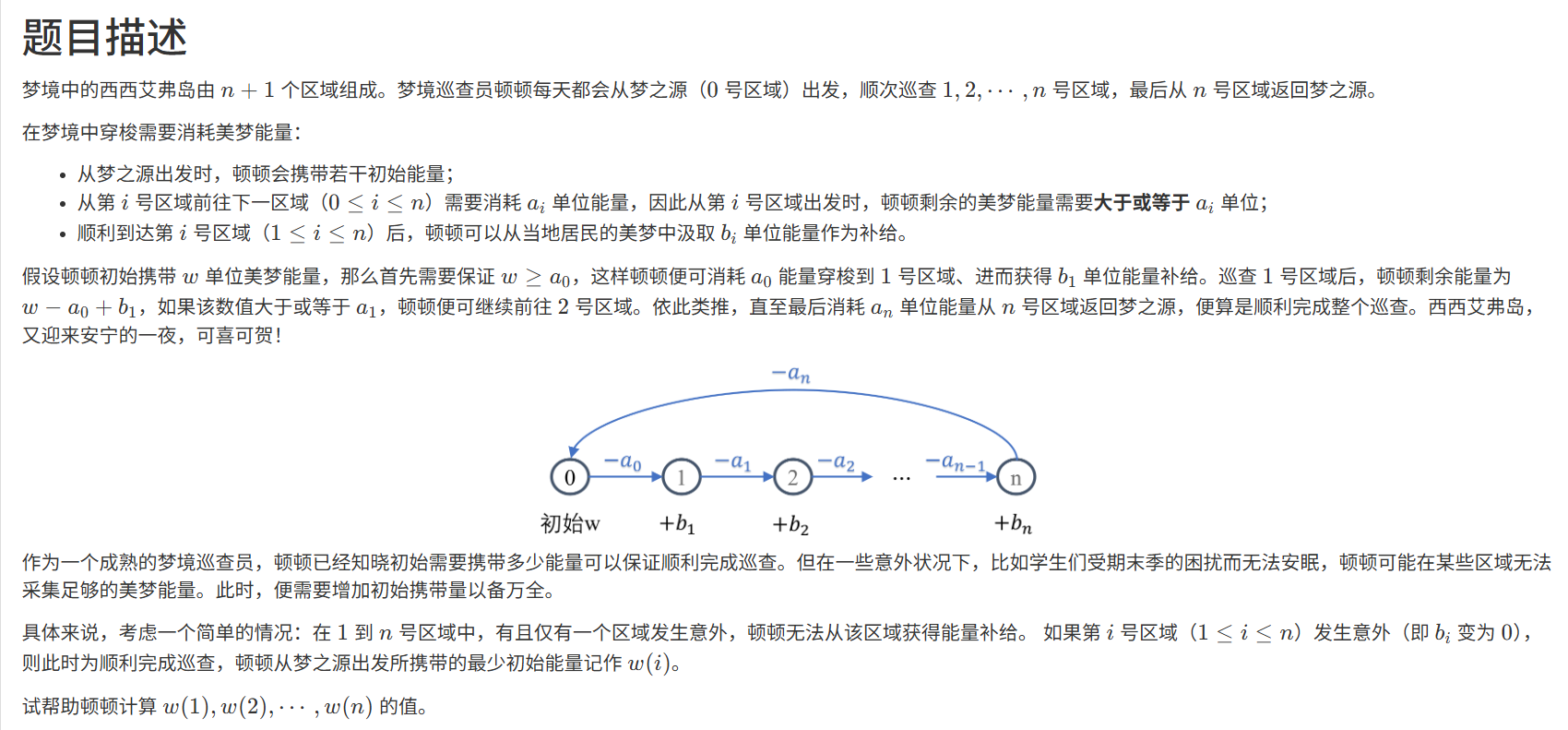
如果基础不太好这一题比较难一眼看出方法,要前提是要找到关系,携带的最少能量为:min{min(前缀中的最小值), min(后缀的最小值)- d_i }
找到CCF中的提示
CCF当前两道题的题目有相似内容时,第一题有可能会是第二题的提示,这种情况在33和34次CCF认证中均有出现。
34次CCF
34次CCF中的两题的关联很明显,分别是矩阵重塑(其一)和矩阵重塑(其二)。首先看看第一道题:

这里第一题的提示非常明显,直接提到针对矩阵重塑,我们可以将矩阵元素线性化,即使用一维数组来存储二维矩阵,最后通过n、m的值来计算二维下标。

第二题中,针对矩阵的重塑,我们即可采取第一题中的思路,使用一维数组来存储矩阵。当进行重塑操作时,我们只需要更新矩阵的n、m即可。不用实际修改数组的顺序。
33次CCF
33次的两题分别是词频统计与相似度计算。

第一题中明确提出一个思想:将英文单词转化为整数编号。

并且这里题目中明确表示每个单词最多包含10个字母,则我们可以使用将单词编码为字符串的思想,避免对进行string比较操作,而是直接使用整形,可以加快程序的速度。
会看子任务
在第30次的CCF认证中,第2题考察矩阵的运算:(感觉这题考试范围好超纲)

如果我们按照题目的给出的逻辑进行运算:
- 先计算$ A = Q \times K^T$ ,得到一个$n \times n$的矩阵。这一步复杂度是$O(n^2d)$。
- 再计算$R = A \times V $, 得到一个$ n \times d$的矩阵。这一步的复杂度也是$O(n^2d)$。
- 最后乘上权重W。
总时间复杂度为$O(n^2d)$。如果n = 10000,d = 20,运算量约为$ 2 \times {10}^9 $

但是我们观察子任务中的内容,n 的范围是远大于d的,也就是说不会出现d很大的矩阵,那么我们就可以通过矩阵的运算性质来改变运算顺序。
优化方案:
利用矩阵乘法的结合律 $(A \times B) \times C = A \times (B \times C)$。
我们可以先计算 $M = K^T \times V$。
- $K^T$ 是 $d \times n$ 矩阵,$V$ 是 $n \times d$ 矩阵。计算 $M = K^T \times V$ 得到一个 $d \times d$ 的矩阵。这一步复杂度是 $O(d^2 n)$。
- 然后计算 $Q \times M$。$Q$ 是 $n \times d$,$M$ 是 $d \times d$。这一步复杂度是 $O(n d^2)$。
总时间复杂度降低为$O(nd^2)$。速度提升非常明显。
CCF考矩阵运算,你是人啊?