链接
每日一言
I think manga and life are the same thing. A weekly manga lasts for a week, and life lasts until you die. It’s making the best of whatever time you’re given. So, you can’t hold back. “Conceit” and “Luck” are important, but the most important one is “Hard Work”. – Akito Takagi
from Bakuman.
编译器驱动程序
静态链接
链接器的两个主要任务:
- 符号解析: 目标文件定义和引用符号,每个符号对应于一个函数、一个全局变量或一个静态变量(即 C语言中任何以 static属性声明的变量)。符号解析的目的是将每个符号引用正好和一个符号定义关联起来。
- 重定位:编译器和汇编器生成从地址 0 开始的代码和数据节。链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改所有对这些符号的引用,使得它们指向这个内存位置。 链接器使用汇编器产生的重定位条目 (relocation entry) 的详细指令,不加甄别地执行这样的重定位。
目标文件
目标文件有三种形势:
- 可重定位目标文件,包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行目标文件。
- 可执行目标文件,包含二进制代码和数据,其形式可以被直接复制到内存并执行。
- 共享目录文件,一种特殊类型的可重定位目标文件,可以在加载或者运行时被动态地加载进内存并链接
编译器和汇编器生成可重定位目标文件(包括共享目录文件)。链接器生成可执行目标文件。
可重定位目标文件
可重定位目标文件概述:
可重定位目标文件(.o文件)是编译器编译源文件后但未进行链接的中间文件,包含:
- 代码段(.text)
- 数据段(.data)
- BSS段(.bss)
- 符号表
- 重定位信息
- 调试信息等
编译生成可重定位文件:
1 | |
查看文件结构:
1 | |
输出示例:
1 | |
详情可以见下面一节:
ELF可重定位目标文件的格式
ELF文件的作用
编译阶段 :
- 存储目标代码
- 保存符号信息
- 记录重定位信息
链接阶段 :
- 符号解析
- 重定位处理
- 地址分配
运行阶段 :
- 程序加载
- 动态链接
- 内存映射
调试阶段 :
- 提供调试信息
- 支持符号级调试
- 异常处理支持
ELF文件结构
- ELF头(ELF Header)
- 程序头表(Program Header Table)
- 节(Sections)
- 节头表(Section Header Table)
ELF头
ELF头(ELF header)以一个16字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。ELF头剩下的部分包含了含帮助链接器语法分析和解释目标文件的信息。其中包括:
- ELF头文件的大小
- 目标文件的类型
- 机器类型
- 节头部表的文件偏移
- 节头部表中条目的大小和数量
节
夹在ELF头和节头部表之间的都是节。一个典型的ELF可重定位目标文件包含下面几个节:
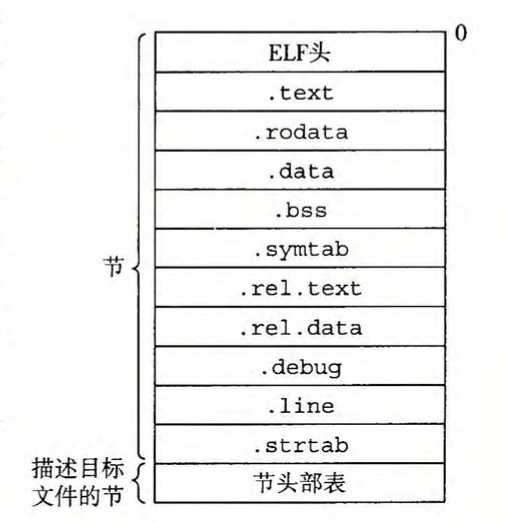
- . text: 已编译程序的机器代码。
- . rodate:只读数据,比如 printf 语句中的格式串和开关语句的跳转表。
- . data:已初始化的全局和静态 C 变量。局部 C变量在运行时被保存在栈中,既不出现在.data 节中,也不出现在.bss 节中。
- . bss:未初始化的全局和静态 C 变量,以及所有被初始化为0 的全局或静态变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。
- . symtab:一个符号表,它存放在程序中定义和引用的函数和全局变量的信息。
- .rel.text:一个 .text节中位置的列表,当链接器把这个目标文件和其他文件组合时,需要修改这些位置。
- .rel.data:被模块引用或定义的所有全局变最的重定位信息。
- .debug:一个调试符号表,其条目是程序中定义的局部变量和类型定义,程序中定义和引用的全局变量,以及原始的 C源文件。只有以-g选项调用编译器驱动程序时,才会得到这张表。
- .line:原始 C 源程序中的行号和.text 节中机器指令之间的映射。只有以-g选项调用编译器驱动程序时,才会得到这张表。
- .strtab:一个字符串表,其内容包括.symtab 和 .debug 节中的符号表,以及节头部中的节名字。字符串表就是以 null 结尾的字符串的序列。
符号和符号表(.symtab)
是ELF文件中存储符号信息的节。
每个可重定位目标模块m都有一个符号表,它包含m定义和引用的符号的信息。.symtable 中主要存储以下三种变量符号:
由模块 m 定义并能被其他模块引用的全局符号。全局链接器符号对应于非静态的 C函数和全局变量。
1
2
3// 全局符号示例
int global_var = 10; // 全局变量
void global_function() { } // 非静态函数由其他模块定义并被模块 m 引用的全局符号。这些符号称为外部符号,对应千在其他模块中定义的非静态 C函数和全局变量。
1
2
3// 外部符号示例
extern int global_var; // 引用其他文件定义的变量
extern void global_function(); // 引用其他文件定义的函数只被模块 m 定义和引用的局部符号。它们对应于带 static属性的 C 函数和全局变量。 这些符号在模块m 中任何位置都可见,但是不能被其他模块引用。
1
2
3// 局部符号示例
static int local_var = 20; // static全局变量
static void local_function() {} // static函数
注意,对于任何本地非静态变量,都不在.symtab的展示范围内。
比如如下例子:
1 | |
编译后的符号情况:
1 | |
可能的输出:
1 | |
符号表的基本属性
name: 符号的名称字符串在字符串表中的偏移位置
value: 符号的地址
- 在可重定位模块中:表示相对于所在节起始位置的偏移
- 在可执行文件中:表示绝对运行时地址
size: 符号占用的字节数
type: 符号类型,主要分为:
- 数据(data)
- 函数(function)
- 其他(如节名、源文件路径等)
binding: 符号的作用域
- 本地(local)
- 全局(global)
符号的节(Section)分配
- 每个符号都属于某个节
- section字段指向节头部表的索引
- 存在三种特殊的伪节(仅在可重定位目标文件中):
ABS伪节
- 包含不需要重定位的符号
UNDEF伪节
- 包含未定义符号
- 这些符号在当前模块中被引用,但在其他地方定义
COMMON伪节
- 包含未初始化的数据目标
- value字段表示对齐要求
- size字段表示最小大小
- 与.bss的区别:
- COMMOM:未初始化的全局变量
- .bss:未初始化的静态变量,初始化为0的全局变量和静态变量
示例:
1 | |
重要说明
- 这些伪节只存在于可重定位目标文件中
- 可执行目标文件中不包含这些伪节
符号表的示例

符号解析
链接器解析符号引用的方法是将每个引用与它输入的可重定位目标文件的符号表中的一个确定的符号定义关联起来。
链接器解析多重定义的全局符号
强符号
定义:在符号表中具有唯一定义的符号,通常由函数或全局变量生成。
- 已初始化的全局变量
- 函数定义
- 使用
extern声明的变量
弱符号
定义:在符号表中可以有多个定义的符号,允许被覆盖。
- 未初始化的全局变量
- 使用
__attribute__((weak))声明的符号 - C++ 中的
inline函数
根据强弱信号的定义,Linux链接器使用下面的规则来处理多重定义的符号名:
- 规则1:不允许有多个同名的强符号
- 规则2:如果有一个强符号和多个弱符号同名,那么选择强符号
- 规则3:如果有多个弱符号同名,那么从这些弱符号中任意选择一个
与静态库链接
编译系统提供一种机制,将所有相关的目标模块打包为一个单独的文件,称为静态库(static library)。
静态库的特点:
- 编译时链接 :静态库在编译阶段被链接到最终的可执行文件中,程序执行时不再需要外部的库文件。
- 独立性 :因为所有的库代码已经包含在可执行文件中,所以程序运行时不需要依赖于外部的库文件。
- 增加可执行文件的体积 :由于所有库代码都被直接嵌入到可执行文件中,因此会增加可执行文件的体积。
- 不易更新 :一旦程序已经编译为可执行文件,修改静态库的内容需要重新编译程序。
静态库的实现
在linux系统中,静态库以一种称为存档(archive)的特殊文件格式存放在磁盘中。存档文件是一组链接起来的可重定位目标文件(.o文件)的集合,有一个头部用来描述每个成员目标文件的大小和位置。存档文件由后缀(.a)标识。
相关函数可以被编译为独立的目标模块,然后封装为一个单独的静态库文件,然后应用程序可以通过在命令行上指定单独的文件名字来使用这些在库中定义的函数。在链接时,链接器将只复制被程序引用的目标模块。这就减少了可执行文件在磁盘和内存中的大小。
链接器如何使用静态库来解析引用
1. 从左到右扫描文件
链接器按照它们在命令行输入的顺序从左到右的顺序来扫描可重定位目标文件、存档文件。并且在扫描的过程中同时维护三个集合:
- EC集合:表示需要被合并到最终可执行文件中的目标文件集合
- U集合:未解析的符号集合,存储那些被引用单尚未找到定义的符号
- D集合:已定义的符号集合,存储那些已经找到定义的集合
解析的目标是:最终U为空集,所有的引用符号在D集合中都有定义。
初始状态:EC、U、D均为空集。
2. 文件内部扫描
对于扫描的每一个输入文件$f$,链接器会判断$f$是一个目标文件还是一个存档文件。
- 如果是目标文件:链接器把文件$f$添加到集合E,修改U和D来反应$f$中的符号定义和引用,并继续下一个文件。
- 如果是存档文件:
- 链接器逐个检查存档文件中的成员(目标文件),以尝试解析U中的未解析的符号。
- 如果某个成员目标文件m,定义了一个符号,可以解析U中的某个符号的引用
- 将m添加到E中
- 更新U集合:从U中移除已解析的符号
- 更新D集合:将新定义的符号加入D
- 继续扫描,直到扫描完整个存档文件
- 丢弃所有未被加入E的成员,处理下一个文件
3. 完成扫描后
扫描完所有的文件后,U是非空的,那么链接器就会输出一个错误并终止。
否则,合并和重定位E中的目标文件,构建输出的可执行文件,
最后的注意事项
由于链接器按照命令行中目标文件和库文件的 从左到右顺序 依次处理它们,并且只扫描每个文件一次。所以会遇到顺序错误导致的链接失败的问题。
原因如下:如果命令行中 定义符号的库文件出现在引用这些符号的目标文件之前 ,当链接器扫描到这个库文件时,它不会发现任何未解析的符号需要解决(因为目标文件还没被处理)。
- 结果 :链接器会忽略该库文件的内容。
- 随后 :当链接器处理到目标文件并发现未解析符号时,因为之前的库文件已经被扫描过,未定义的符号无法被解析,最终导致链接失败。
解决办法:
为了避免这种链接错误,程序员需要确保 引用符号的目标文件出现在定义符号的库文件之前 。一般的准则是将所有的库文件放在命令行的结尾。
重定位
在计算机系统中, 重定位 (Relocation)是将程序从编译时生成的虚拟地址调整为最终加载到内存中的实际地址的过程,以确保程序可以正确运行。
重定位的两个阶段
重定位节和符号定义
链接时重定位
- 发生时机 :在链接器将多个目标文件和库文件合并成一个可执行文件时。
- 目的 :
- 将所有目标文件的符号引用解析为具体的地址。
- 为目标文件分配全局地址空间(代码段、数据段等)。
- 链接器的任务 :
- 修改程序中所有需要调整的地址,使得它们在可执行文件中是正确的。
- 结果 :生成了一个可执行文件,通常以绝对地址为准。
重定位节中的符号引用
加载时重定位
- 发生时机 :在操作系统将可执行文件加载到内存中时。
- 目的 :
- 将程序中的绝对地址调整为其在内存中的实际加载地址。
- 这通常发生在操作系统加载动态库或执行程序时。
- 加载器的任务 :
- 根据加载基地址(Base Address),调整程序中的所有绝对地址。
- 修改指令中的地址引用(如跳转指令和全局变量引用)。
- 结果 :程序在内存中可以正确执行。
重定位条目
当汇编器遇到不知道数据和代码最终会放到内存中的什么位置,它也不知到这个模块引用的任何外部定义的函数或者全局变量的位置,它会生成一个重定位条目。
重定位条目是目标文件中的一部分数据结构,用于帮助链接器或加载器完成重定位过程。它记录了目标文件中需要修改地址的指令或数据的位置,以及修改地址所需的信息。代码的重定位条目放在 .rel.text 中,已初始化数据的重定位条目放在 .rel.data 中。
重定位条目的格式

一个重定位条目通常包括以下字段:
位置(Offset) :
- 需要修改的地址在目标文件中的偏移位置。
- 例如,一条指令的地址引用,或者全局变量的存储位置。
符号(Symbol) :
- 对应的符号名称,用于链接器查找定义该符号的具体位置。
- 例如,函数名或全局变量名。
重定位类型(Type) :
- 指明该地址如何进行调整,例如:
- 绝对地址(直接修改为实际地址)。
- 相对地址(基于当前程序计数器的偏移量)。
- 指明该地址如何进行调整,例如:
附加信息(Addend) (某些格式可能有):
- 有时重定位条目会包含一个附加的常量,用于参与最终地址的计算。
常见的重定位类型
- R_X86_64_PC32:重定位一个使用32位PC相对地址的引用,基于当前程序计数器(PC)计算地址的偏移量。
- R_X86_64_32:重定位一个使用32位绝对地址的引用。
重定位符号引用
重定位符号引用是重定位过程中解决目标文件中符号未解析问题的核心。它指的是将目标文件中的符号引用(如变量名或函数名)替换为符号的实际地址或偏移值,以确保程序在运行时能正确访问这些符号。
1.重定位 PC相对引用
公式:
1 | |
例题:

对于汇编器产生的一个如上的相对引用条目。
并且我们知道sum函数的重定位条目如下:
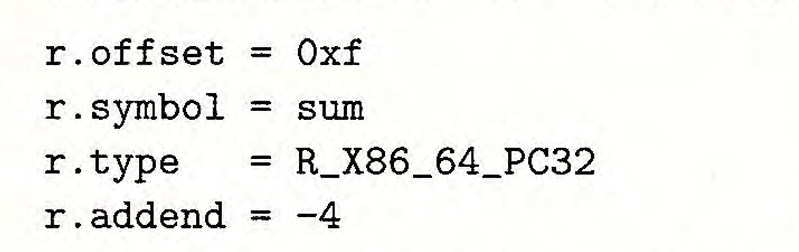
- 重定位引用地址相对程序头(.text)偏移量为
0xf - 名字为sum
- 引用方式为相对地址引用
- 附加量为-4
并且链接器已经确定:

- 程序头(.text)地址为:
0x4004d0 - sum函数实际地址为:
0x4004e8
我们得到:
1 | |
然和可以得到:
1 | |
sum 的绝对地址为:0x4004e8
cpu 计算为:$PC + 偏移量 = 0x4004e3 + 0x5 = 0x4004e8$
则callq指令对于sum的重定位引用为:05
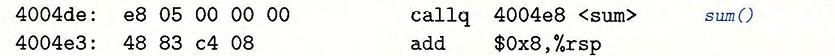
当cpu处理完call指令时,PC为下一条待执行指令的地址:0x4004e3
为了执行call指令,会进行以下两个步骤:
- 将PC压入栈
- PC = PC+
0x5
此时PC = 0x4004e8 即为sum函数的地址。
2. 重定位绝对引用
公式
1 | |
示例:
array的重定位条目如下组成:

- 相对文件头偏移量为:
0xa - 名字为
array - 类型为绝对地址引用
- 附加量为0
假设链接器为:
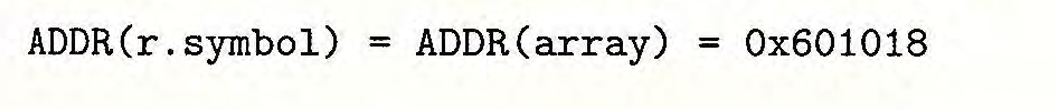
则可直接得到:
1 | |
则该引用为下面这种形势:601018 (小端存储)

可执行目标文件
上一节中我们学习链接器是如何将可重定位文件链接从而形成一个可执行目标文件,这个二进制文件包含加载程序到内存并运行它所需要的所有信息,一个典型的ELF可执行文件格式如下:
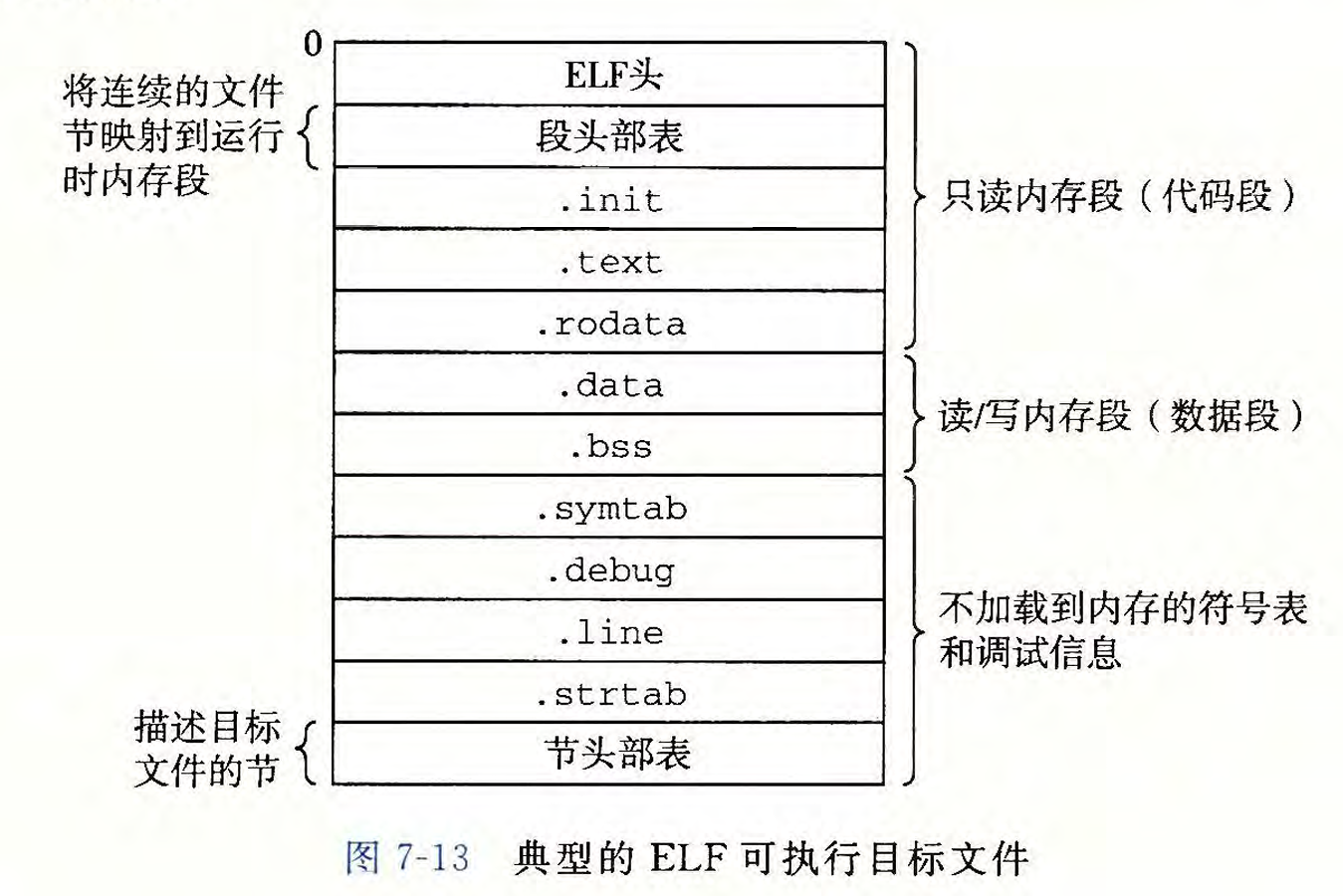
可执行程序目标程序的格式类似于可重定位文件的格式,但是有以下几点不同:
- ELF头描述文件的总体格式,它还包括程序的入口点(entry point),也就是程序要运行时执行的第一条指令的地址。
- .text .data .rodata,已经被定位到他们最终运行时的地址
- .init 定义了一个小函数,叫做
_init()程序的初始化代码会调用它。 - 因为可执行文件已经是被完全链接的,所以不再需要rel节
段头部表,也叫程序头部表(Program Header Table),用于描述如何将可执行文件的连续的片映射到连续内存段中的映射关系,一个可能的程序头部表如下:

- off:目标文件中的偏移
- vaddr/paddr:内存地址
- align:对齐要求
- filesz:目标文件中的段大小
- memsz:内存中的段大小
- flags:运行时访问权限
从该程序首部表,我们可以清晰的看到根据可执行目标文件的内容初始化了两个内存段。
第一段:代码段
- 第一行描述的段(Read-only code segment) :
- 类型 :代码段(
r-x表示只读和可执行)。 - 文件偏移 (off):
0x0,表示这个段从文件的开头开始。 - 虚拟地址 (vaddr):
0x400000,该段加载到内存后,起始地址是0x400000。 - 物理地址 (paddr):
0x400000,对于大部分系统,这个地址和虚拟地址通常一致。 - 对齐方式 (align):
2**21,表示该段在内存中按 2 的 21 次方(2MB)对齐。 - 文件大小 (filesz):
0x69c(1692 字节),表示代码段在 ELF 文件中的大小。 - 内存大小 (memsz):
0x69c(1692 字节),表示代码段在内存中的大小。 - 标志 (flags):
r-x,只读且可执行。
flags r-x 表示第一个代码段具有读和执行的访问权限,开始于内存 (vaddr 0x0000000000400000) 0x400000处,总共的内存大小为(memsz 0x69c)0x69c个字节,并且将目标文件的前(filesz 0x69c)0x69c个字节的内容导入内存进行初始化,其中包括 :
- ELF头
- 程序头部表
- .init
- .text
- .rodate
第二段:数据段
- 第二行描述的段(Read/write data segment) :
- 类型 :数据段(
rw-表示可读和可写,但不可执行)。 - 文件偏移 (off):
0xdf8,表示该段在文件中从偏移0xdf8开始。 - 虚拟地址 (vaddr):
0x600df8,该段加载到内存后,起始地址是0x600df8。 - 物理地址 (paddr):
0x600df8,通常与虚拟地址相同。 - 对齐方式 (align):
2**21,即 2MB 对齐。 - 文件大小 (filesz):
0x228(552 字节),表示数据段在 ELF 文件中的大小。 - 内存大小 (memsz):
0x230(560 字节),表示该段在内存中的大小。 - 标志 (flags):
rw-,可读、可写,不可执行。
flags rw- 表示有读写权限,开始于内存0x600df8处,总内存大小为:0x230,并且将目标文件的偏移量0xdf8处开始的228个字节的内容导入内存进行初始化。
不难发现,内存段二中内存空间还剩下8个字节,这些多余的空间对应于运行时将被初始化为0的 .bss数据。
段对齐计算
对齐是为了优化内存访问效率。对齐方式由 align 指定。这里为 2**21,即 2MB 对齐。
对齐公式
$$
\text{vaddr mod align = off mod align}
$$
以上面例子中的第二段来说:
1 | |
动态链接共享库
静态链接库的缺点:
- 主存浪费
- 磁盘浪费
- 更新困难
共享库(共享目标):
- 存储可被多个程序动态加载和使用的函数或数据的文件。
- 在Linux系统中常用.so后缀来表示,windows中大量的使用了共享库,称为DLL(动态链接库)。
动态链接(dynamic linking):
- 在程序运行时,将可执行文件与共享库结合的机制,而不是在编译或链接阶段直接将库嵌入到可执行代码中。
- 由动态链接器(dynamic linker)的程序来执行的
共享的过程
对于一个给定的文件系统中,对于一个库只有一个.so文件,所有引用该库的可执行目标文件共享这个.so文件中的代码和数据。区别于静态链接中的在所有可执行目标文件中复制一份备份嵌入其中。并且对于一个共享库的.text节的一个副本可以被不同的正在运行的进程共享。
其大致流程如下:
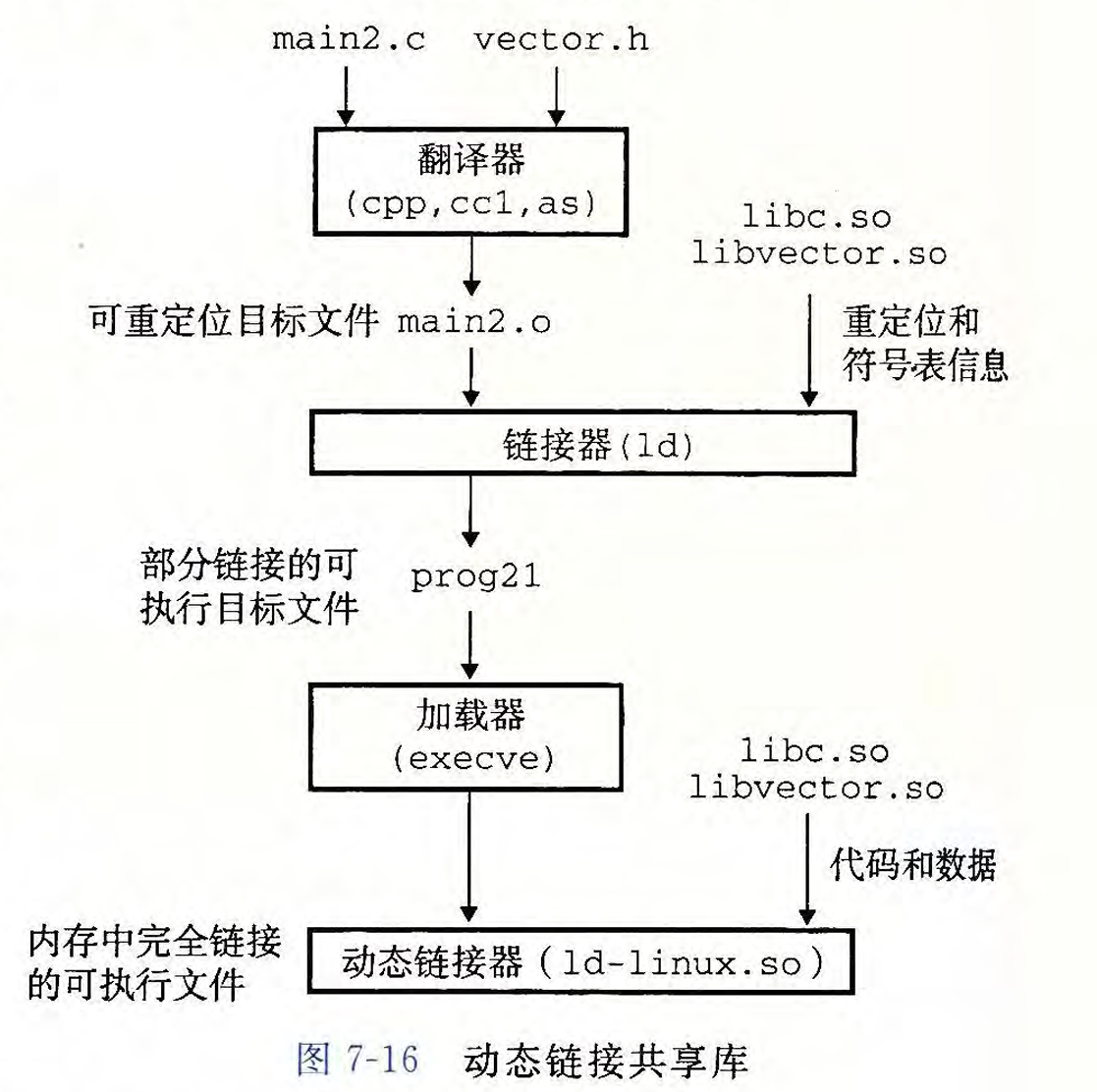
在链接器生成可执行目标文件 prog21时,会在prog21的程序头表中生成 .interp段,其包含了动态链接器路径名。
当加载器注意到程序头表中有.interp 段时,会先加载和运行动态链接器(动态链接器本身也是共享目标),由动态链接器完成重定位链接工作:
- 重定位libc.so的文本和数据到某个内存段
- 重定位libvector.so的文本和数据到另一个内存段
- 重定位prog21中所有对由 libc.so和 libvector.so定义的符号的引用
最后动态链接器将控制传递给应用程序,从此时起,共享库的位置就固定了,在程序运行过程中都不会改变。
从应用程序中加载和链接共享库
Linux提供一些个简单的接口允许程序在运行时加载和链接共享库:
dlopen()
dlopen 函数是用于在运行时动态加载共享库(动态库)的函数。它是POSIX标准的一部分,通常在Linux和Unix系统上使用。dlopen 函数允许程序在运行时加载共享库,并使用库中的符号(函数和变量)。
1 | |
参数
filename:要加载的共享库的路径。如果传递NULL,则返回全局符号表的句柄。flag:控制库的加载行为。常用的标志包括:RTLD_LAZY:延迟解析符号,直到实际使用时才解析。RTLD_NOW:立即解析所有未定义的符号。如果解析失败,则dlopen返回NULL。RTLD_GLOBAL:使库中的符号在后续的dlopen调用中可见。RTLD_LOCAL:使库中的符号在后续的dlopen调用中不可见(默认行为)。
返回值
- 成功时返回一个指向共享库的句柄。
- 失败时返回
NULL,可以使用dlerror函数获取错误信息。
dlsym()
dlsym 函数用于在运行时从动态加载的共享库中获取符号(函数或变量)的地址。它与 dlopen 函数一起使用,用于动态加载和使用共享库中的符号。
1 | |
参数
handle:由dlopen返回的句柄,表示已加载的共享库。symbol:要获取的符号名称(函数或变量的名称)。
返回值
- 成功时返回符号的地址。
- 失败时返回
NULL,可以使用dlerror函数获取错误信息。
dlclose()
dlclose 函数用于关闭由 dlopen 打开的动态库,并释放相关资源。
1 | |
参数
handle:由dlopen返回的句柄,表示已加载的共享库。
返回值
- 成功时返回 0。
- 失败时返回非零值,可以使用
dlerror函数获取错误信息。
dlerror
dlerror 函数用于获取最近一次动态链接库操作(如 dlopen、dlsym、dlclose)的错误信息。它返回一个描述错误的字符串,并清除之前的错误状态。
1 | |
返回值
- 成功时返回
NULL,表示没有错误。 - 失败时返回一个指向错误描述字符串的指针。
使用示例
1 | |
位置无关代码(PIC)
位置无关代码(Position-Independent Code, PIC) 是一种编程技术,使得编译生成的代码能够在内存中的任意地址运行,而不依赖其特定的加载地址。这种技术广泛应用于共享库(Shared Libraries)和现代操作系统中的程序加载机制。
定义
- 位置无关代码是指一种不依赖固定加载地址的代码,可以被加载到内存中的任意位置并正常运行。
- PIC 的关键特性是:
- 在生成的可执行文件中,所有的代码指令都使用相对地址(而非绝对地址)来访问数据或调用函数。
- 加载地址(Load Address)无需预先确定,且不会影响代码的执行。
总结:
- 保证共享库代码的位置可以是不确定的
- 即使共享库代码的长度发生变化,也不会影响调用它的程序