计算机系统基础第十章系统级I/O
每日一言
[thinking] I only take family as patients and I still get worked to death. – Sohma Hatori
from Fruits Basket
Unix I/O
一个Linux文件就是一个m个字节的序列:
$$
B_0, B_1, \ldots ,B_k, \ldots, B_{m-1}
$$
Linux系统将所有的I/O设备(网络、磁盘、终端)都被模型化为文件,所有的输入和输出都被当作对应文件的读和写来进行。这样Linux只需引出一个简单、低级的应用接口,称为Unix I/O,使得所有的输入和输出都能以一种统一且一致的方式来执行。
打开文件
一个应用程序通过要求内核打开相应的文件,来宣告它想要访间一个I/O 设备。内核返回一个小的非负整数,叫做描述符,它在后续对此文件的所有操作中标识这个文件。内核记录有关这个打开文件的所有信息应用程序只需记住这个描述符。
Linux shell
Linux shell 创建的每个进程开始时都有三个打开的文件:标准输入(描述符为 0)、标准输出(描述符为 1)和标准错误(描述符为 2)。头文件< unistd.h> 定义了常量 STDIN_ FILENO、 STDOUT_FILENO 和 STDERR_FILENO, 它们可用来代替显式的描述符值。
改变当前的文件位置。
对于每个打开的文件,内核保持着一个文件位置 k, 初始为0 。这个文件位置是从文件开头起始的字节偏移量。应用程序能够通过执行 seek操作,显式地设置文件的当前位置为k。
读写文件
一个读操作就是从文件复制 n(n>0) 个字节到内存,从当前文件位置k 开始,然后将K增加到$k+n$。给定一个大小为m字节的文件,当 $k >= m$ 时执行读操作会触发一个称为 end-of-file(EOF) 的条件,应用程序能检测到这个条件。尽管在文件结尾处并没有明确的 “EOF符号”。
关闭文件
当应用完成了对文件的访问之后,它就通知内核关闭这个文件。作为响应,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池中。无论一个进程因为何种原因终止时,内核都会关闭所有打开的文件并释放它们的内存资源。
文件
每个linux文件都有一个类型(type)来表明它在系统中的角色:
普通文件
普通文件(regular file)包含任意数据。应用程序常常要区分文本文件(text file)和二进制文件(binary file) , 文本文件是只含有 ASCII 或 Unicode 字符的普通文件;二进制文件是所有其他的文件。对内核而言,文本文件和二进制文件没有区别。
Linux 文本文件包含了一个文本行(text line)序列,其中每一行都是一个字符序列,以一个新行符(“\ n”)结束。新行符与 ASCII 的换行符(LF)是一样的,其数字值为 0x0a。
目录(文件夹)
目录(如ectory) 是包含一组链接Clink) 的文件,其中每个链接都将一个文件名(filename) 映射到一个文件,这个文件可能是另一个目录。每个目录至少含有两个条目:“.”是到该目录自身的链接,以及”.. “是到目录层次结构(见下文)中父目录(parent directory) 的链接。你可以用 mkdir 命令创建一个目录用 ls 查看其内容,用 rmdir 删除该目录。
在linux 中,可以通过 cd 目录名 打开一个目录,然后你可以通过 cd .. 命令返回到它的上级目录。
套接字
套接宇(socket)是用来与另一个进程进行跨网络通信的文件
除了上面三种常见的文件类型外,还有命名通道、符号链接、字符和块设备等。
linux系统目录层次结构: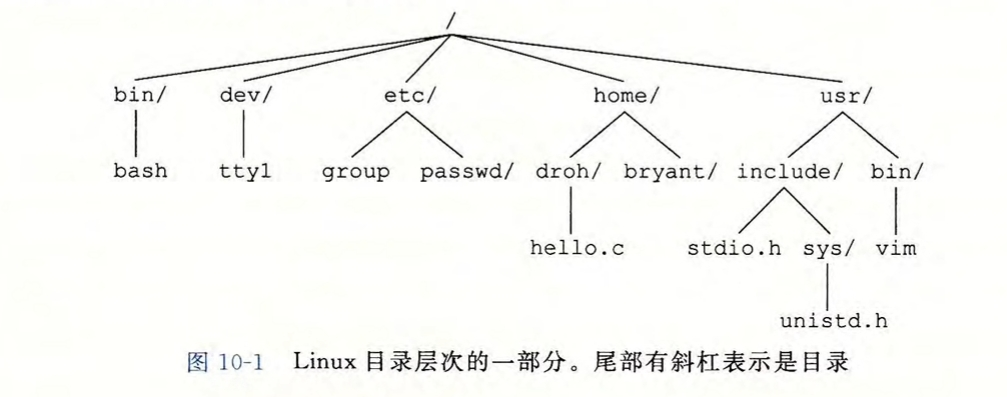
每个进程都有一个当前工作目录(current working directory)简称cwd,来确定其在目录层次结构中的当前位置。
注释:在linux 中,你可以通过命令 pwd 来打印当前的工作目录。
在目录层次结构中的位置,通过路径名来指定。路径名有两种形式:
绝对路径名(absolute pathname)
以一个斜杠开始,表示从根节点开始的路径。如:/home/droh/hello.c
相对路径名(relative pathname)
相对路径名是相对于当前工作目录的路径。它不以根目录(如 Windows 的 C:\ 或 Unix 的 /)开头,而是基于当前目录的位置来指定文件或目录的位置。
以下是一些相对路径名的示例:
- 当前目录 :
.表示当前目录。./file.txt表示当前目录下的file.txt文件。
- 上一级目录 :
..表示上一级目录。../file.txt表示上一级目录下的file.txt文件。
- 子目录 :
subdir/file.txt表示当前目录下的subdir目录中的file.txt文件。
- 上一级目录的子目录 :
../subdir/file.txt表示上一级目录下的subdir目录中的file.txt文件。
我们不难发现,不论是相对路径还是绝对路径,如果你想要表示的是一个文件,都不能直接以文件的名字开始,哪怕是当前目录,也需要以 ./name 来确定一个文件。
打开和关闭文件
进程通过调用open函数来打开或者创建一个文件:
1 | |
open函数将filename转换为一个文件描述符,并且返回描述符数字。返回的描述符总是在进程中当前没有打开的最小描述符。flags参数指明了进程打算如何访问这个文件:
- O_RDONLY 只读
- O_WRONLY 只写
- O_RDWR 可读可写
falgs 参数也可以是一个或者更多位参数的或,为写提供一些额外的指示:
- O_CREAT 如果文件不存在择创建一个空文件
- O_TRUNC 如果文件已经存在就截断它(将它清空)
- O_APPEND 每次写操作前,设置文件位置到文件的结尾处
例:
1 | |
mode参数指定了新文件的访问权限位。
同时,每个进程都有一个umask,他是通过调用umake函数来设置的。当进程通过带某个mode参数的open函数来创建一个文件时,文件的访问权限被设置为:mode & ~umask,即这个文件有所有mode指定的权限,而没有所有umake所指定的权限。
所有的权限在sys/stat.h中定义:
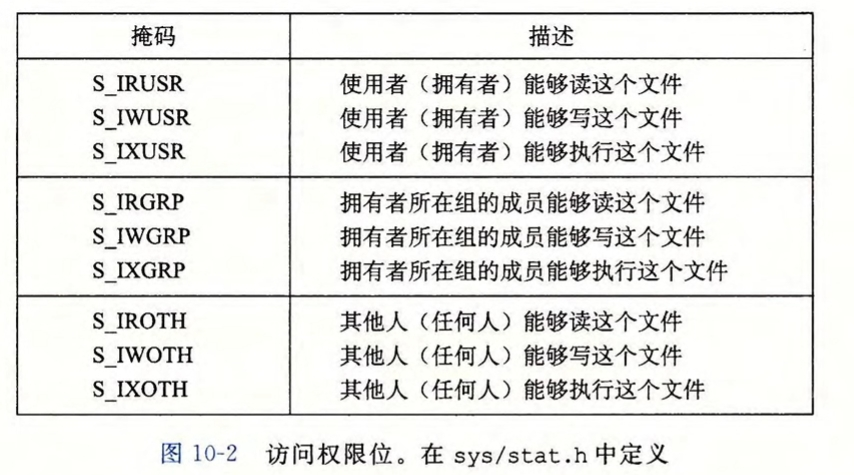
示例:对于如下给定的mode和umask

则通过如下代码创建的文件:

表示的权限设置为:文件的拥有者有读写权限,而其他所有用户都只具有读的权限。
最后,通过进程调用:

来关闭程序。
读和写文件
应用程序通过read和write函数来执行输入和输出。

read 函数从描述符为 fd 的当前文件位置复制最多 n个字节到内存位置buf。如果已经读到文件结尾则返回0,表示EOF,否则返回实际传送的字节数量。
write 函数从内存位置 buf 复制至多 n 个字节到描述符 fd的当前文件位置。
类型ssize_t和size_t的区别:
- ssize_t:实际为long,有符号数,因为需要用到返回值-1表示状态。
- size_t:为unsigned long,无符号数,无需表示负数
当read和wirte函数传送的字节比程序要求的n要少的三种情况:
- 读时遇到EOF。当第一次读取到文件末尾时,不会返回EOF信号,仍然返回实际传送的字节数,但是当已经没有可以传送字节后,就会返回EOF信号。
- 从终端读文本行。如果打开文件是与终端相关联的(如键盘和显示器),那么每个read 函数将一次传送一个文本行,返回的不足值等于文本行的大小。
- 读和写网络套接宇(socket) 。暂不涉及原理,知道即可。
用RIO包健壮的读写
RIO提供两类不同的函数:
- 无缓冲的输入输出函数:这些函数直接在内存和文件之间传送数据,没有应用级缓冲。它们对将二进制数据读写到网络和从网络读写二进制数据尤其有用。
- 带缓冲的输出函数:这些函数允许你高效地从文件中读取文本行和二进制数据,这些文件的内容缓存在应用级缓冲区内,类似于为 printf 这样的标准 I/0 函数提供的缓冲区。
RIO 的无缓冲的输入输出函数
1 | |
他们的用法的功能于上一节的read和 write 函数一致。
RIO 的带缓冲的输入函数
读取文件元数据
应用程序能够通过调用 stat() 和 fstat() 函数,检索到关于文件的信息,也称为文件的元数据。

stat()以文件名的名字作为输入,而fstat()以文件的描述符作为输入。
这个函数会将文件的各种信息填写到如下图所示的一个stat结构体中。

这里我们简单介绍两个成员:st_mode和st_size:
st_size 成员包含了文件的字节数大小。si_mode成员则编码了文件访问许可位和文件类型。关于这两点请看上文。
读取目录内容
应用程序可以用 readdir() 系列函数来读取目录的内容
opendir()

opendir() 是一个在 C 语言中的标准库函数,用于打开一个目录流(流是对条目有序列表的抽象),以便读取目录中的条目。它定义在 <dirent.h> 头文件中。以下是 opendir() 函数的详细介绍:
1 | |
参数
name:要打开的目录的路径。
返回值
- 成功时,返回指向
DIR结构的指针,该结构表示打开的目录流。 - 失败时,返回
NULL,并设置errno以指示错误。
readdir()

readdir() 是一个在 C 语言中的标准库函数,用于读取目录流中的下一个条目。它定义在 <dirent.h> 头文件中。以下是 readdir() 函数的详细介绍:
1 | |
参数
dirp:指向由opendir()返回的DIR结构的指针,表示打开的目录流。
返回值
- 成功时,返回指向
dirent结构的指针,该结构表示目录中的下一个条目。 - 到达目录末尾或发生错误时,返回
NULL。如果返回NULL,需要检查errno以确定是否发生了错误。
每个目录项(dirent)都是一个结构体:
成员 d_name 是文件名, d_ino 是文件位置。
closedir()

closedir() 是一个在 C 语言中的标准库函数,用于关闭由 opendir() 打开的目录流。它定义在 <dirent.h> 头文件中。以下是 closedir() 函数的详细介绍:
1 | |
参数
dirp:指向由opendir()返回的DIR结构的指针,表示要关闭的目录流。
返回值
- 成功时,返回 0。
- 失败时,返回 -1,并设置
errno以指示错误。
共享文件
内核用三个相关的数据结构来表示打开的文件:
- 描述符表(descriptor table):每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。 每个打开的描述符表项指向文件表中的一个表项。
- 文件表(file table):打开文件的集合是由一张文件表来表示的,所有的进程共享这张表。每个文件表的表项组成(针对我们的目的)包括当前的文件位置、引用计数(reference count) (即当前指向该表项的描述符表项数),以及一个指向 v-node 表中对应表项的指针。关闭一个描述符会减少相应的文件表表项中的引用计数。内核不会删除这个文件表表项,直到它的引用计数为零。
- v-node 表(v-node table):同文件表一样,所有的进程共享这张 v-node 表。 每个表项包含 stat 结构中的大多数信息,包括 st_mode 和 st_size 成员。
不共享
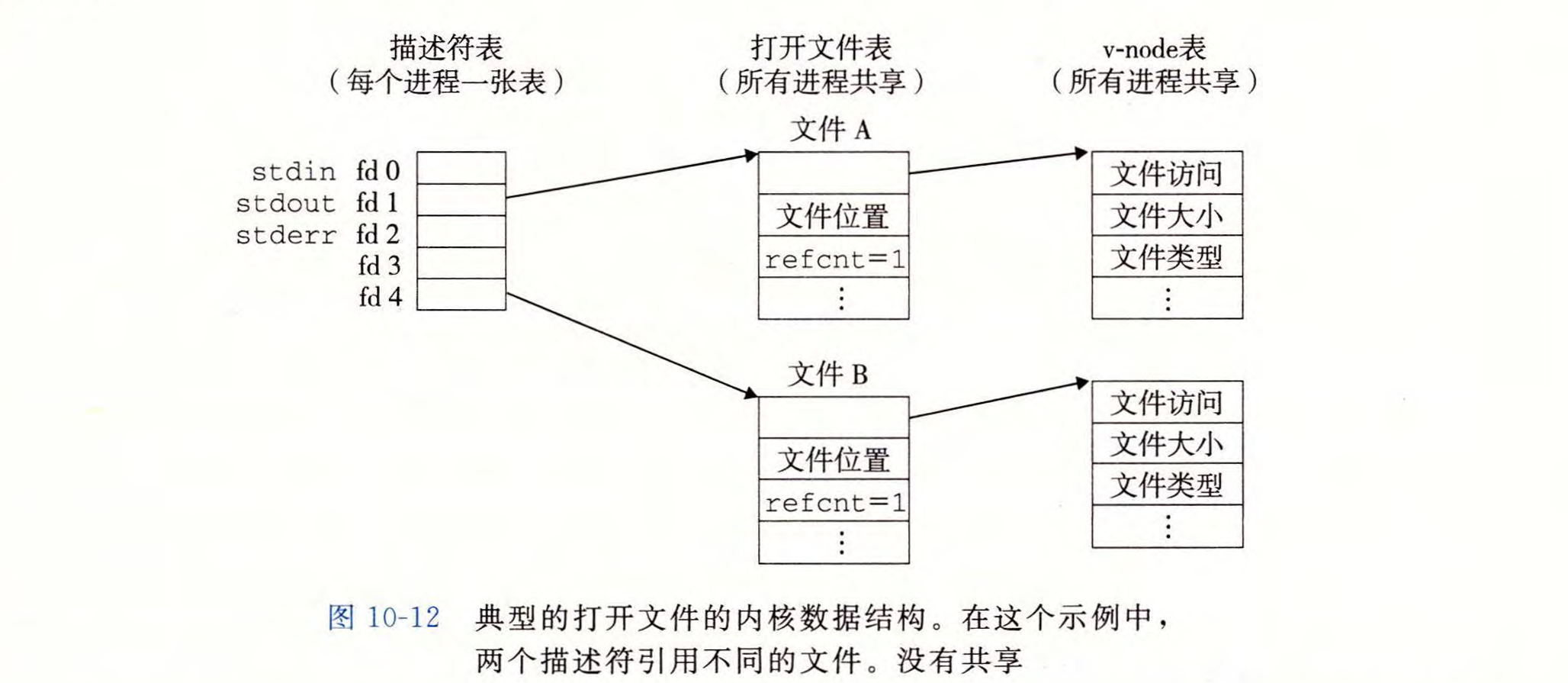
描述符1和描述符4通过不同的描述符来引用两个不同的文件,没有文件共享。所以每个描述符对应一个不同的文件。
两个进程共享
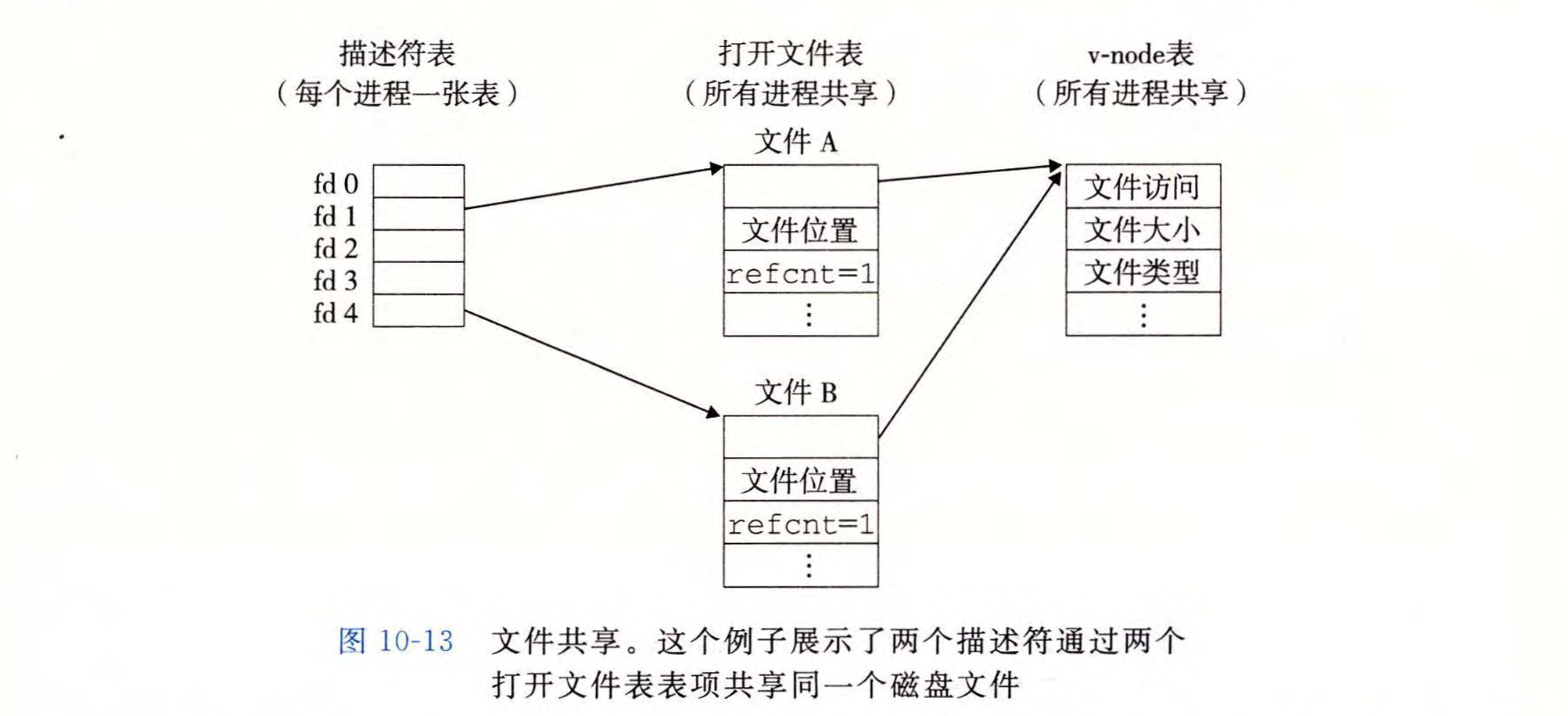
多个描述符可以通过不同的文件表表项来引用同一个文件。每个描述符都有自己的文件位置,所以不同的描述符的读操作可以从文件的不同位置获取信息。
父子进程文件共享
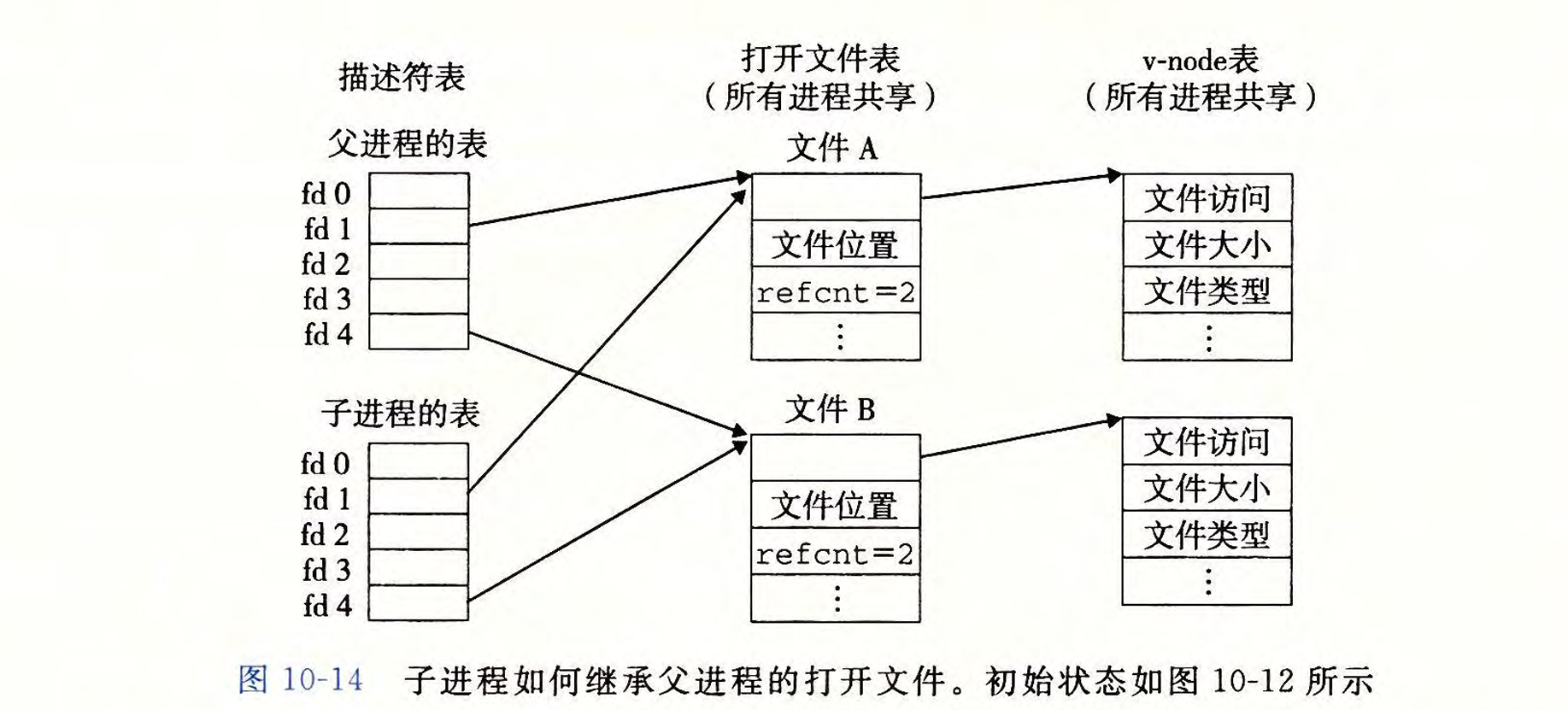
调用子进程时,子进程会copy一个父进程描述符的副本,父子进程共享相同的文件表集合,因此共享相同的文件位置。
很重要结果:在内核删除相应的文件表之前,父子进程必须都关闭了他们的描述符。
I/O 重定向
linux shell 提供了I/O重定向操作符,允许用户将磁盘文件和标准输入输出联系起来。如:
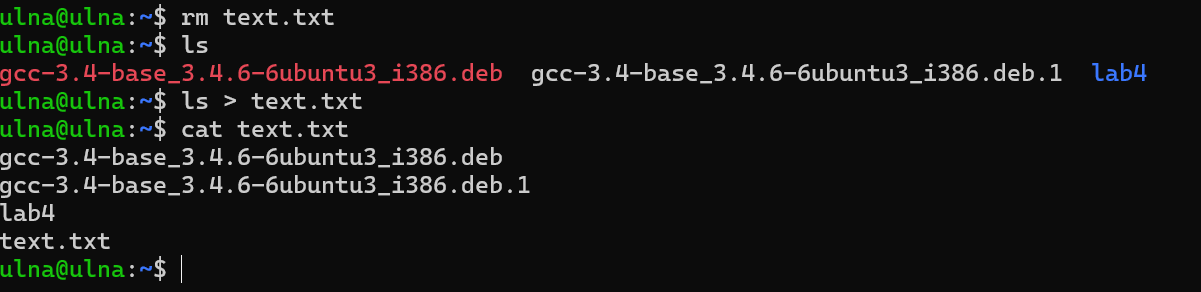
我们将 ls 命令的输出重新定向到文件 text.txt 。
dup2()

dup2() 是一个 POSIX 标准的系统调用函数,用于复制文件描述符。它的功能是将一个文件描述符复制到另一个文件描述符上。如果目标文件描述符已经打开,则会先将其关闭。dup2() 的函数原型如下:
1 | |
参数:
oldfd:要复制的文件描述符。newfd:目标文件描述符。
返回值:
- 成功时返回
newfd。 - 失败时返回
-1,并设置errno以指示错误。
示例:
假设:
- 描述符1指向标准输入输出
- 描述符4指向文件B输入输出。
执行:
1 | |
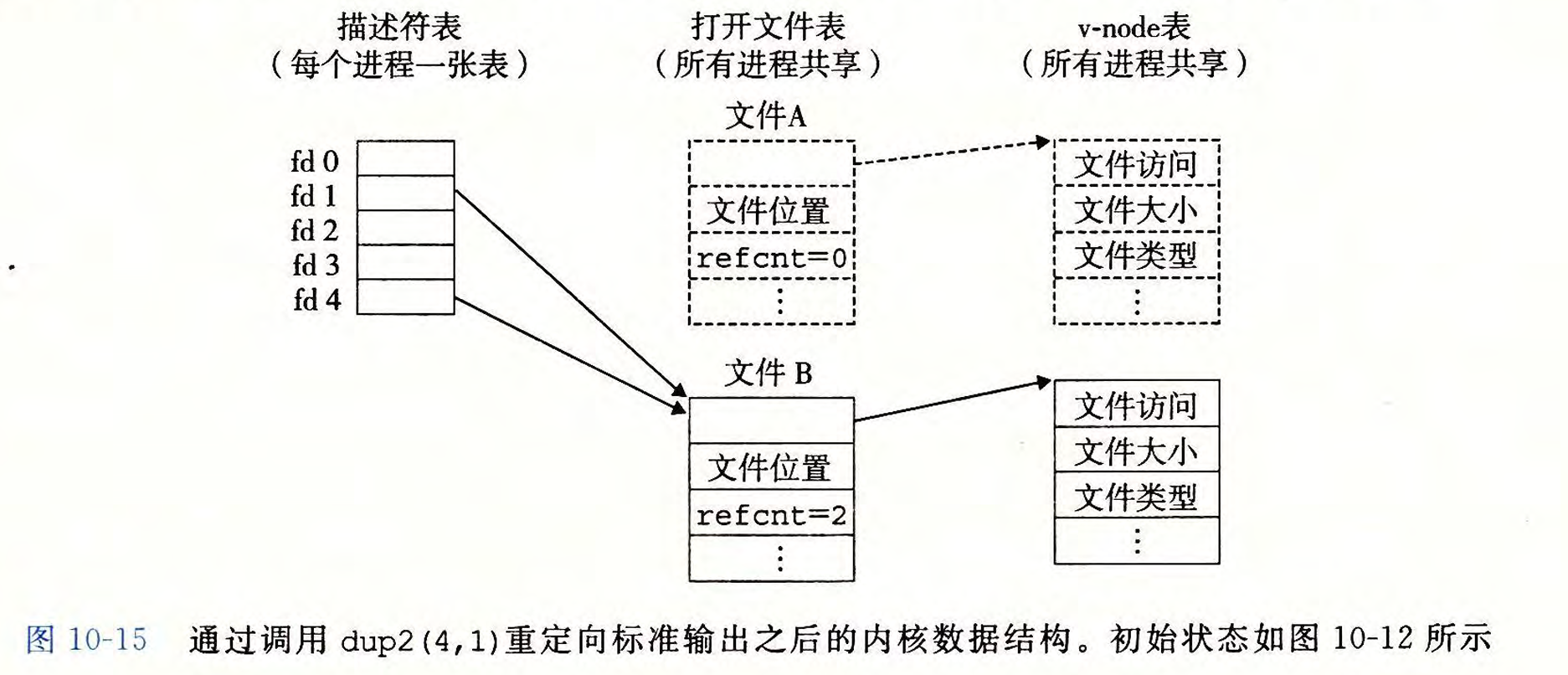
由于原先描述符1对应文件打开,则会先关闭描述符1的文件,并删除对应的文件表、v-node表;然后描述符4指向的文件表,v-node表等信息,覆盖原先描述符1的信息,即让描述符1也指向当前描述符4的文件表。
现在描述符1和4,都指向了文件B的输入输出。
标准I/O
标准I/O库将一个打开的文件模型化为一个流。对于程序员而言,一个流就是一个指向FILE 类型的结构指针。每个C程序开始时都会打开三个流,stdin、stdout、stderr,分别对应于标准输入,标准输出,标准错误:

类型为 FILE 的流是对文件描述符和流缓冲区的抽象。流缓冲区的目的和 RIO读缓冲区的一样:就是使开销较高的 Linux 1/0 系统调用的数量尽可能得小。只要缓冲区中还有未读的字节,接下来对 getc 的调用就能直接从流缓冲区得到服务。
I/O的选择
三原则:
- 尽可能用标准I/O。
- 不要用
scanf()或rio_readlineb()来读二进制文件。比如二进制中可能散步着很多0xa字节,这会导致读取到0xa(换行符)时他们就会停止读取,让程序出现莫名的错误。 - 对网络套接字的I/O使用RIO函数。
扩充
fork()函数
在Linux和Unix系统中,fork() 是用来创建子进程的系统调用。fork() 会复制当前进程的地址空间,生成一个几乎完全相同的子进程。
fork函数原型:
1 | |
fork函数的返回值为一个pid_t类型(整型,专门用来表示线程编号),有三种可能的情况:
- 在父进程中,
fork()函数返回子线程的pid值,其值为一个正整数 - 在子进程中,
fork()函数返回0,表示当前线程为子线程 - 若系统资源不足,创建线程失败,则
fork()返回-1
fork()函数创建子线程的特点:
- 父线程和子线程都是从
fork()语句返回的地方开始执行的 - 父线程和子线程通过
fork()的返回值来区分 - 父线程与子线程并行执行,先后可能随机
- 父线程与子线程在fork()后独立运行,它们的地址是分开的,修改一个变量的进程不会影响另一个进程
在I/O的关联:
- 子线程复制了与父线程相同的描述符表,因此子线程与父线程的文件描述符指向相同的文件表,即他们共享对于文件的读取位置。
正确结束一个子进程
exit()
在子进程中可以通过调用 exit()函数来结束自己。
kill()
父进程可以通过调用 kill()函数来结束子进程:
1 | |
return
在子进程中使用 return,也会直接结束子进程。
wait
父进程通过函数wait或waitpid,来等待子进程结束。
1 | |
getpid()函数
在 Linux 和类 Unix 系统中,getpid 是一个系统调用,用于获取当前进程的进程 ID (PID)。每个运行中的进程都有一个唯一的 PID,用于操作系统区分不同的进程。
1 | |
返回值:调用进程的PID。
子进程与父进程的PID不同,但是可以通过调用函数 getppid()来获取父进程的PID。