逻辑结构
- 集合:数据元素间除“同属于一个集合”外,无其它关系。如,一堆沙子
- 线性结构:一个对一个,如线性表、栈、队列;如,一根链条,一个单词中的所有字母
- 树形结构:一个对多个,如树;如,一棵树,家谱树等
- 图形结构:多个对多个,如图;如,交通图,高铁图
树和二叉树结构
概念合集
树的定义:元素至多有一个前驱元素,而可有多个后继元素。
结构定义:Tree是n(n>=0)个节点的有限集,空树(n == 0)
而对于非空树T,有以下性质:
- 有且仅有一个称之为根的结点;
- 除根结点以外的其余结点可分为m(m>0)个互不相交的有限集T1,T2,…,Tm,其中每一个集合本身又是一颗树,并且称为根的子树。
树有以下两个特点:
- 树的根节点没有前驱结点,除根节点以外的所有节点有且只有一个根结点。
- 树中的所有结点可以有0个或者多个后继节点
基本定义
- 结点的度 :拥有的子树数目
- 叶子(终端)结点:度为0的节点
- 分支(非终端)结点:度不为0的结点。
- 树的度:树的各结点度的最大值。
- 内部结点:除根结点之外的分支结点。
- 双亲与孩子(父与子)结点:结点的子树的根称为该结点的孩子;该结点称为孩子的双亲。
- 兄弟:属于同一双亲的孩子。
- 结点的祖先:从根到该结点所经分支上的所有结点。
- 结点的子孙:该结点为根的子树中的任一结点。
- 结点的层次:表示该结点在树中的相对位置。根为第一层,其它的结点依次下推;若某结点在第L层上,则其孩子在第L+1层上。
- 堂兄弟:双亲在同一层的结点互为堂兄弟。
- 树的深(高)度:树中结点的最大层次。
- 有序树:树中各结点的子树从左至右是有次序的,不能互换。否则,称为无序树。
- 路径长度:从树中某结点Ni出发,能够通过树中结点到达结点Nj,则称Ni到Nj存在一条路径,路径长度等于这两个结点之间的分支/边的个数。
- 森林:是m(m>=0)棵互不相交的树的集合。
二叉树
二叉树(Binary Tree)是n(n>=0)个结点所构成的集合,它或为空树(n=0),或为非空树,对于非空树T:
- 有且仅有一个称为根的结点
- 除根结点以外的其余结点分为两个互不相交的子集T1和T2,分别称为T的左子树和右子树,且T1和T2本身又都是二叉树。
特点:
- 定义是递归的
- 0<=结点的度<=2
- 是有序树,左右不能互换
平衡二叉树
平衡二叉树(Balanced Binary Tree)是一种特殊的二叉树,它保证了树的高度尽可能小,从而使得查找、插入和删除操作的时间复杂度保持在 O(log n) 的范围内。平衡二叉树的定义如下:
- 平衡因子 :每个节点的左子树和右子树的高度差不超过1。
- 高度平衡 :对于树中的每一个节点,其左子树和右子树的高度差的绝对值不超过1。
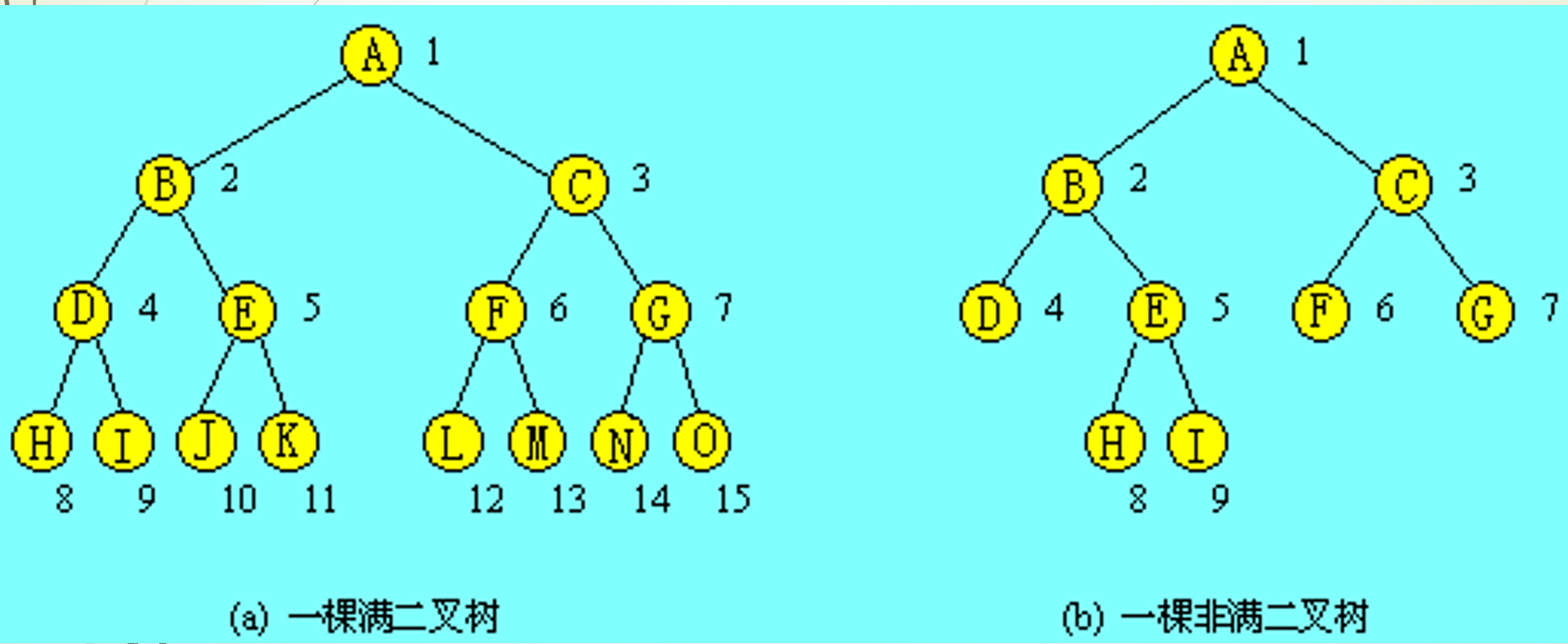
满二叉树
如果一棵二叉树每一层的结点个数都达到了最大,这棵二叉树称为满二叉树。对于满二叉树,所有的分支结点都存在左子树和右子树,所有叶子都在最下面一层。一颗深度为k的满二叉树有2^k-1个结点。
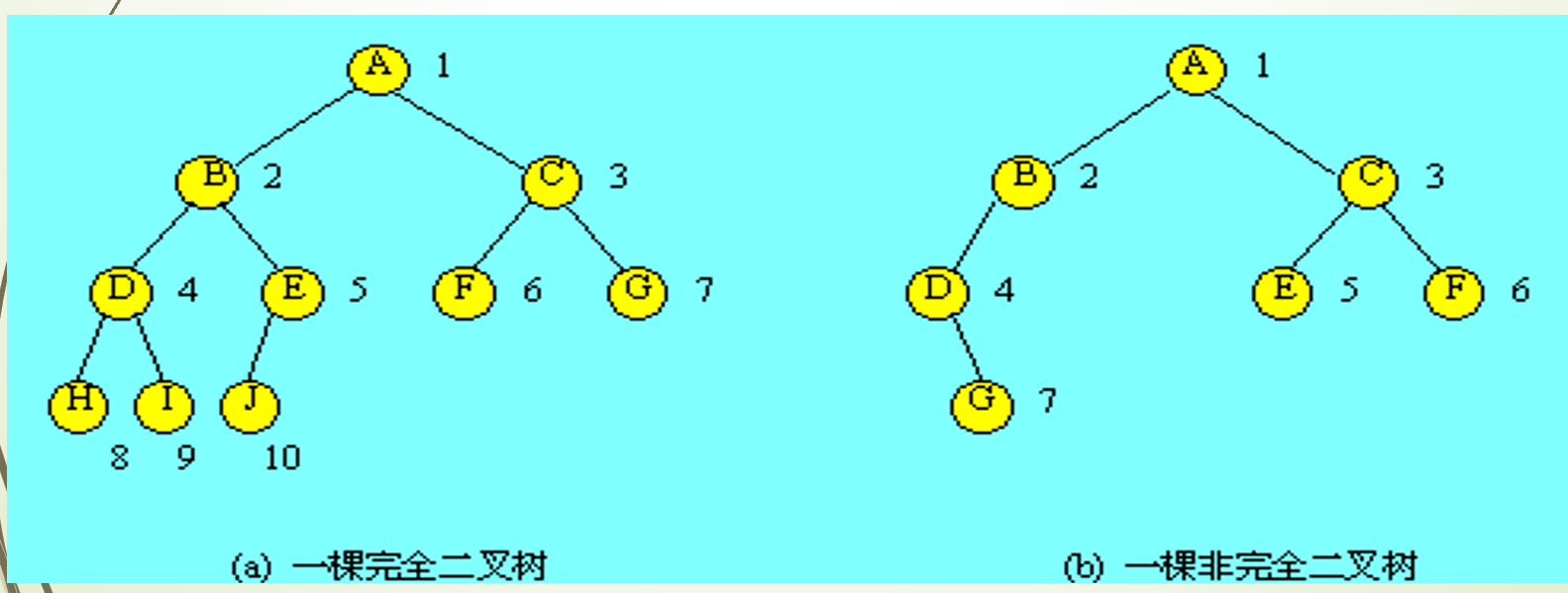
完全二叉树
完全二叉树是一种特殊的二叉树,其中每一层的节点都被完全填满,除了最后一层的节点可以不完全填满,但这些节点必须尽可能地靠左排列。都必须有2^n个节点,最后一层的节点从左到右依次排列,没有空缺。满二叉树肯定是完全二叉树,而完全二叉树未必是满二叉树。
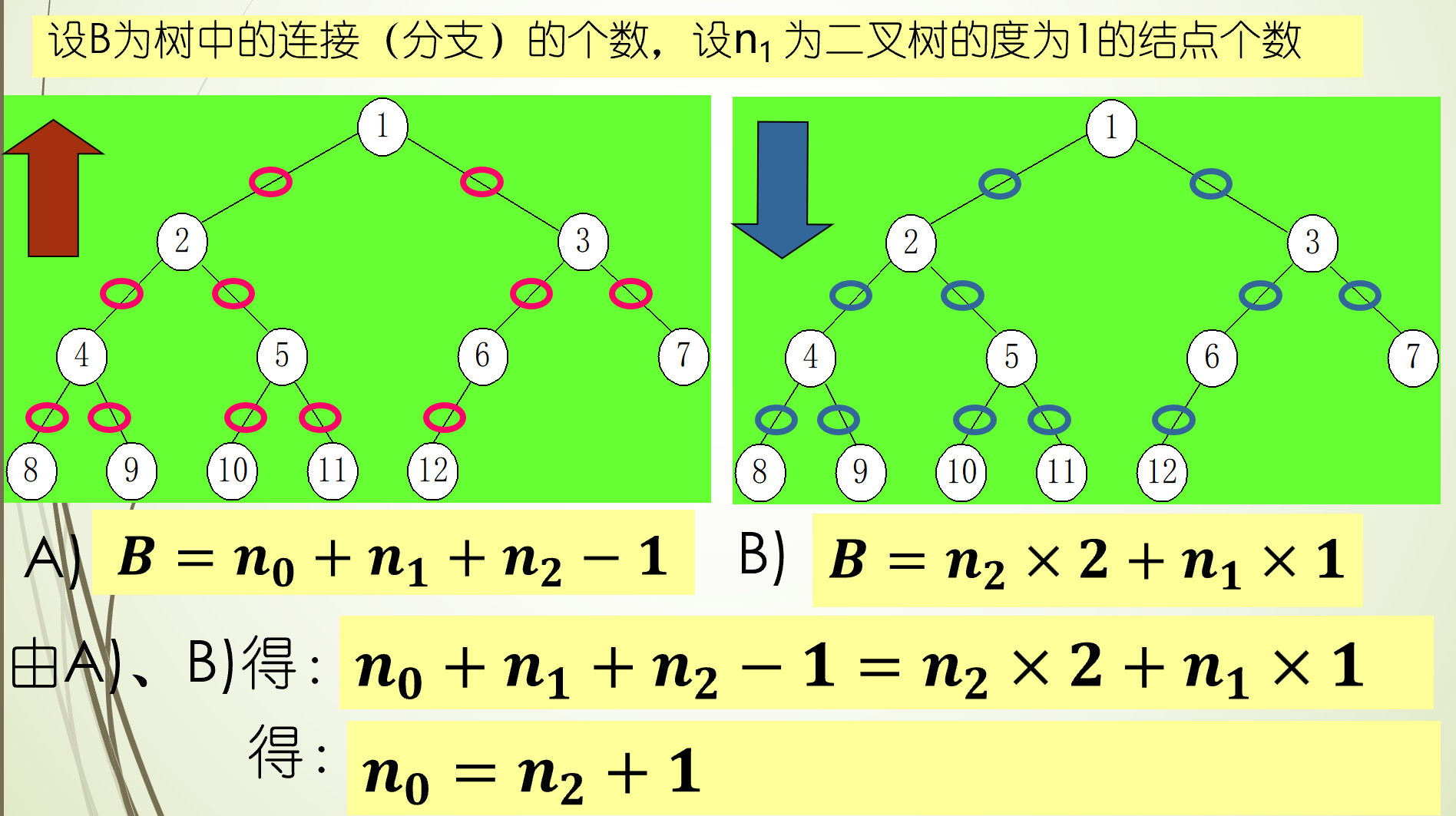
二叉树的性质
在二叉树的第i层上至多有2^(i-1)个结点
深度为k的二叉树至多有2^k-1个结点
对于任何一棵二叉树,若2度的结点数有n2个,则叶子数n0必定为n2+1
具有n个结点的完全二叉树的深度为(log2 n)[向下取整]+1
对于一颗有n个结点的完全二叉树,对其结点按层从上至下(每层从左至右)进行1至n的编号,则对任一结点i(1<=i<=n)有:
- i>1,则 i 的父亲是i = i / 2,i== 1,则i是根,无双亲
- 若 2i <=n ,则 i 的左孩子是2i,否则 i 无孩子
- 若 2i +1 <=n,则 i 的右孩子是 2i+1,否则 i 无右孩子。
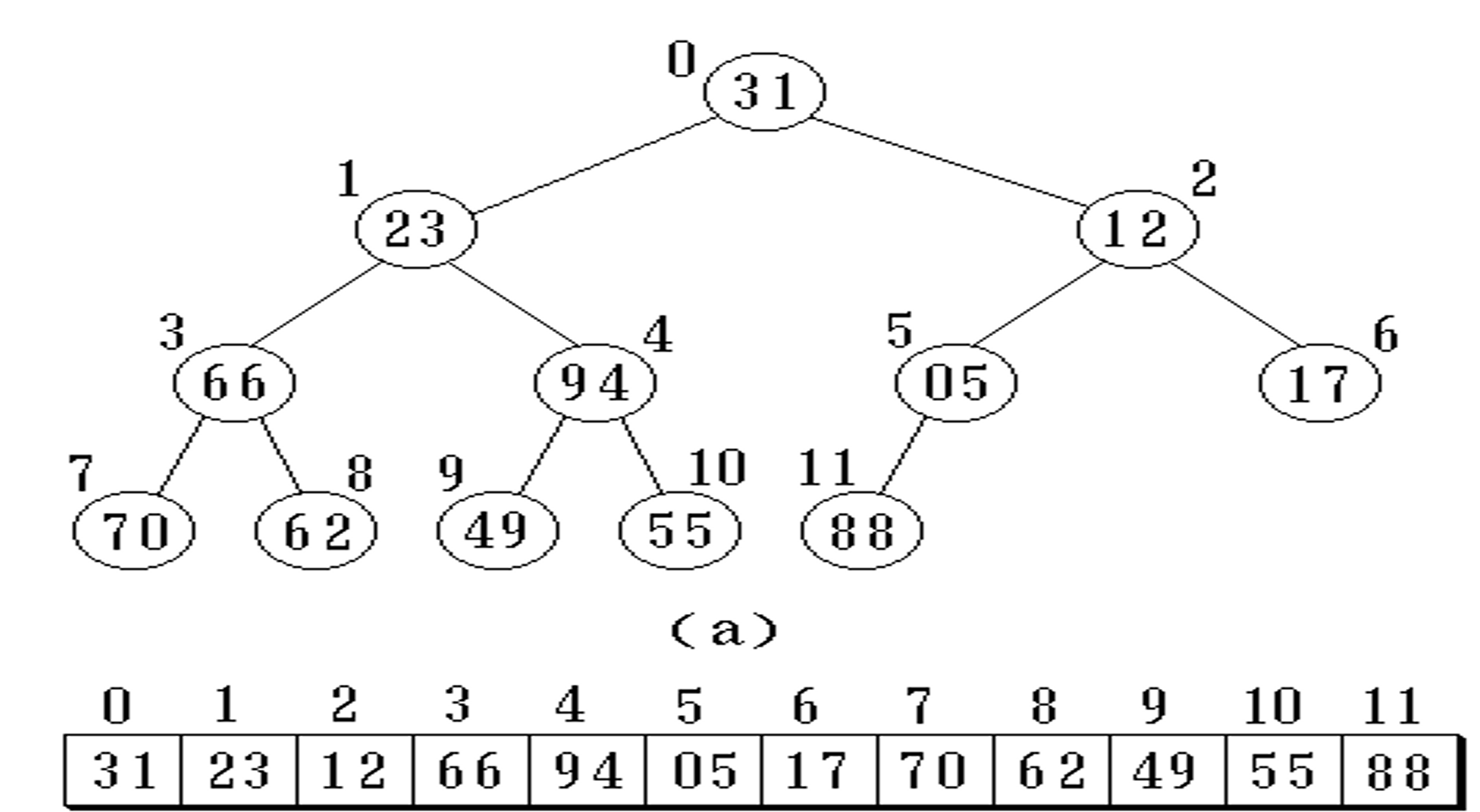
二叉树的顺序存储
对于二叉树的顺序存储,我们将一个一维数组抽象称为二叉树,数组的下标表示完全二叉树中的对应排序位置的编号。
代码定义:
1
2
| #define MAX_TREE_SIZE 100
typedef TElemType SqBiTree[MAX_TREE_SIZE ]
|
适于存满二叉树和完全二叉树
从数组0位开始储存
在c语言中,数组是从0开始存储的,但是我们在对二叉树编号时,是从1开始编号的,那么对于第五条性质,我们做如下改编:
- 若i>0,则i的父亲是(i+1)/2 -1,i == 0时无父亲
- 2i+1 < n,i的左孩子是2i+1,否则无孩子
- 2i +2 < n, i的右孩子是2i+2, 否则无孩子
二叉树的链式存储
代码定义:
1
2
3
4
5
6
7
| typedef struct BiTNode
{
TElemType data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
|
遍历二叉树
二叉树的遍历方式有三种,先序遍历,中序遍历,后序遍历。
先序遍历:先根,再左,后右
中序遍历:先左,再根,后右
后序遍历:先左,再右,后中
先序遍历
运用递归的思想:
截至条件:若节点为空,则空操作,直接return
- 先访问根结点
- 再遍历左字数
- 后遍历右子树
链式存储
1
2
3
4
5
6
7
8
9
10
11
| bool PreOrderTraverse(BiTree T)
{
if(T==NULL) return true;
else
{
cout<<T->data;
PreOrderTraverse(T->lchild);
PreOrderTraverse(T->rchild);
return true;
}
}
|
顺序存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| #define MAX_TREE_SIZE 100
typedef int SqBiTree[MAX_TREE_SIZE];
int PreOrderTraverse(int *SqBiTree, int i)
{
if(i >= MAX_TREE_SIZE || SqBiTree[i] == -1)
return 1;
else
{
cout << SqBiTree[i];
PreOrderTraverse(SqBiTree,i*2+1);
PreOrderTraverse(SqBiTree,i*2+2);
return 1;
}
}
|
中序遍历
运用递归的思想:
截至条件:若节点为空,则空操作,直接return
- 先遍历左子树
- 再访问根结点
- 后遍历右子树
链式存储
1
2
3
4
5
6
7
8
9
10
11
| bool InOrderTraverse(BiTree T)
{
if(T==NULL) return true;
else
{
InOrderTraverse(T->lchild);
cout<<T->data;
InOrderTraverse(T->rchild);
return true;
}
}
|
顺序存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| #define MAX_TREE_SIZE 100
typedef int SqBiTree[MAX_TREE_SIZE];
int InOrderTraverse(int *SqBiTree, int i)
{
if(i >= MAX_TREE_SIZE || SqBiTree[i] == -1)
return 1;
else
{
InOrderTraverse(SqBiTree,i*2+1);
cout << SqBiTree[i];
InOrderTraverse(SqBiTree,i*2+2);
return 1;
}
}
|
后序遍历
截至条件:若节点为空,则空操作,直接return
- 先遍历左子树
- 再访问根结点
- 后遍历右子树
链式存储
1
2
3
4
5
6
7
8
9
10
11
| bool NRPostOrder(BiTree T)
{
if(T==NULL) return true;
else
{
InOrderTraverse(T->lchild);
InOrderTraverse(T->rchild);
cout<<T->data;
return true;
}
}
|
顺序存储
1
2
3
4
5
6
7
8
9
10
11
12
| int NRPostOrder(int *SqBiTree, int i)
{
if(i >= MAX_TREE_SIZE || SqBiTree[i] == -1)
return 1;
else
{
PostOrderTraverse(SqBiTree, i*2+1);
PostOrderTraverse(SqBiTree, i*2+2);
cout << SqBiTree[i];
return 1;
}
}
|
递归遍历改非递归
改递归算法
这种方法通过栈和goto语句模拟递归的步骤,整体的程序运转方式类似递归需要对于每个进栈的元素进行标记,以便确认当前结点是第一次入栈还是第二次入栈。比较容易理解却不太方便使用。
先序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| int PreOrderTraverse(Node* t) {
stack<StackFrame> s;
InitStack(s);
L0:
if (t) {
cout << t->data;
if (t->lchild) {
push(s, t, 2);
t = t->lchild;
goto L0;
}
L2:
if (t->rchild) {
push(s, t, 3);
t = t->rchild;
goto L0;
}
}
L3:
if (!StackEmpty(s)) {
int n;
pop(s, t, n);
switch (n) {
case 2: goto L2; break;
case 3: goto L3; break;
}
}
DestroyStack(s);
return 1;
}
|
中序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| Status InOrderTraverse(BiTree T)
{
InitStack(S);
L0: if(T){
if(T->lChild){
Push(S, T, 2, f);
T = T->lChild;
goto L0;
}
L2: cout<<T->data;
if(T->rChild){
Push(S, T, 3, f);
T=T->rChild;
goto L0;
}
}
L3: if(!StackEmpty(S)){
Pop(S, T, n, f);
Switch(n){
case 2: goto L2;break;
case 3: goto L3;break;
}
}
DestroyStack(S);
return OK;
}
|
后序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| Status PostOrderTraverse(BiTree T) {
InitStack(S);
L0: if (T) {
if (T->lChild) {
Push(S, T, 2, f);
T = T->lChild;
goto L0;
}
L2: if (T->rChild) {
Push(S, T, 4, f);
T = T->rChild;
goto L0;
}
L4: cout << T->data;
}
L3: if (!StackEmpty(S)) {
Pop(S, T, n, f);
switch (n) {
case 2: goto L2; break;
case 4: goto L4; break;
}
}
DestroyStack(S);
return OK;
}
|
非递归遍历-借助栈沿着包络线走
使用该方法每个结点只需要入栈一次,因此无需对于入栈结点进行标记,比较通用:
方法:
- 沿着左子树深入到最左边,同时入栈每个元素
- 遇到nullptr则出栈一个元素,再深入出栈元素的右子树
- 知道最后从根结点的右子树返回为止(栈空)
p的运作思路:
- p == nullptr 出栈一个结点,让p 等于出栈元素右结点
- p != nullptr 则将p结点入栈,然后p = p->next
先序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| void NRPreOrder(BiTree bt)
{
BiTNode* stack[MAXNODE],p;
int top=-1;
if (bt==NULL) return;
p=bt;
while( ! (p==NULL && top==-1) )
{ while(p!=NULL)
{ Visit (p);
top++;
stack[top]=p;
p=p->lchild;
}
if (top<0) return;
else
{ p=stack[top];
top - -;
p=p->rchild;
}
}
}
|
中序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| void NRPreOrder(BiTree bt)
{
BiTNode* stack[MAXNODE], p;
int top = -1;
if (bt == NULL) return;
p = bt;
while (!(p == NULL && top == -1))
{
while (p != NULL)
{
top++;
stack[top] = p;
p = p->lchild;
}
if (top < 0) return;
else
{
p = stack[top];
top--;
Visit(p);
p = p->rchild;
}
}
}
|
后序
该思路的后序访问需要进行一些改进,因为当访问完右子树后,该结点p已经出栈,无法在找到它。所以当p出栈后我们需要将其再次保存起来。但是我们同样需要对再次入栈的p进行标记,来判断p是第一次入栈还是第二次入栈。
实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| void NRPostOrder(BiTree bt) {
BiTNode *stack[MAXNODE];
int top;
BiTNode *p;
if (bt == NULL) return;
top = -1;
p = bt;
while (!(p == NULL && top == -1))
{
while (p != NULL) {
top++;
stack[top] = p;
p = p->lchild;
}
if (top > -1) {
if (stack[top] > 0) {
p = stack[top]->rchild;
stack[top] = -stack[top];
} else {
p = -stack[top];
top--;
Visit(p);
p = NULL;
}
}
}
}
|
层序遍历
二叉树的层序遍历(也称为广度优先遍历)可以使用队列来实现。
当访问结点时的同时,将此结点入队,当一层访问结束时,通过一个一个出队来访问每个结点的左右结点。
例如:
- 访问根结点,将根结点入队
- 将根结点出队,访问根节点的左结点,同时入队,再访问根的右结点,同时入队。
- 出队根左结点,访问先后它的左右结点,同时入队。
如此入队出队,我们就可以一遍记录根结点,一遍遍历它的左右结点。
1
2
3
4
5
6
7
8
9
10
11
12
| void LevelOrderTraverse(BiTree T) {
if (T == NULL) return;
queue<BiTree> q;
q.push(T);
while (!q.empty()) {
BiTree node = q.front();
q.pop();
cout << node->data << " ";
if (node->lchild != NULL) q.push(node->lchild);
if (node->rchild != NULL) q.push(node->rchild);
}
}
|
最后的重要结论
在一个每一个结点中的值都不相等的二叉树中,由二叉树的前序和中序序列或后序序列和中序序列均能够唯一的确定一颗二叉树。
但前序和后续序列却不能唯一的确定一颗二叉树。
前序后序都为AB