计算机组成原理实验一
计算机组成原理实验一
首先使用学号和密码登录学校提供的服务器。本次实验分为三个小实验。
ssh登录
这里我们先了解一下什么是ssh登录:
SSH(Secure Shell)是一种用于在不安全网络上安全访问远程计算机的协议。它提供了加密的通信通道,确保数据传输的安全性和完整性。SSH 常用于远程登录、命令执行以及文件传输。
这里我们登录远程计算机使用的就是ssh连接远程服务器
实验内容一
创建文件
题目:
在linux环境下,编辑课件中源程序(注意程序的完整性)(包含源程序的开发环境截图),采用gcc编译该程序(要求分别采用-o和-O参数,并比较两者性能,编译指令截图),采用gdb进行调试,让程序运行到for函数语句(调试截图),运用objdump工具生成汇编程序(给出main函数的汇编程序截图)
1 | |
登录服务器后,我们首先创建一个 .c文件:
1 | |
我们就进入了vim编辑器的界面,因为原本不存在main.c文件,vim会创建一个空文件,效果如下:

这个时候我们按键盘i键,让编辑器进入插入(insert)模式,就可以编辑文件了。
创建好代码后,先按键盘 Esc键,退出插入模式,然后输入英文 :然后输入wq,屏幕左下角显示如图:

然后就可以回车,这里“w”表示保存,“q”表示离开。
gcc编译c程序
通过代码:
1 | |
就可以将.c 文件编译成可执行文件
输入 ls来查看目录下的文件:

a.out就是编译完成的可执行文件
通过代码:
1 | |
来运行程序,即可看到输出:

gcc -o 指令
-o 指令的全称是 output。它用于指定编译生成的输出文件的名称。
1 | |
就可以将main.c 编译的程序指定名称为 output
gcc -E 指令
gcc -E 选项用于仅执行预处理步骤,而不进行编译、汇编和链接。预处理器会处理宏定义、头文件包含、条件编译等预处理指令,并生成预处理后的输出。
作用
- 宏展开 :展开所有的宏定义。
- 头文件包含 :将所有包含的头文件内容插入到源文件中。
- 条件编译 :处理
#if、#ifdef、#ifndef等条件编译指令。 - 删除注释 :移除源代码中的注释
我们使用指令:
1 | |
来把main.c文件预处理并保存为main.i文件。
gcc -S 指令
gcc -S 选项用于将源代码编译成汇编代码,而不进行汇编和链接。生成的汇编代码文件通常以 .s 为扩展名。
通过代码:
1 | |
来吧代码编译成为汇编语言
我们需要注意的是这里的S为大写,s(小写)另有其作用:
gcc -S 选项用于将源代码编译成汇编代码,而不进行汇编和链接。生成的汇编代码文件通常以 .s 为扩展名。
gcc -s 选项用于在链接阶段去除可执行文件中的符号表和调试信息,从而减小文件大小。这对于发布和分发程序时非常有用,因为它可以减少可执行文件的体积。
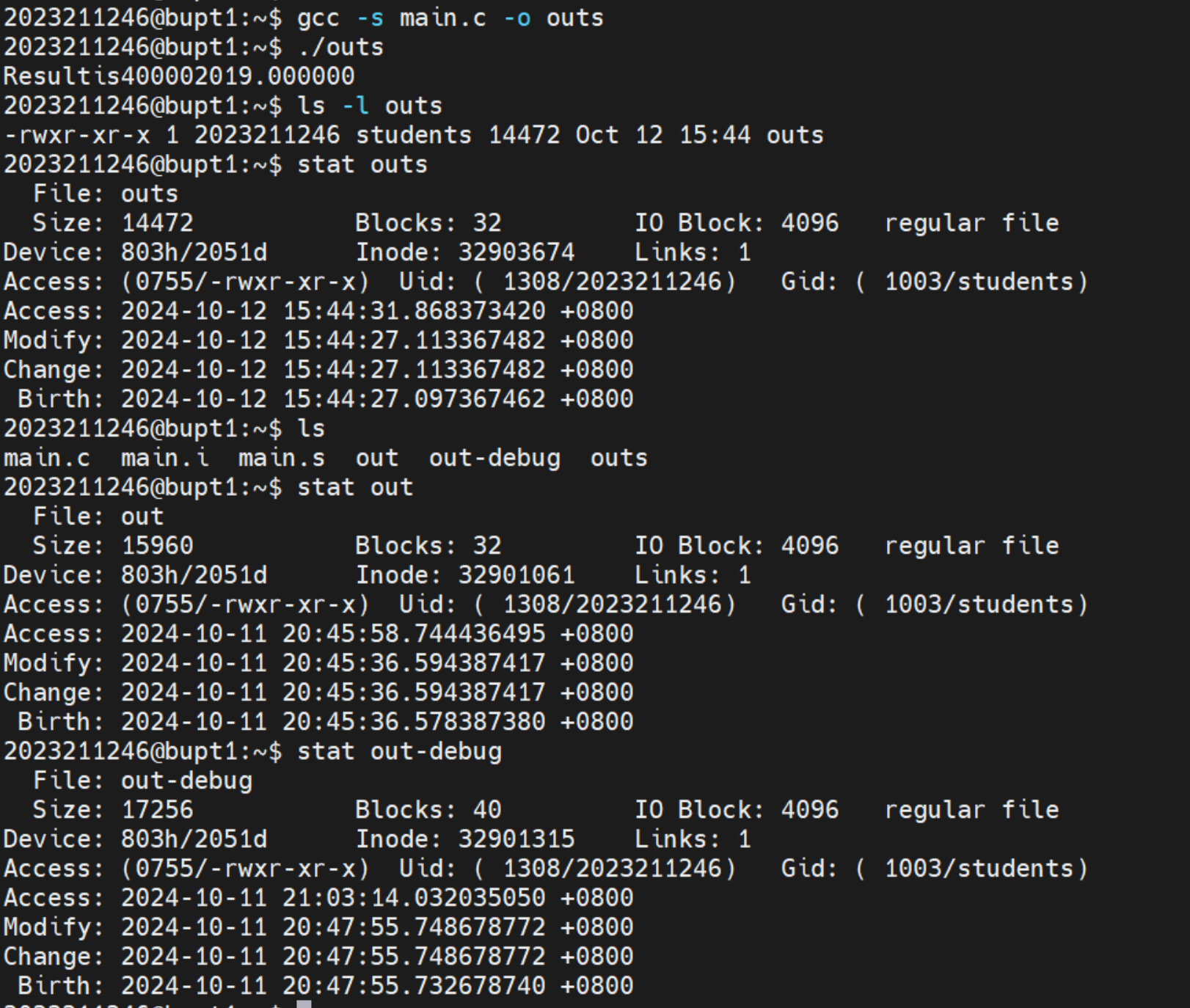
这里我们简单对比一下: -s文件体积 < -O文件体积 < -g文件体积
gcc -c 指令
gcc -c 选项用于将源代码编译成目标文件(object file),而不进行链接。生成的目标文件通常以 .o 为扩展名。
通过代码:
1 | |
将main.s编译成main.o文件
优点:
- 模块化编译 :允许将大型项目分成多个源文件分别编译,然后在最后一步进行链接。这有助于加快编译速度,因为只有修改过的源文件需要重新编译。
此时的main.o文件虽然已经为二进制编码却无法运行,因为缺少了链接操作
gcc 链接
在使用 gcc 编译程序时,链接(linking)是编译过程的最后一步。链接的主要作用是将多个目标文件(object files)和库文件(libraries)组合在一起,生成一个可执行文件。链接阶段解决了符号引用问题,使得程序可以正确运行。
假设你有两个源文件:main.c 和 utils.c 以及对应的utils.h
我们可以分别编译:
1 | |
然后再进行链接:
1 | |
即使是单个 .c 文件的程序,在编译过程中也需要链接步骤。这是因为链接步骤不仅仅是将多个目标文件组合在一起,还涉及到以下几个关键任务:
链接步骤的关键任务
- 符号解析 :即使是单个源文件,程序中也可能引用了外部库函数(如标准库函数)。链接器需要解析这些符号并将它们链接到正确的库实现中。
- 标准库链接 :大多数 C 程序都会使用标准库函数(如
printf、malloc等)。这些函数的实现位于标准库中,链接器需要将这些库函数链接到你的程序中。 - 地址重定位 :链接器会调整代码和数据的地址,以确保它们在内存中的正确位置。这对于生成可执行文件是必不可少的步骤。
- 生成可执行文件 :链接器将目标文件中的代码和数据段合并,生成最终的可执行文件。
gcc -O 优化
在编译代码时,我们可以通过一些指令让gcc产生效率更高,运行更快的代码,但是这同时会增加文件编译的时间,这就是 -O 指令:
gcc -O 选项用于优化编译生成的代码。不同的优化级别可以影响编译器如何生成更高效的代码。以下是常见的优化级别及其作用:
-O0:默认级别,不进行优化。编译速度最快,适合调试。-O1:基本优化。编译器会进行一些基本的优化,如消除冗余代码和简单的循环优化。-O2:更高级的优化。包括所有-O1的优化,并进行更多的优化,如更复杂的循环优化和内联函数。-O3:最高级别的优化。包括所有-O2的优化,并进行更激进的优化,如函数内联和代码复用。-Os:优化代码大小。类似于-O2,但会进一步优化以减少生成代码的大小。-Ofast:启用所有-O3的优化,并进行一些不严格遵守标准的优化,以提高性能。
以编译main.c为例:
1 | |
认识time工具
time 是 Linux 系统自带的工具。大多数 Linux 发行版都预装了这个工具,可以直接在终端中使用。
time 是一个命令行工具,用于测量和报告命令执行的时间。它可以显示命令执行的总时间、用户时间和系统时间。
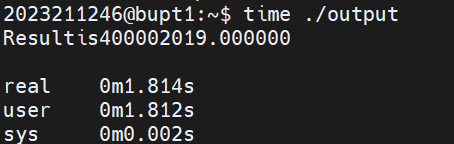
我们可以通过time 工具来比较一下优化前后的效果:
这是不优化的时间:
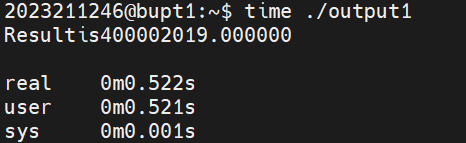
这是O1优化的时间:
这是Ofast优化的时间:
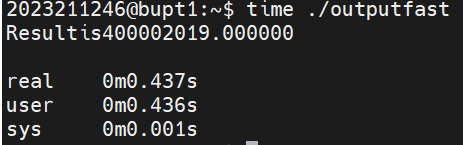
不难发现优化后的时间是原来的3倍快。
GDB介绍
GDB(GNU Debugger)是一个强大的调试工具,用于调试 C、C++ 和其他编程语言编写的程序。它允许开发人员在程序运行时检查和修改程序的内部状态,帮助定位和修复错误。
GDB 的主要功能
- 启动程序 :可以从头开始运行程序,也可以附加到正在运行的进程。
- 设置断点 :在程序的特定位置设置断点,当程序运行到该位置时暂停执行。
- 单步执行 :逐行执行程序代码,方便检查每一步的执行情况。
- 检查变量 :查看和修改程序中的变量值。
- 调用栈 :查看函数调用栈,了解程序的执行路径。
- 条件断点 :设置条件断点,当特定条件满足时暂停程序执行。
GDB调试
我们直接使用GDB来调试我们的代码:
1 | |
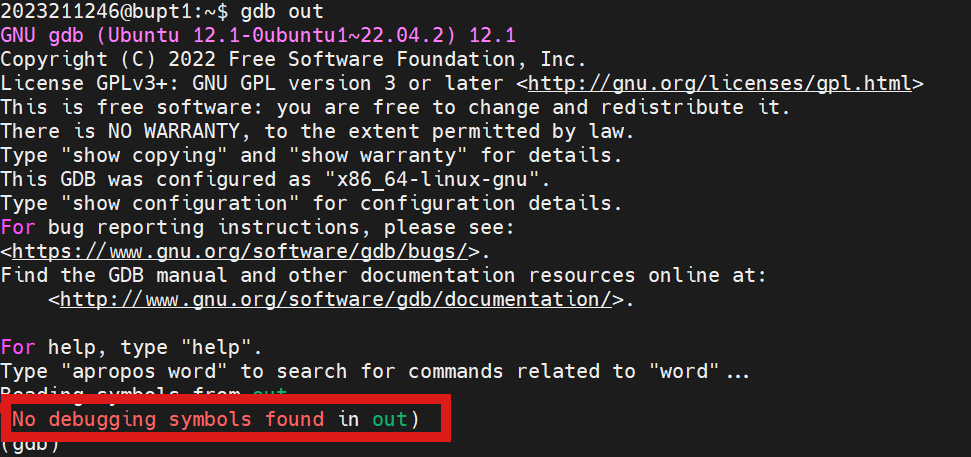
提示没有调试信息,这是因为当前运行的版本是release版本,调试需要Debug版本:
1 | |
gcc -g 选项用于在编译时生成调试信息。具体来说,-g 选项会在生成的可执行文件中包含调试符号和信息,这些信息可以被调试器(如 GDB)使用,以便在调试过程中提供源代码级别的调试功能。
GDB 指令
调试命令 (缩写) 作用
- gdb list l 显示对应的code,每次10行
再次输入会显示后面10行,但是本文件只有15行
gdb breakpoint b+行号 设置断点

我们这里在for循环处设置断点
gdb b 源文件 : 函数名 在该函数的第一行打上断点,用于多文件时对于某个文件中的函数进行调试
gdb b 源文件 : 行号 在该源文件中的这行加上一个断点,用于多文件时对于某个文件中的某一行调试
gdb d 断点的编号 删除一个断点
gdb next n 逐过程
gdb step s 逐语句
gdb print p +
<var_name>显示变量的值,可以省略变量的名称,默认显示上次查询的变量gdb run r 运行程序,若无断点会直接运行结束
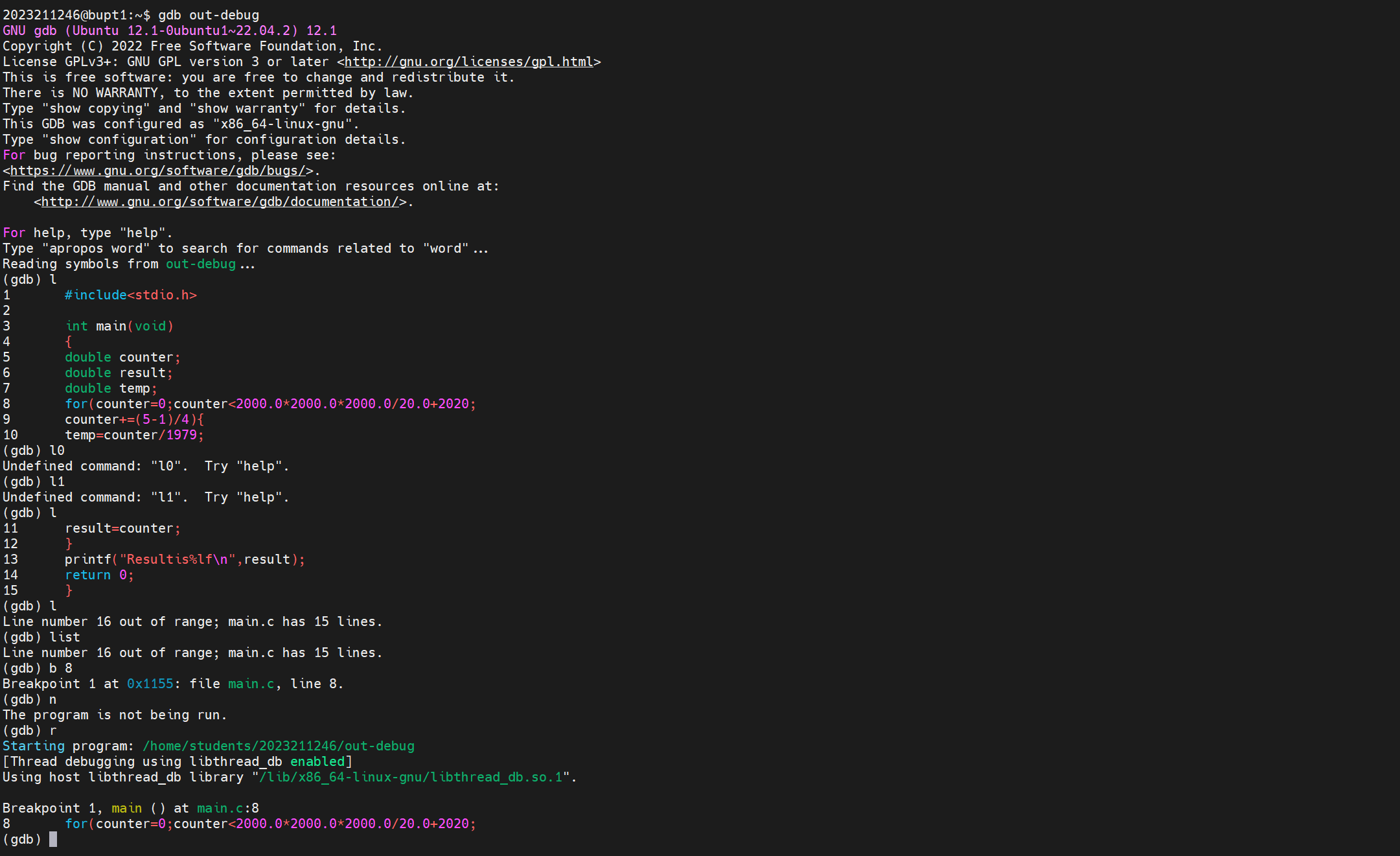
(gdb) file+
<file_name>向gdb调试工具中导入文件
objdump 工具实现反汇编
objdump 是一个强大的命令行工具,用于显示二进制文件(如目标文件、可执行文件和库文件)的详细信息。它是 GNU Binutils 工具集的一部分,广泛用于调试和分析编译生成的二进制文件。
objdump 提供了多种选项,可以显示二进制文件的不同部分和信息:
显示文件头 :
objdump -f filename
显示文件头信息,包括文件格式、目标架构等。
显示所有头信息 :
objdump -h filename
显示所有段头信息,包括段的名称、大小和地址。
反汇编代码 :
objdump -d filename
反汇编二进制文件中的代码,显示对应的汇编指令。
通过代码:就可以显示程序的汇编语言1
objdump -d out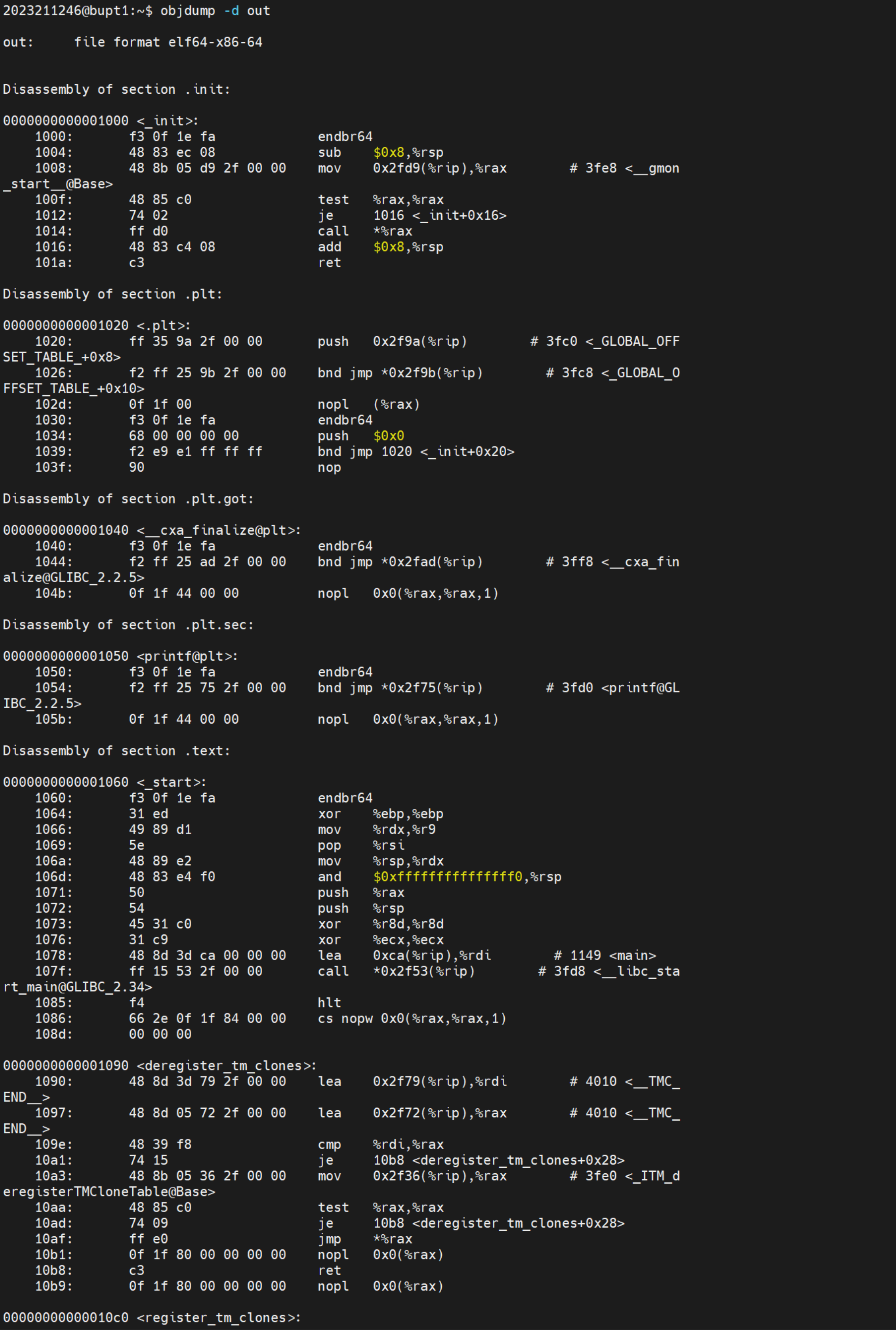
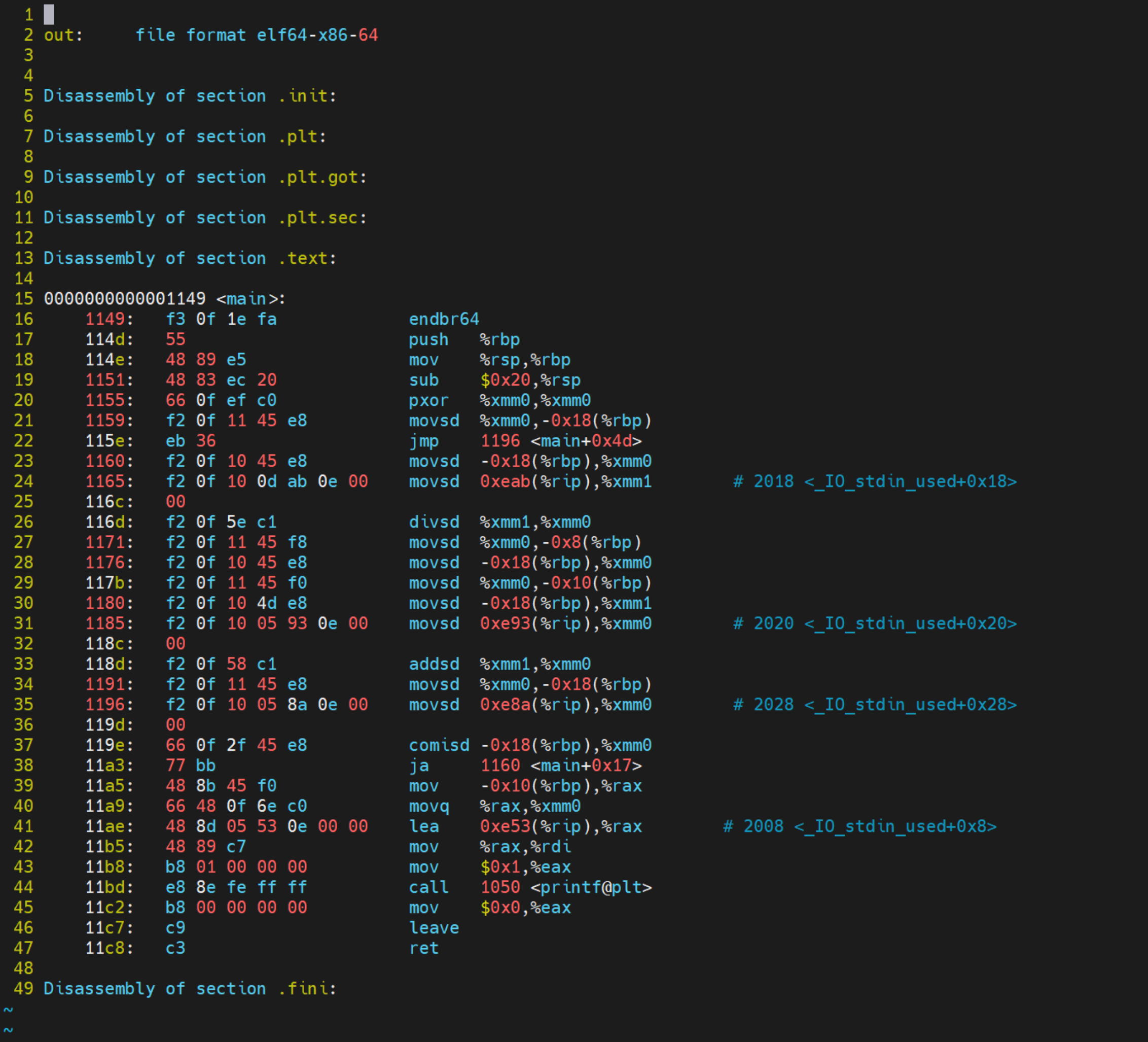
如果你只想查看特定函数的汇编语言,可以通过使用
objdump的-d选项结合--disassemble示例如下:1
objdump -d --disassemble=main out > main_.s这里我们将main函数的汇编语言存到 main_.s文件中,然后我们打开main_.s就可以查看main函数的汇编语言。
实验内容二
在linux环境下,分别打印输出如下算法所需时间
算法1:保存在test1.c中
1 | |
算法2:保存在test2.c中
1 | |
在这里关于我为什么要在数组前面加 static 是因为如果不加的话会报错:Segmentation fault
这里分析一下原因:参考博客:关于C语言开大数组溢出:内存分配问题
c语言占用的内存可以分为5个区:
- 代码区(Text Segment):不难理解,就是用于放置编译过后的代码的二进制机器码。
- 堆区(Heap):用于动态内存分配。一般由程序员分配和释放,若程序员不释放,结束程序时有可能由操作系统回收。(其实就是malloc()函数能够掌控的内存区域)
- 栈区(Stack):由编译器自动分配和释放,一般用来存放局部变量、函数参数(敲黑板划重点了!)。
- 全局初始化数据区/静态数据区(Data Segment):顾名思义,就是存放全局变量和静态变量的地方。这个区域被整个进程共享。
- 未初始化数据区(BSS):在运行时改变值。改变值(初始化)的时候,会根据它是全局变量还是局部变量,进到他们该去的区。否则会持续待在BSS里面与世无争。(待会儿会用实验来证明并感受它的存在。)
在Windows下,Data Segment的所允许的空间通常为2G,而Stack的空间只有2M,也就是210241024=2097152字节,局部变量空间顶多放得下下524288个int类型。
这里我们通过代码:
1 | |
就可以在Linux中查询我们当前设置的栈的大小:
只有8m,而创建2048*2048大小的int类型的数组需要16m的空间,这里我们干脆将数组放入Data Segment。
现在我们在不优化的情况下来对比一下两种算法的时间比较:
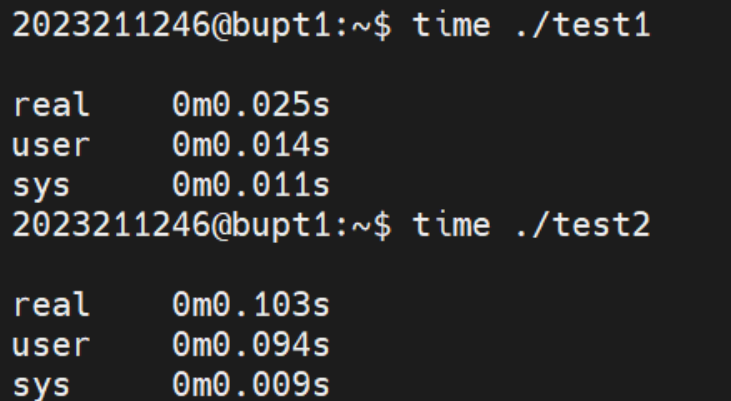
通过对比real时间我们发现看似同样的操作时间上尽然差了将近4倍。
我们再对比一下O优化后的时间:
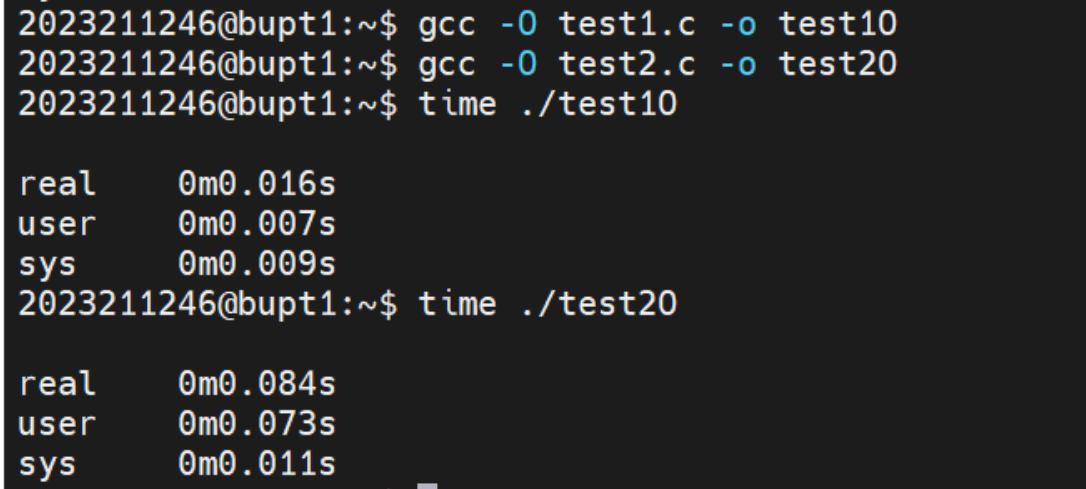
优化后,两种算法的时间倍率更大了,来到将近5倍
然后我们对比O2优化的时间:
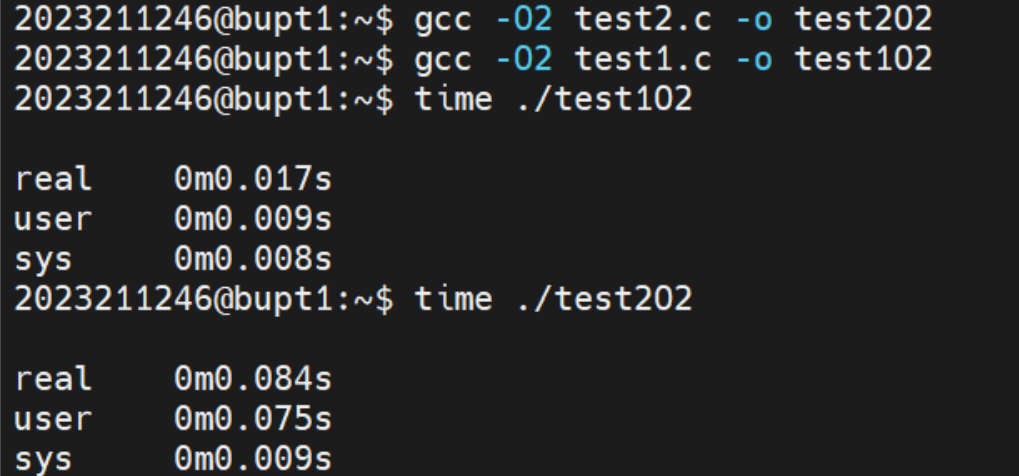
运行结果与O优化时的结果类似。
再来对比O3优化的结果:
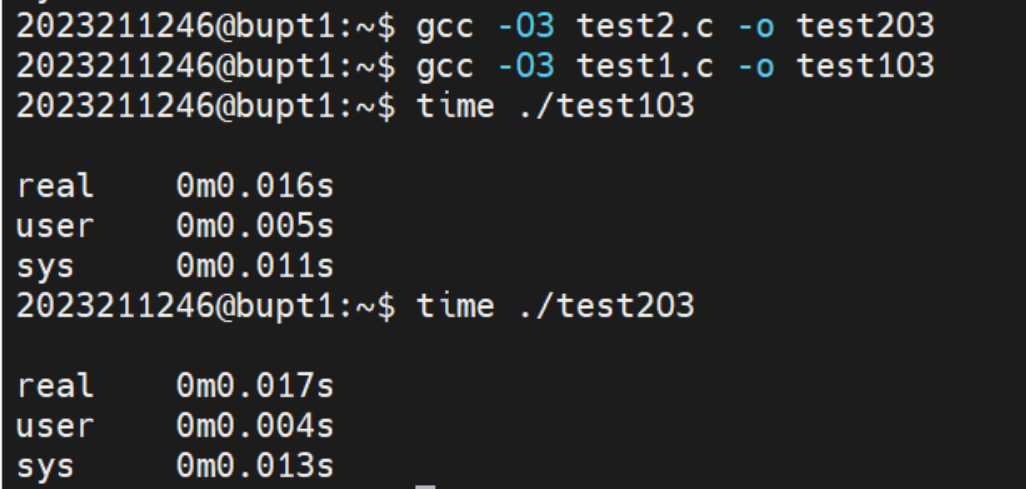
通过O3优化后,第一种算法的时间并无变化,但是第二种算法的时间大幅减少,几乎和第一种算法的时间一致。
最后我们对比一下 Ofast优化后的时间:
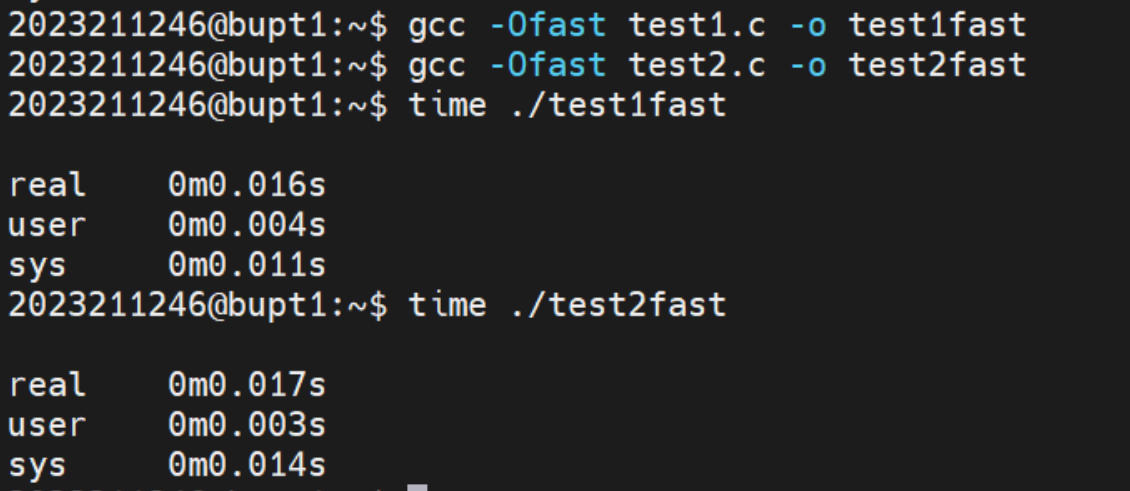
经过多次测试,发现两种算法在O2优化及更低级别的优化时,时间与O优化无差别,但是O3及Ofast优化,让两种算法时间几乎一致
在请教多种AI后,总结了以下几个方面原因:
- 指令重排 (Instruction Reordering) :在高层优化时,编译器会分析代码执行的顺序并可能对指令进行重排。虽然两种代码交换了循环的顺序,但编译器可能会将这两种形式的代码转换为相同的底层指令,从而导致它们执行时间相同。
- 缓存友好性 :虽然第一种算法在内存访问模式上更符合缓存友好性(按行访问),而第二种算法按列访问可能会导致更多的缓存未命中,但在
-O3优化级别下,编译器可能会对内存访问模式进行优化,使得两种算法的性能差异不明显。 - 循环展开 (Loop Unrolling):在 -O3 优化下,GCC 会自动进行循环展开,减少循环的迭代次数,增加每次迭代处理的数据量,从而隐藏了循环本身的开销。
实验内容三
现有两个int型数组a[i]=i-50,b[i]=i+y,其中y取自于学生本人学号2022211x*y的个位。登录bupt1服务器,在linux环境下使用vi编辑器编写C语言源程序,完成数组a+b的功能,规定数组长度为100,函数名为madd(),数组a,b均定义在函数内,采用gcc编译该程序(使用-g -fno-pie -fno-stack-protector选项),
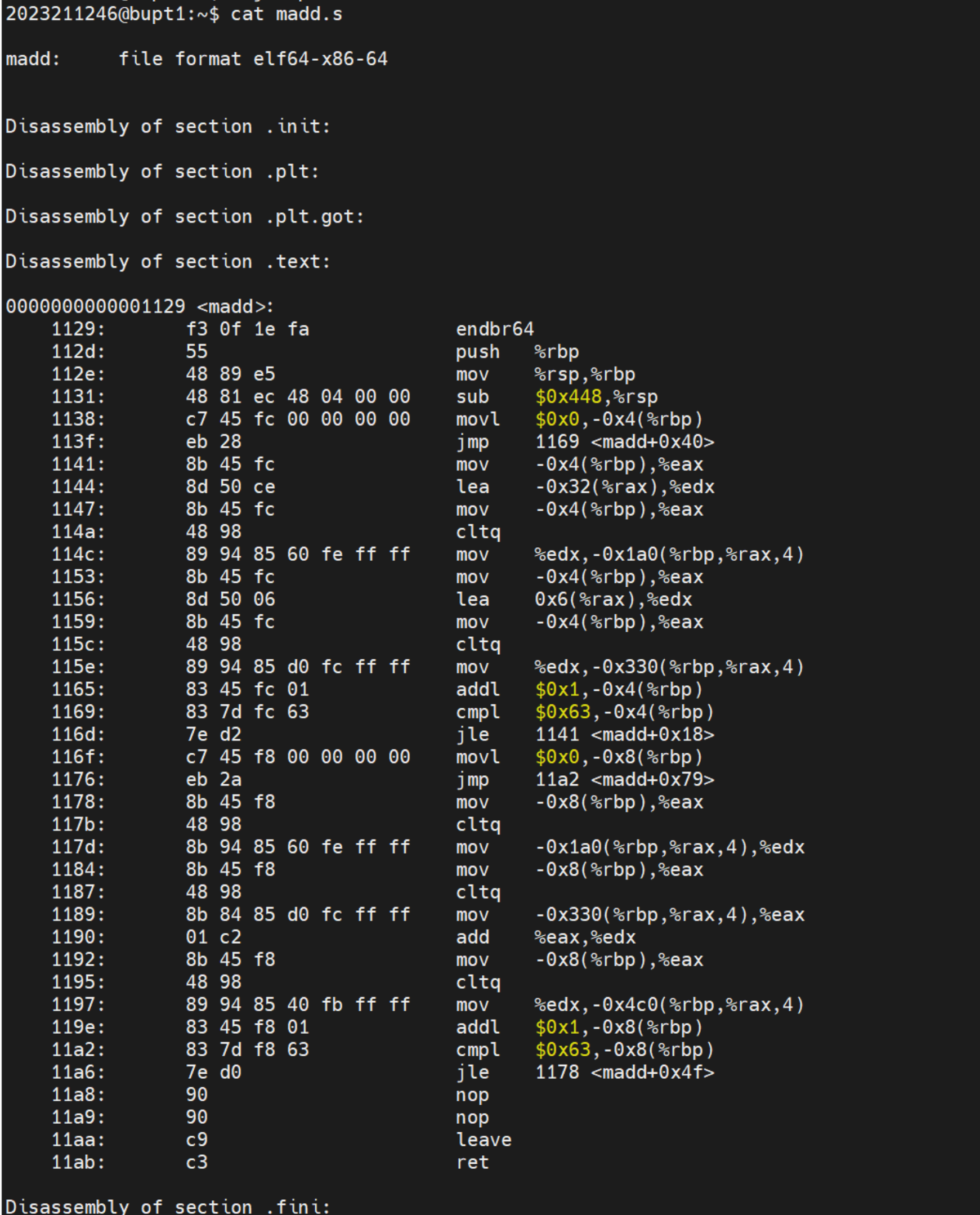
- 使用objdump工具生成汇编程序,找到madd函数的汇编程序,给出截图;
- 用gdb进行调试,练习下列gdb命令,给出截图;
gdb、file、kill、quit、break、delete、clear、info break、run、continue、nexti、stepi、disassemble、list、print、x、info reg、watch- 找到a[i]+b[i]对应的汇编指令,指出a[i]和b[i]位于哪个寄存器中,给出截图;
- 使用单步指令及gdb相关命令,显示a[xy]+b[xy]对应的汇编指令执行前后操作数寄存器十进制和十六进制的值,其中x,y取自于学生本人学号2022211x*y的百位和个位。
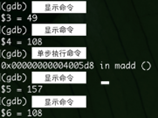
学号2022211999,a[99]+b[99]单步执行前后的参考截图如下(实际命令未显示出):
首先我们写出要求的程序madd.c:
1 | |
然后我们看看要求的编译选项分别是什么意思:gcc -g -fno-pie -fno-stack-protector
-g:- 解释 :生成调试信息。
- 作用 :在编译过程中生成调试信息,使得调试器(如
gdb)可以使用这些信息来调试程序。
-fno-pie:- 解释 :禁用生成位置无关可执行文件(PIE)。
- 作用 :生成的可执行文件将不再是位置无关的,这意味着它们将在固定的地址运行。这在某些情况下可以简化调试和性能分析。
-fno-stack-protector:- 解释 :禁用栈保护。
- 作用 :编译器不会插入额外的代码来检测栈溢出攻击。这可能会使程序更容易受到某些类型的攻击,但在调试和性能测试时可能会有用。
使用objdump工具生成汇编程序,找到madd函数的汇编程序,给出截图
使用指令:
1 | |
用gdb进行调试,练习下列gdb命令,给出截图
gdb、file、kill、quit、break、delete、clear、info break、run、continue、nexti、stepi、disassemble、list、print、x、info reg、watch
gdb 启动调试工具
file +
<file_name>像gdb中导入文件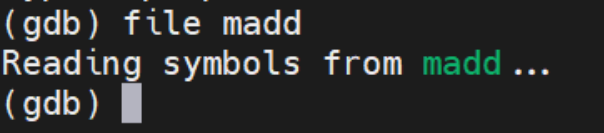
list 显示导入文件的code,每次10行
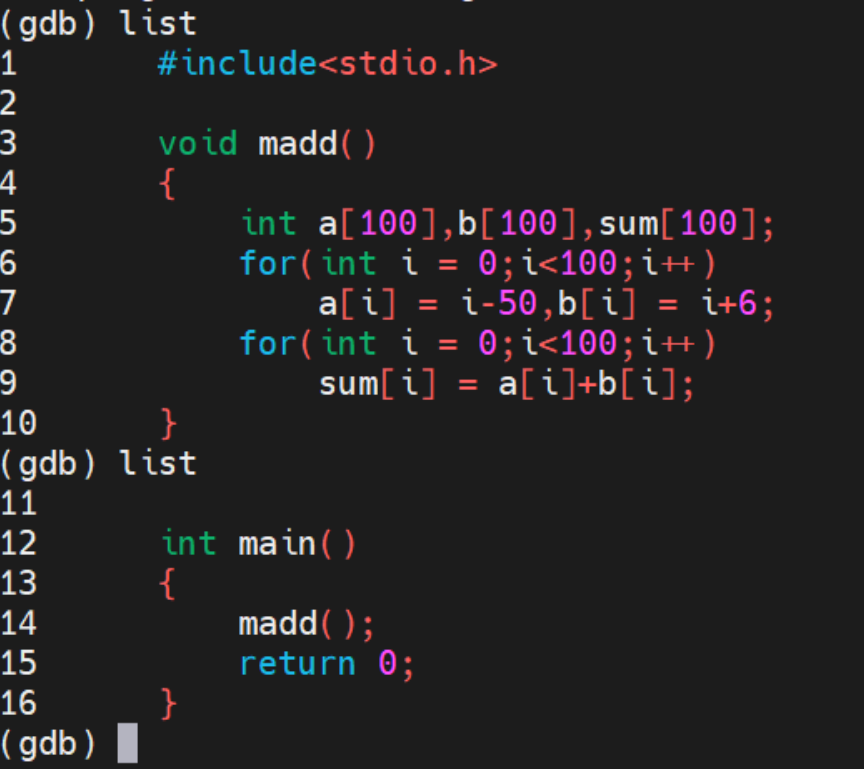
break 设置断点:我们在程序的6行设置断点

info break 查看断点的信息:

delete +断点编号 删除断点:删除断点后再查看断点信息,显示无断点

clear+断点位置 删除断点

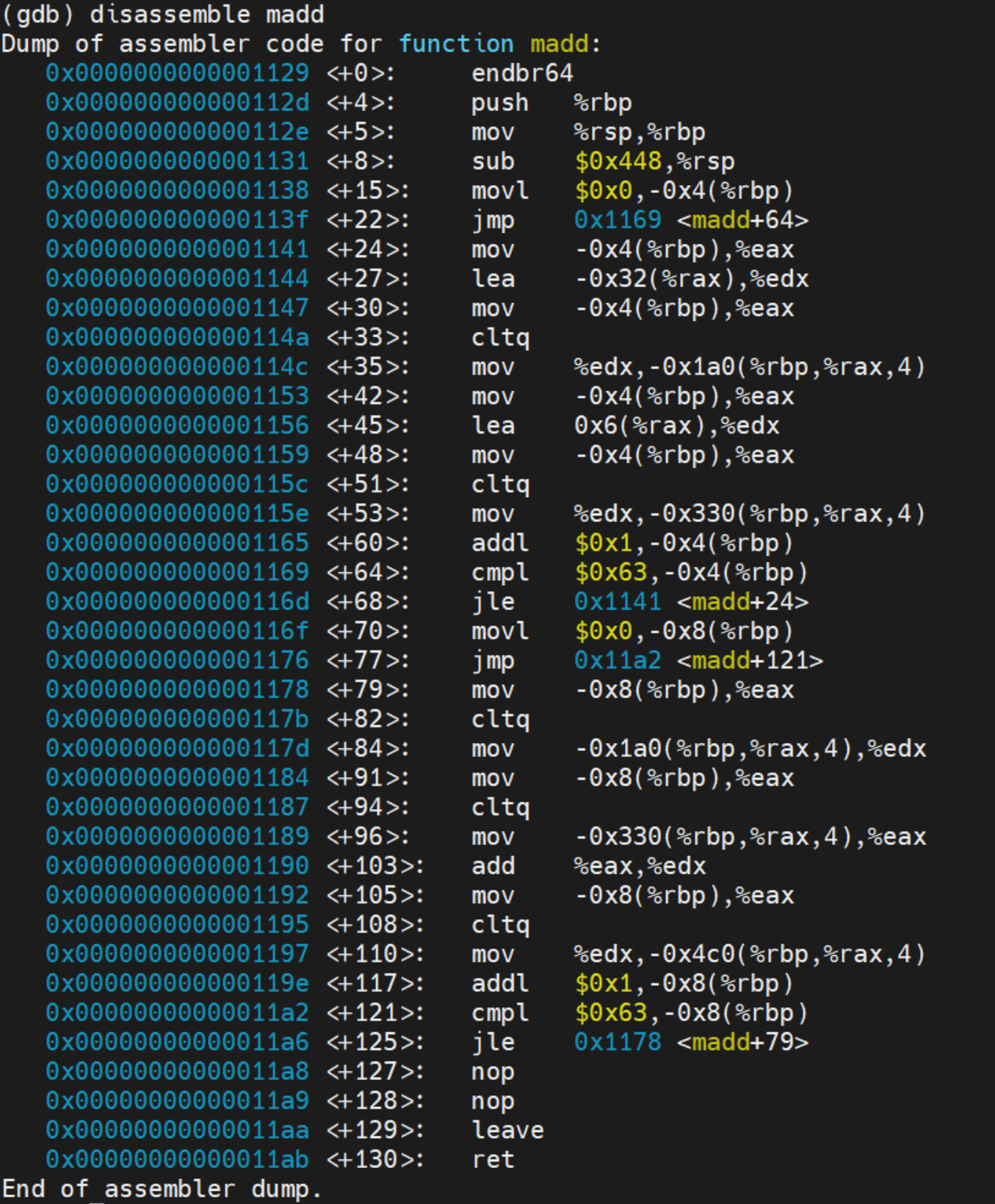
disassemble 反汇编指定函数或内存地址范围内的机器代码
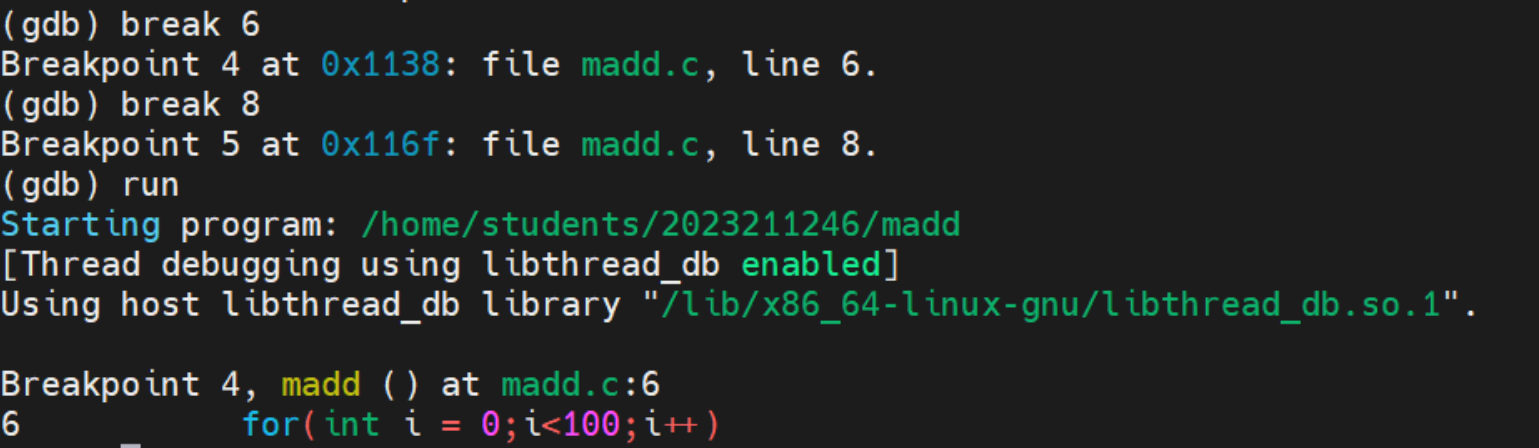
run 让程序开始运行,程序将停止在断点处
nexti 单步执行一条机器指令,并跳过函数调用
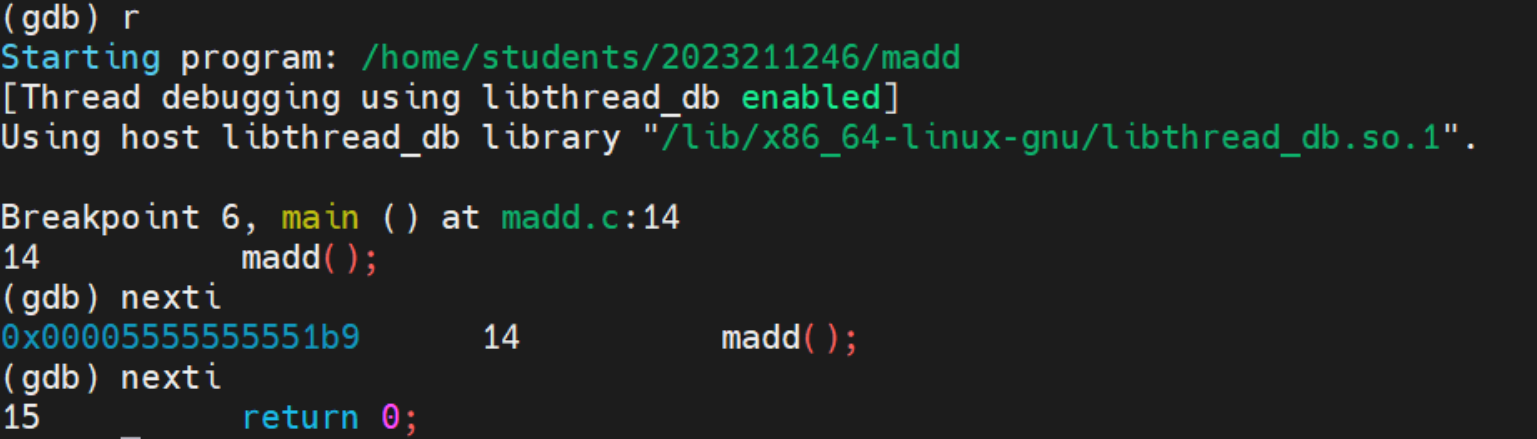
我们注意到这里nexti跳过了函数madd()内部的指令,而是直接执行整个函数调用并暂停在函数返回后的下一条指令处。
stepi命令用于在 GDB 中单步执行一条机器指令。与nexti命令不同,stepi会进入函数调用内部,而不是跳过它。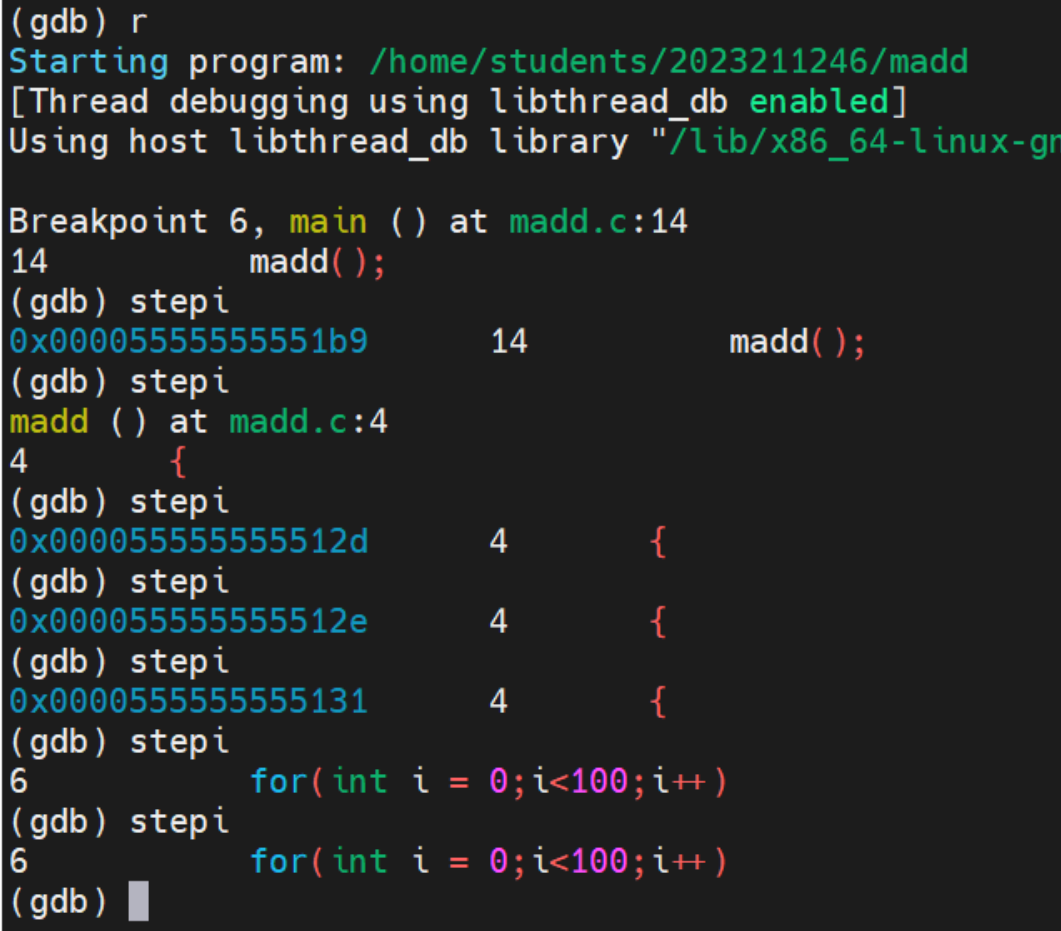
continue 命令用于在 GDB 中继续执行程序,直到遇到下一个断点
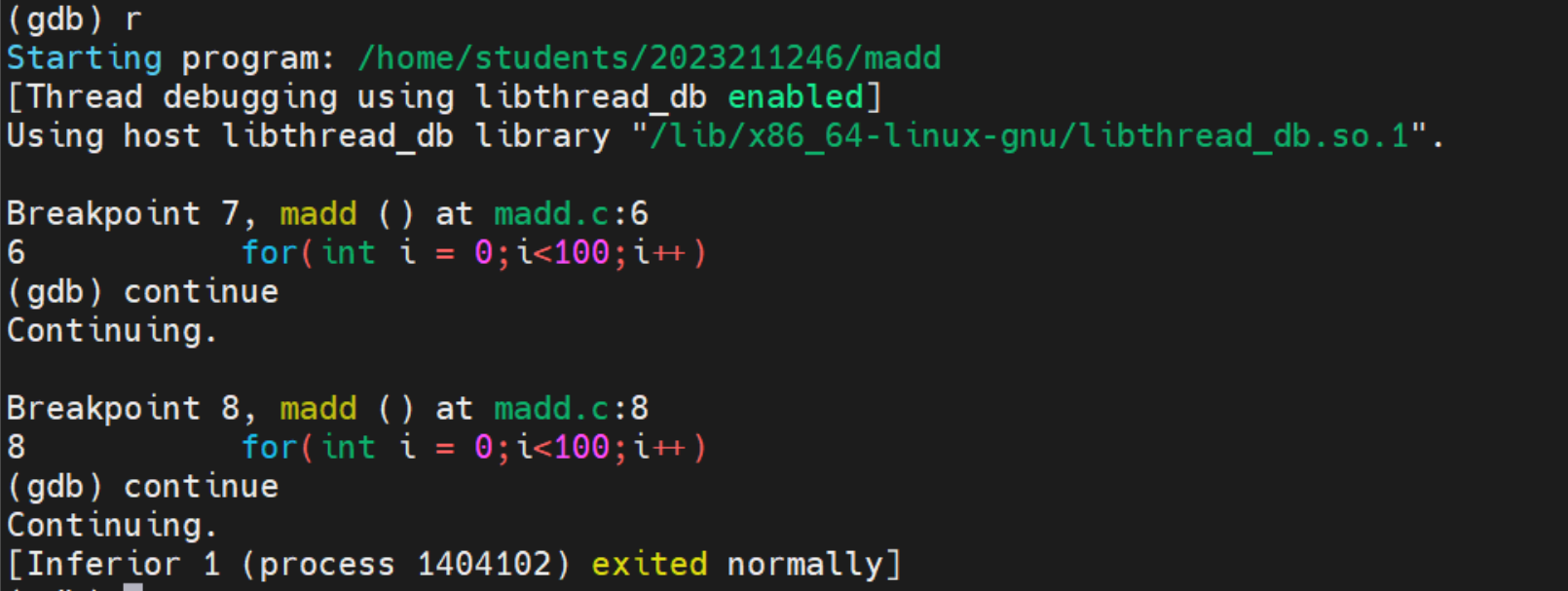
我们在6行和8行设置断点,程序只用两个continue就运行结束了
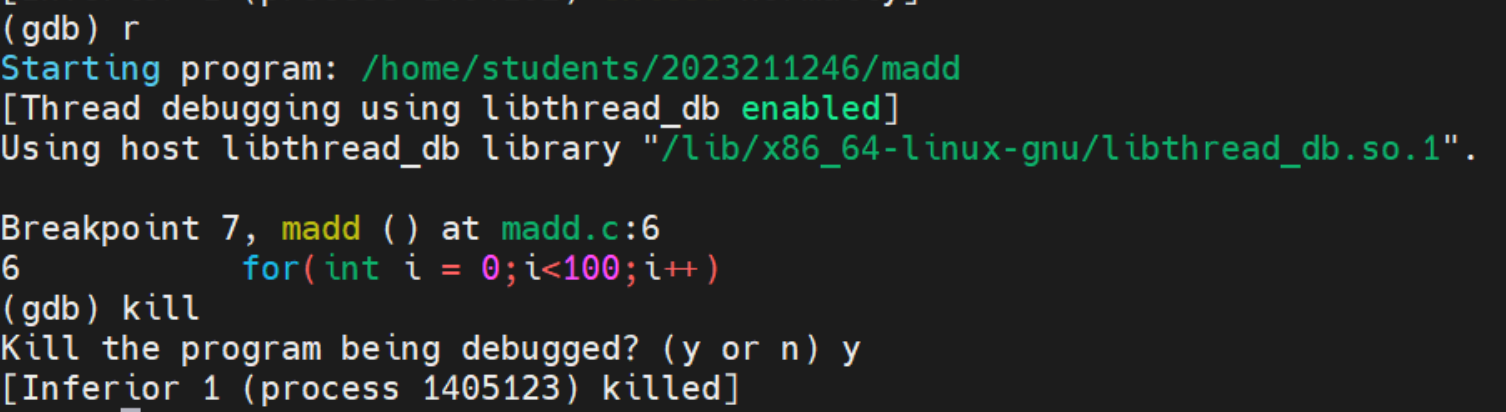
kill 用于杀死当前正在调试的程序
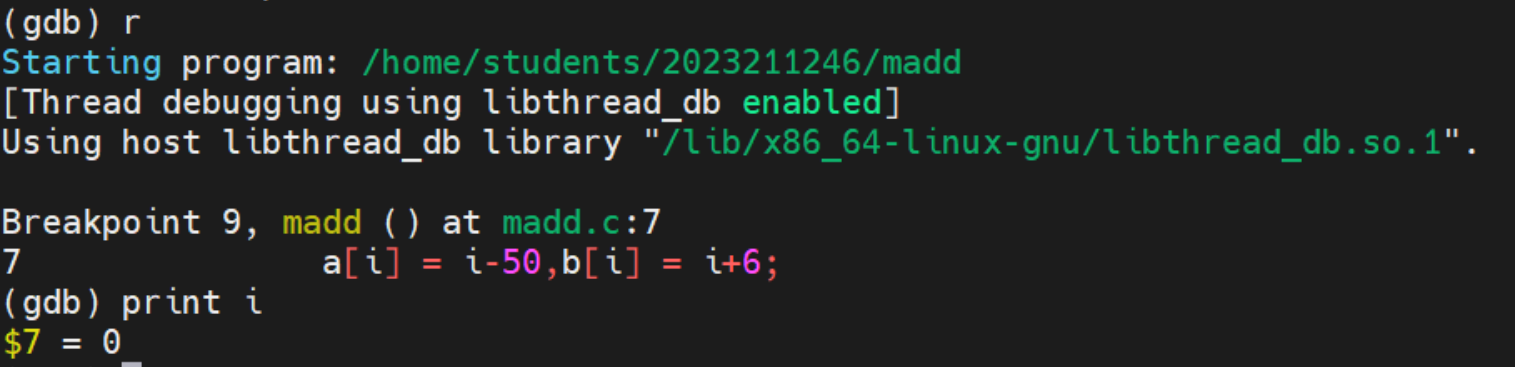
print 程序变量的值:
x 显示指定内存地址处的数据
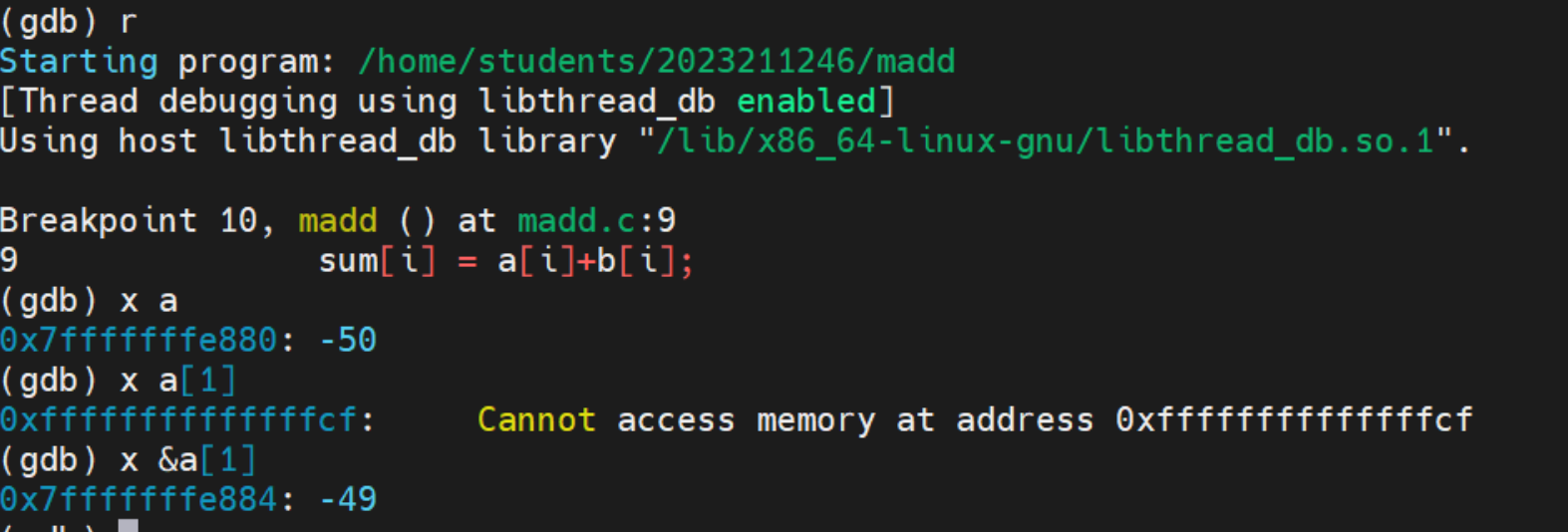
info reg : 命令用于在 GDB 中显示所有寄存器的当前值。
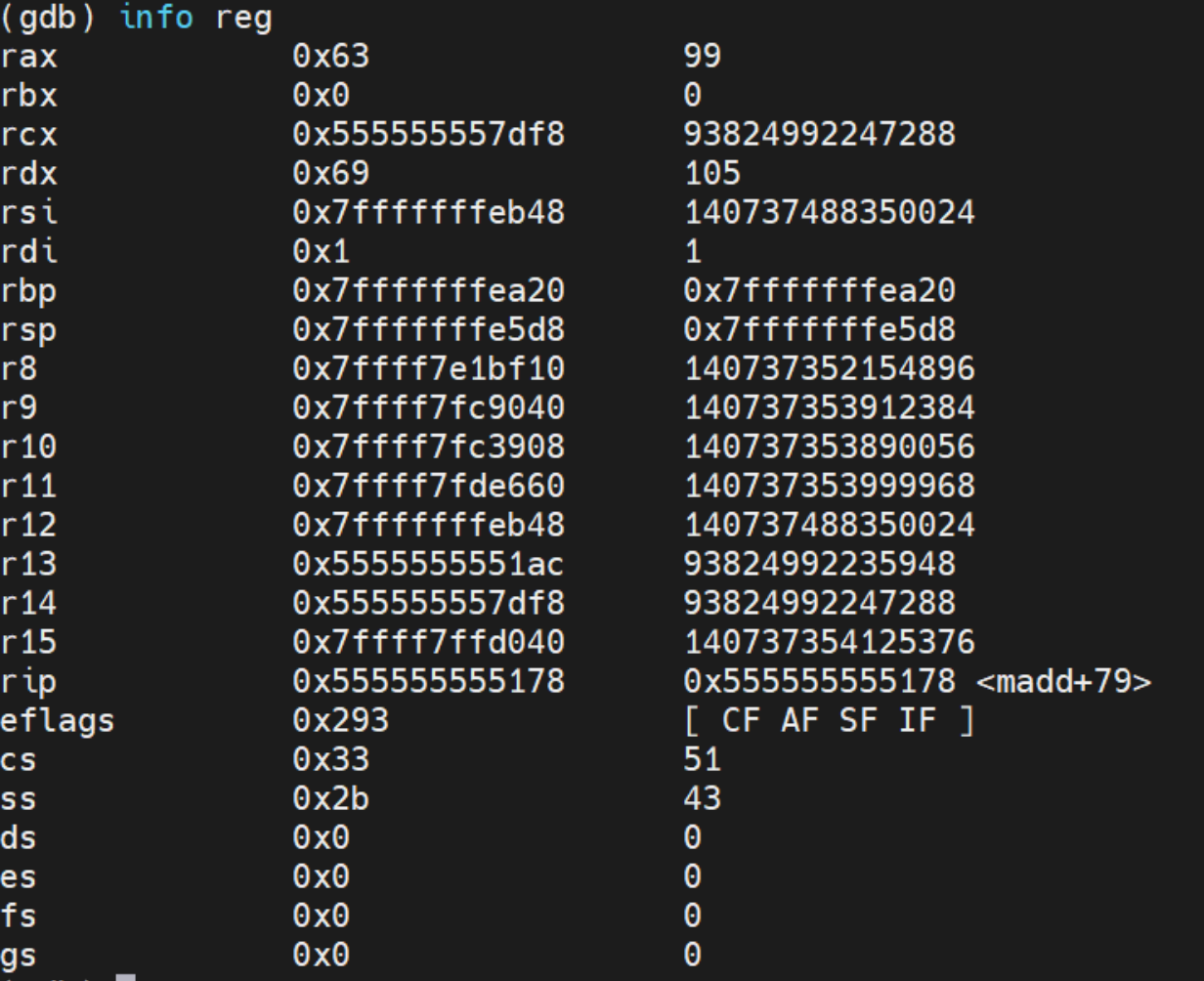
watch:用于在程序运行时监视特定变量或内存位置的变化。当被监视的变量或内存位置的值发生变化时,程序会暂停执行,并显示相关信息。
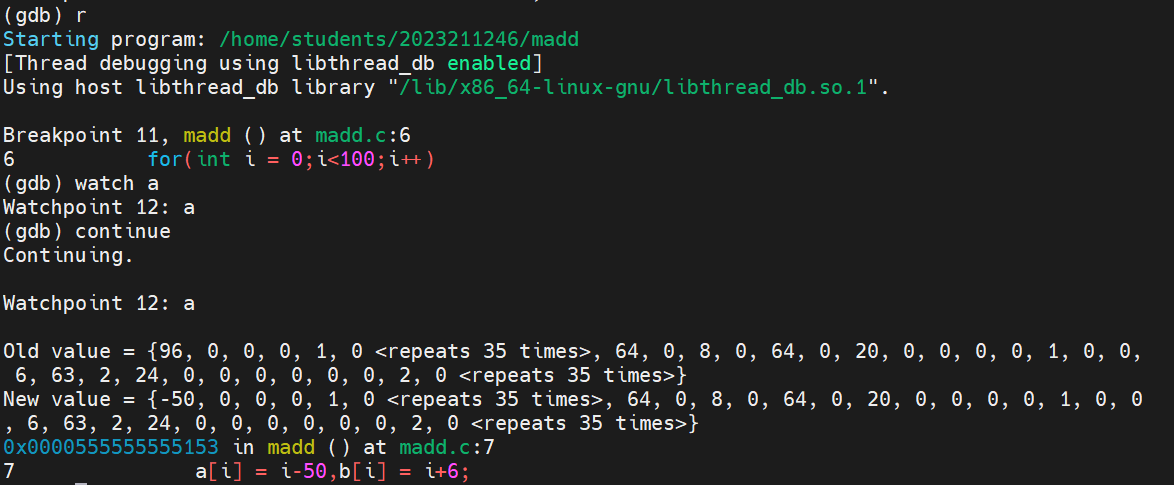
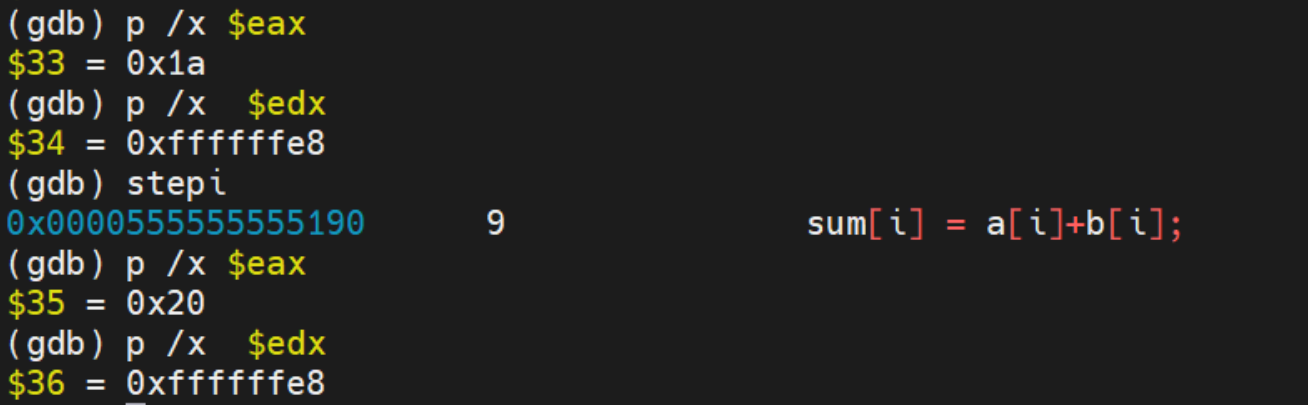
找到a[i]+b[i]对应的汇编指令,指出a[i]和b[i]位于哪个寄存器中,给出截图
要找到a[i] + b[i] 所对应的汇编指令,我们可以通过gdb在程序的 sum = a[i] + b[i]这一行添加断点,再通过 disassemble 指令查看对应的汇编指令。
发现这句话的第一条汇编指令为红色框出
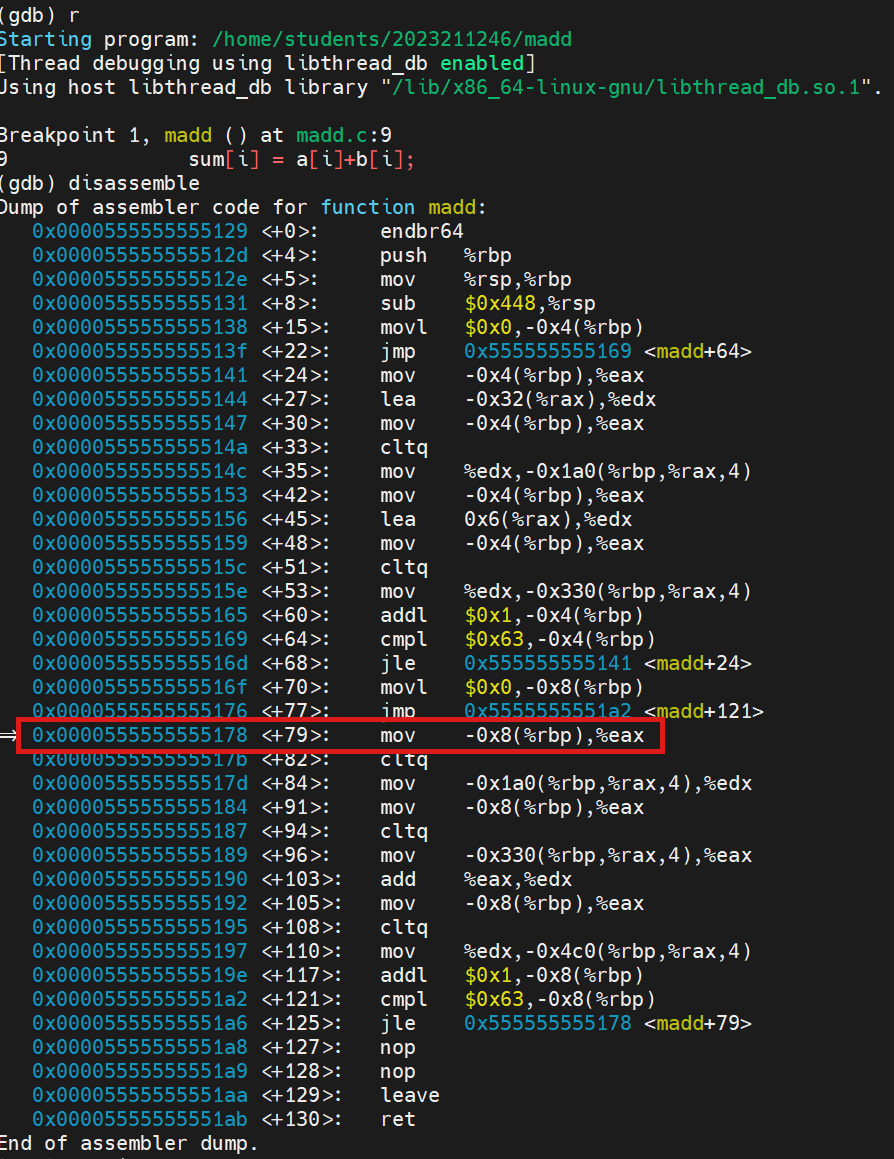
逐步通过stepi 执行汇编语言,找到最后一条汇编语言:
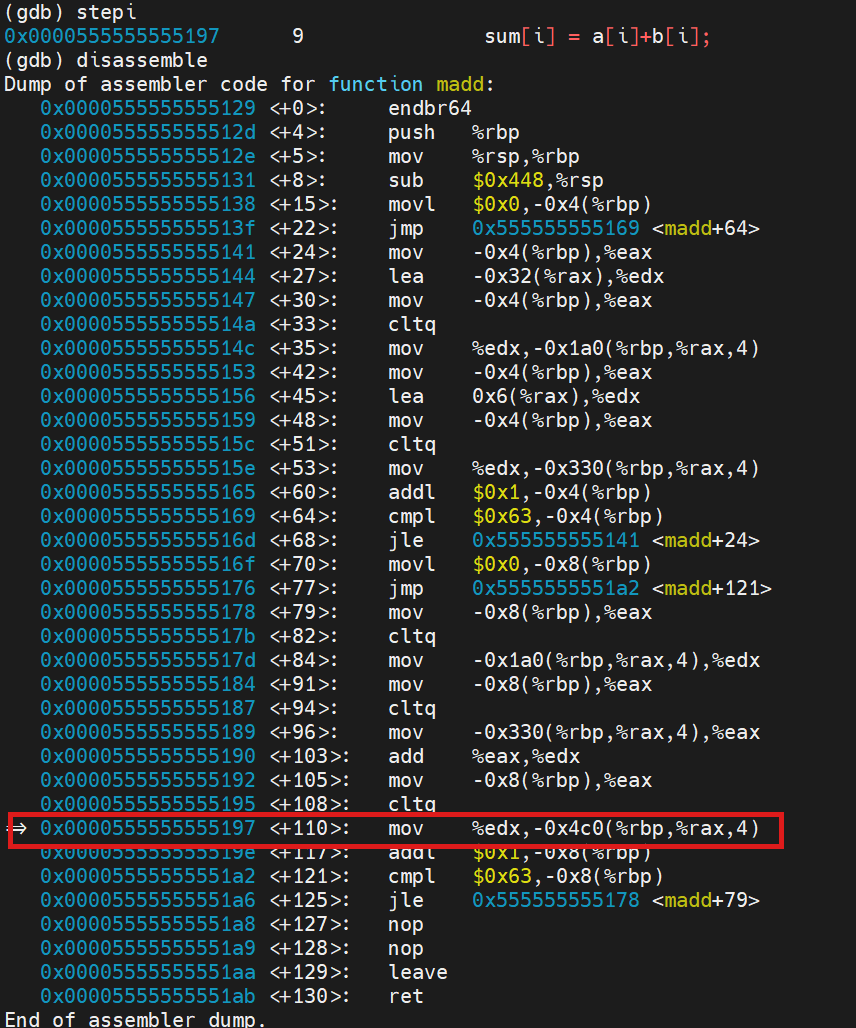
我们在这两条语句之间发现唯一一处add语句,对应的寄存器为:eax和edx。所以a和b就储存在edx和eax寄存器中。
1、使用单步指令及gdb相关命令,显示a[xy]+b[xy]对应的汇编指令执行前后操作数寄存器十进制和十六进制的值,其中x,y取自于学生本人学号2022211x*y的百位和个位。
学号2022211999,a[99]+b[99]单步执行前后的参考截图如下(实际命令未显示出):
以我的学号来说,x = 2, y = 6。即显示a[26]+b[26]:
我们通过代码定位到 a[26]+b[26]
1 | |
10进制
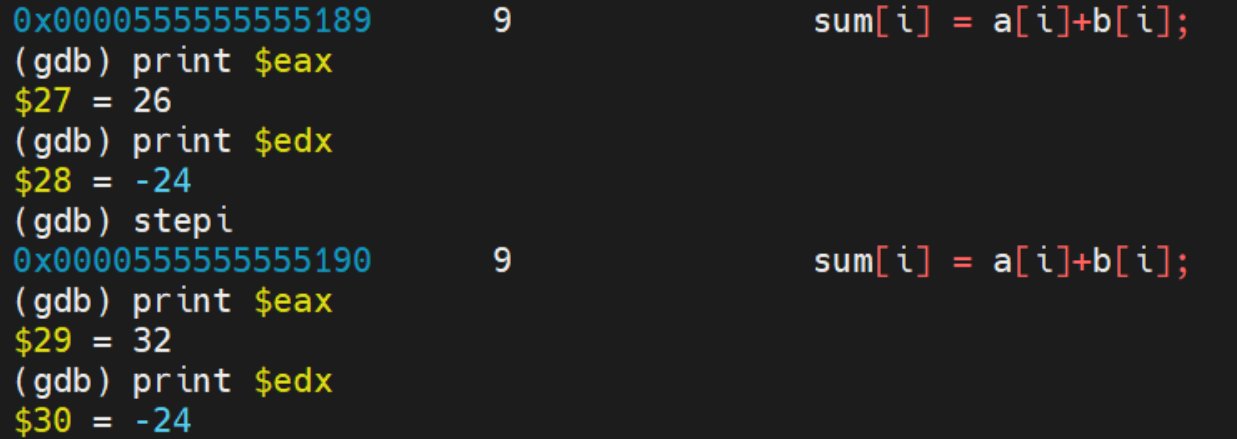
16进制:
实验内容四
任选高复杂度算法(具体算法自选,类型分为高计算量类型和高内存需求类型2类算法),通过设置不同优化参数,分析算法的运行效率
首先我们来设计一种高计算量的算法:
1 | |
我们分别采用
- 不优化
- -O优化
- -O2优化
- -O3优化
- -Ofast优化
来编译运行我们的程序,不同优化级别下运行时间如下:
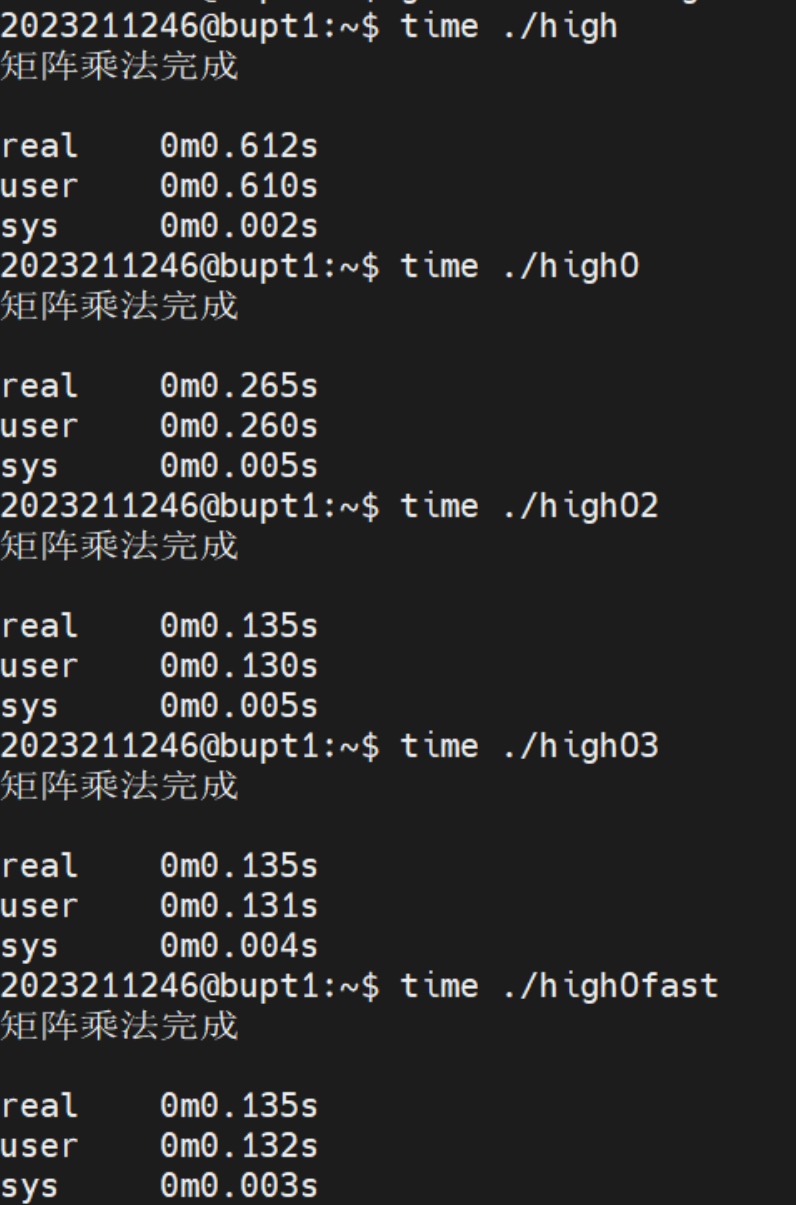
我们以未优化时的运行效率为基准,那么O优化的运行效率为230%,O2的效率为453%,O3和Ofast的运行效率与O2差不多。
然后我们使用高内存算法:
1 | |
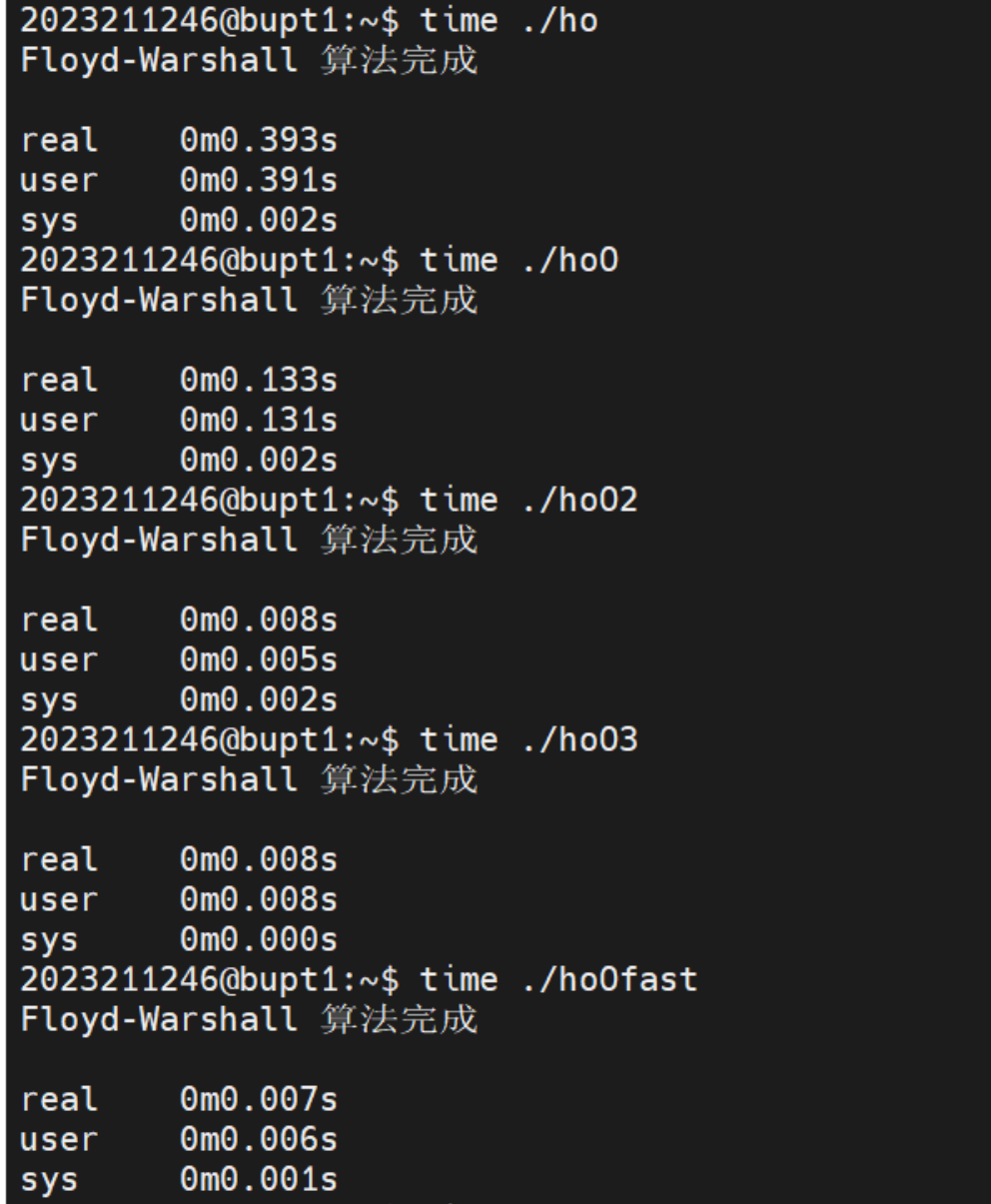
得到对应优化时间如下,结果与高计算量的优化结果大差不差。
但是我将V的值从500 改为2048,进一步增加数据量时,却出现了如下让我意外的结果:
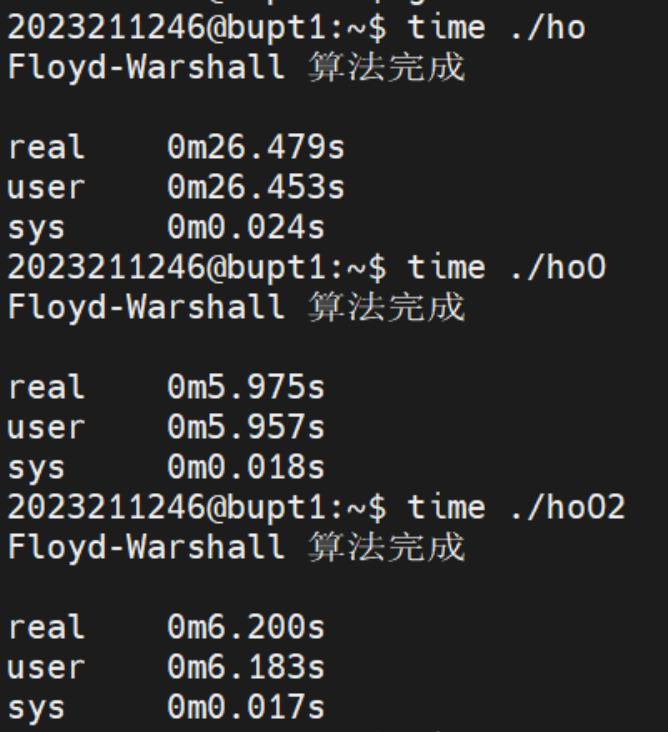
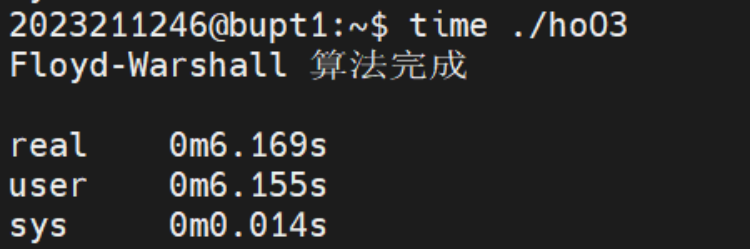
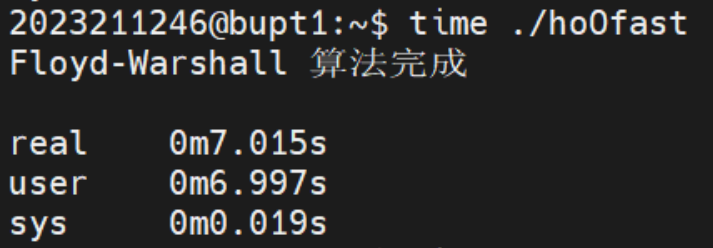
这次在一系列的优化结果中O优化尽然比O2,O3,Ofast优化都快,而且O2,O3 也比Ofast快。推测是更高级别优化中的某些选项产生了负优化的效果。我们从O开始再手动添加一些优化选项:

我们为-O 添加循环展开,适配本地cpu特性,O时间又减少了约0.7秒。
我们可以通过PGO来减少高级优化中的负优化选项。
Profile-Guided Optimization
使用pgo 的选项为:-fprofile-generate / -fprofile-use ,先使用 -fprofile-generate 生成程序运行时的性能数据文件,运行程序后再使用 -fprofile-use 进行编译。这种方法能显著提升程序的性能,特别是对于执行路径复杂、分支多的程序。
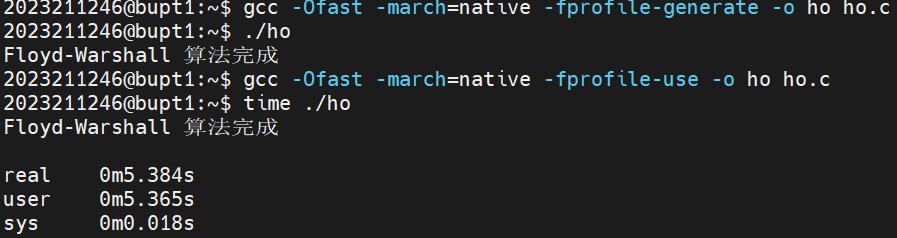
首先使用代码,来生成会收集运行数据的程序:
1 | |
然后我们执行代码:./my_program
最后再结合生成的运行数据来优化:
1 | |
然后我们测试结果如下:
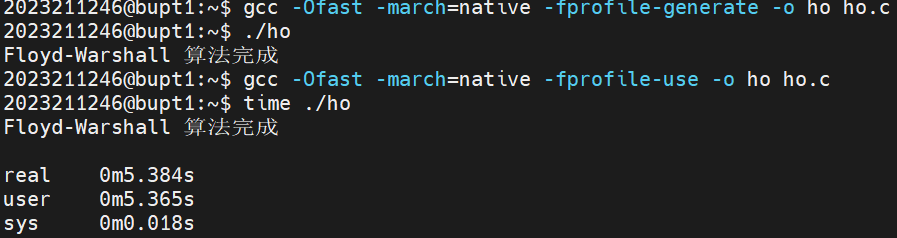
相比直接使用ofast 优化,结合PGO,Ofast的速度快了近1.7秒。速度是原来的170%